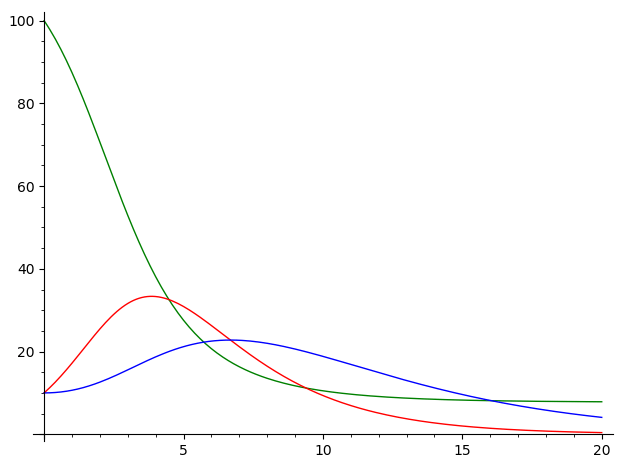
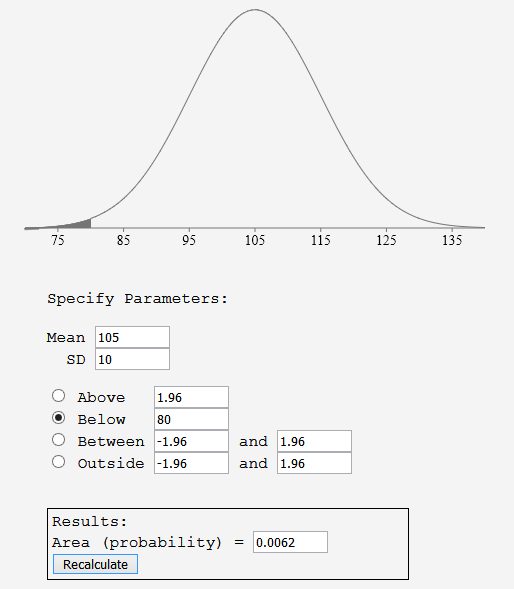
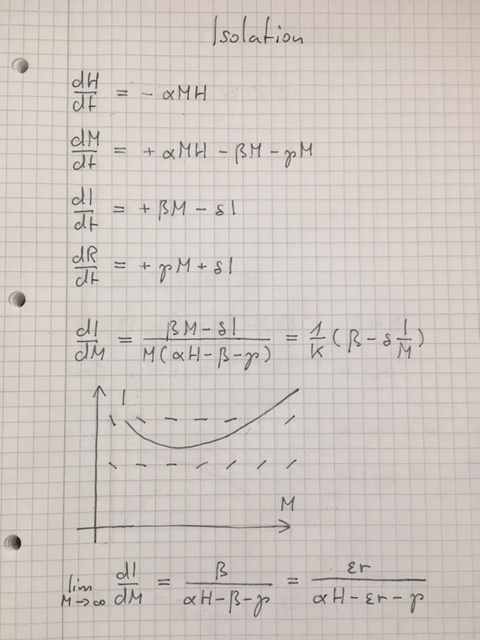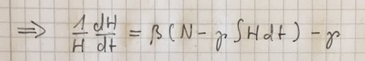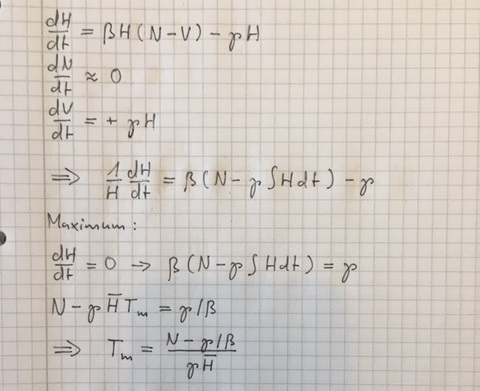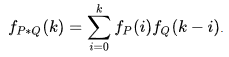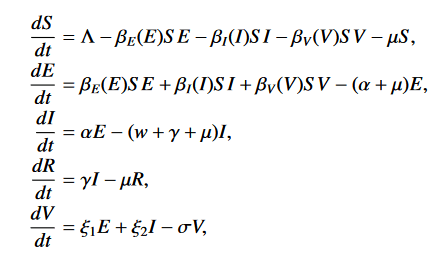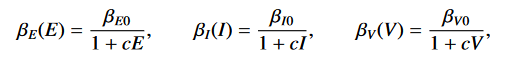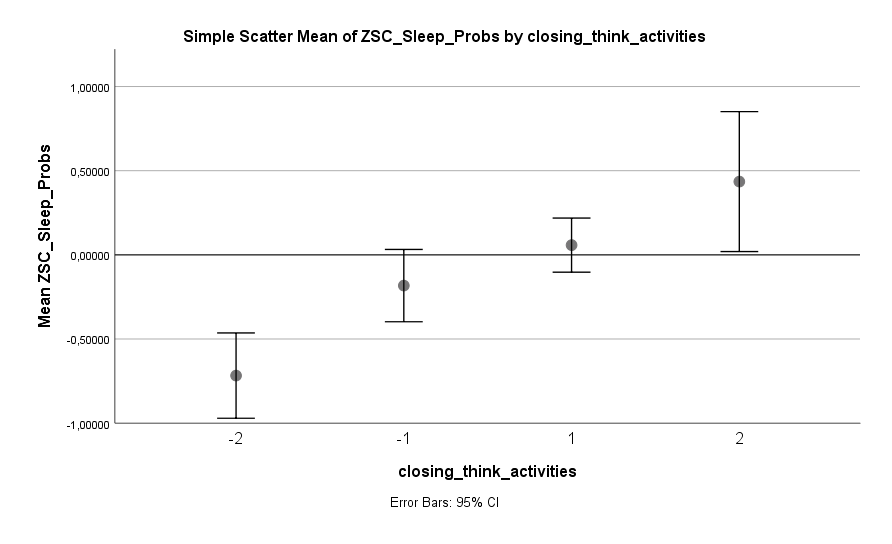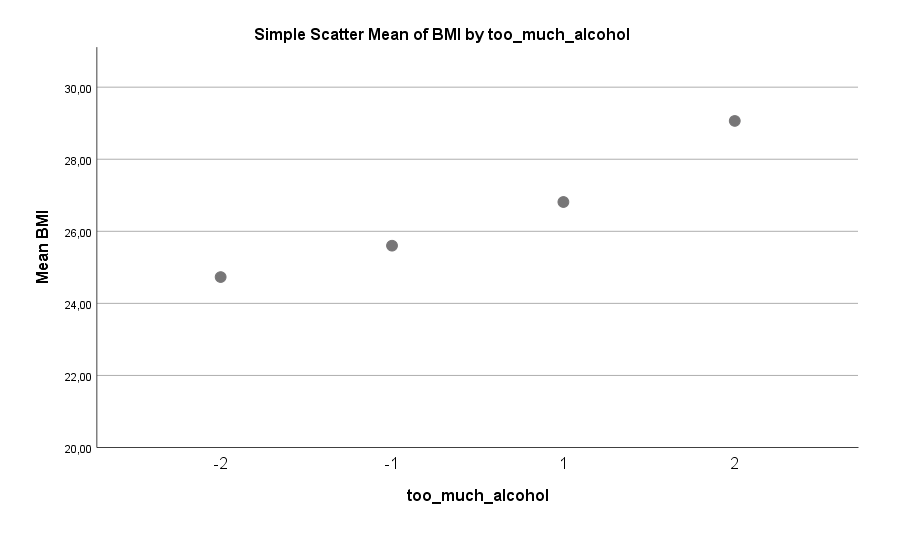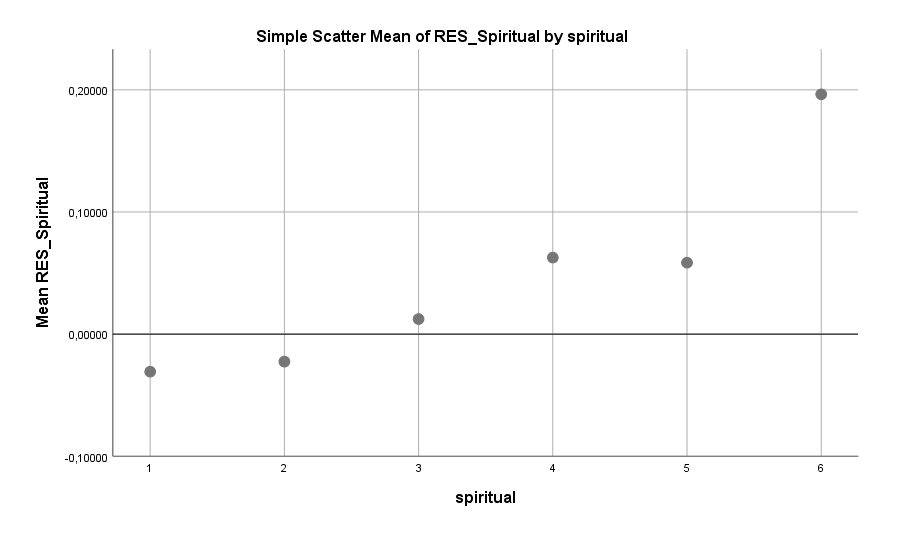Das Standard-SIR-Modell lässt sich leicht erweitern (siehe unten), um zu berücksichtigen das ein Teil der Infizierten isoliert wird. Wie strikt isoliert wird, hat einen sehr deutlichen Effekt auf a) die Belastung des Gesundheitswesens und b) der schlussendlichen Infektionsrate. Hier einmal der Verlauf, wenn Tests & Isolierung nur ungenügend betrieben werden (z.B. das Verlassen auf Selbstisolierung). Grün sind die Nie-Infizierten, Rot die nicht-isolierten Infizierten und Blau die isolierten Infizierten.
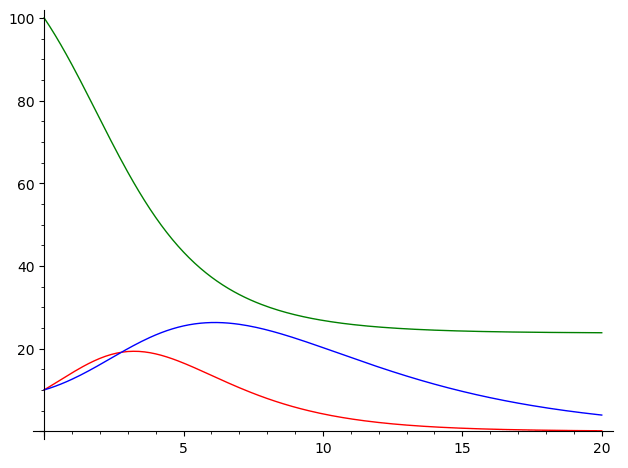
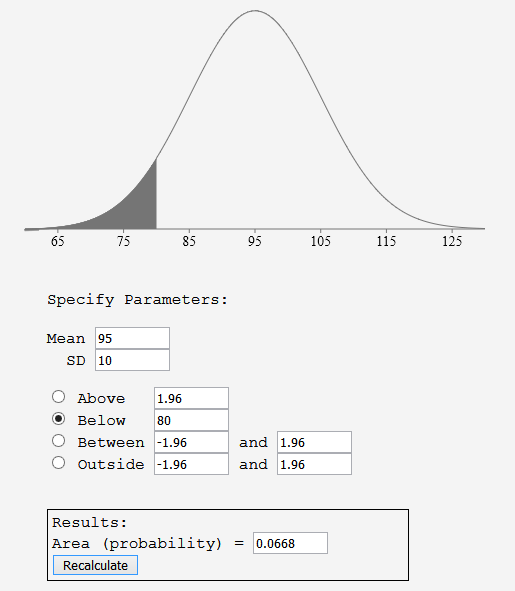
Bei strengerer Isolierung der Infizierten ergibt sich, wieder beginnend mit den Werten H = 100, M = I = 10, der folgende Verlauf:
Die Belastung des Gesundheitwesens kann man an der maximalen Steigung der Kurven erkennen. Mit ungenügender Isolierung beträgt die Abnahme der Nie-Infizierten in den ersten fünf Zeiteinheiten etwa 15 Einheiten pro Zeiteinheit, während bei strengerer Isolierung dieser Wert auf 11 Einheiten pro Zeiteinheit abnimmt. In der Praxis kann das den Unterschied zwischen funktionierender Pflege und der Notwendigkeit von Triage ausmachen. Man sieht auch, dass bei ungenügender Isolierung ein Virus auch sehr schnell fast die gesamte Population durchläuft, während sich durch Isolierung ein klar von Null verschiedenes Plateau einstellen kann.
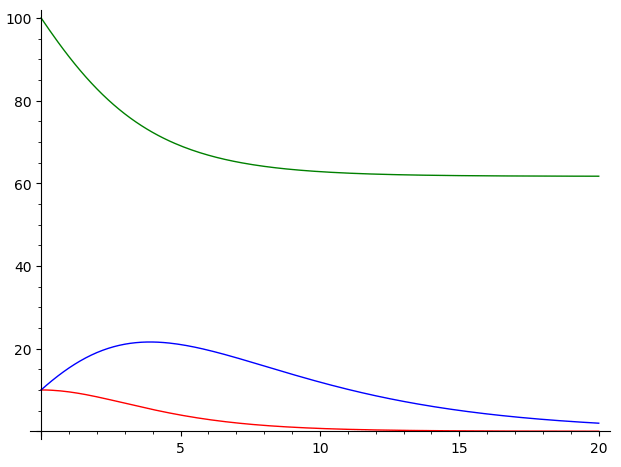
Das alles wird deutlicher, wenn man die Isolierung noch strenger verlaufen lässt. Hier statt 5 Tage von Infektion zu Isolierung (erster Graph) und 3 Tage von Infektion zu Isolierung (zweiter Graph) der Verlauf wenn die Isolierung im Mittel schon 1 Tag nach Infektion erfolgen würde:
Hier das modifizierte SIR-Modell:
H sind die Nie-Infizierten, M die nicht-isolierten Infizierten, I die isolierten Infizierten und R die Erholten (mit Immunität). d/dt sind die entsprechenden Änderungsraten mit der Zeit. Es wird eine Tödlichkeit von Null angenommen. Der Kehrwert von Beta gibt die mittlere Dauer von Infektion zu Isolierung, der Kehrwert von Gamma die mittlere Dauer der Infektion, der Kehrwert von Delta die mittlere Dauer in Isolierung. Es muss gelten: 1/Beta+1/Delta = 1/Gamma.
Analytisch lässt sich das System leider nicht lösen, es lässt sich aber zeigen dass unter der Annahme H = const. (gut erfüllt für sehr große Populationen in der Anfangszeit des Ausbruchs) das Verhältnis I/M, also die Anzahl der Isolierten pro Nicht-Isoliertem, für hohe M einen Grenzwert annimmt, der vor allem davon abhängt, wie intensiv getestet wird. Das macht natürlich Sinn, da erst das Testen eine effektive Isolierung ermöglicht.
Die Simulation durchführen kann man mit dem Cell Server von Sage Math. Habe ich erst gestern entdeckt, ist eine sehr tolle Sache für Leute die Mathe machen wollen, aber keine Ahnung von Programmierung haben (wie ich). So sieht der Code zum Einfügen aus:
sage: (H,M,I,t) = var(‘H,M,I,t’) sage: des = [-0.01*M*H, (0.01*H-0.8-0.2)*M, 0.8*M-0.2*I] sage: ans = desolve_system_rk4(des, [H,M,I], ics=[0,100,10,10], ivar=t, end_points=20) sage: tH=[[a[0],a[1]] for a in ans] sage: tM=[[a[0],a[2]] for a in ans] sage: tI=[[a[0],a[3]] for a in ans] sage: line(tH,color=’green’)+line(tM,color=’red’)+line(tI,color=’blue’)
Die Strenge der Isolierung kann man variieren, indem man die 0,8 (in beiden Gleichungen gleichermaßen) verändert. Hohe Werte bedeuten schnelle Isolierung, niedrige Werte langsame Isolierung. Die jeweiligen Anfangswerte der Populationen kann man durch die Zahlen hinter ics= steuern. Einfach reinkopieren, bei Bedarf verändern und Evaluate drücken! Der Graph wird automatisch erzeugt.
Gestern ist mir eine witzige Sache aufgefallen. Entwickelt man ein simples Modell für den Verlauf von Hamster-Käufen, landet man bei der folgenden Differentialgleichung für die prozentuale Veränderung der Population der Hamster-Käufer:
Eine Gleichung dieser Form (Wachstum wird durch das Integral über die Population behindert) habe ich schon mal in einem Buch gesehen. Und zwar bei dem Wachstum einer Bakterien-Kolonie, die gifitge Gase erzeugt und so das eigene Wachstum wieder behindert. Diese Kolonie würde sich sogar komplett selbst vernichten, sofern es keinen Abzug für diese Gase gibt. Das Phänomen Hamstern folgt dieser Entwicklung.
Am Integral sieht man, dass Hamstern immer ein temporäres Phänomen bleiben muss und eine Normalisierung der Situation schnell folgt. Eine handvoll Shopping-Touren bringt einen Hamster-Käufer in die Population der Versorgten, wo er dann über Monate bleibt. So leert sich die Population der Hamster-Käufer trotz der Anstecklichkeit des Hamster-Verhaltens sehr schnell und bleibt auch leer. Der Spuk ist umso schneller vorbei a) je mehr Hamster es anfänglich und im Mittel gibt und b) je mehr jeder Hamster pro Einkauf mitnimmt. Das Motto sollte also lauten: “Kauft halt euren Scheiss und bleibt dann daheim”.
Das Modell unten ist eine Vereinfachung eines allgemeineren Modells für den Fall dass die Anzahl Hamster H immer weit unter der Anzahl der Normalkäufer N bleiben. V sind die Versorgten. Den Kehrwert von Gamma darf man als einen Parameter auffassen, der ausdrückt wie umfangreich ein einzelner Einkauf eines Hamsters ist. Beta drückt aus, wie sehr sich Normalkäufer von dem Hamster-Verhalten anstecken lassen. N würde sich natürlich streng genommen auch mit der Zeit verändern, aber nimmt man immer H klein gegen N an, darf man das vernachlässigen. Durch diese Annahme wird es erst analytisch lösbar.
Echos, Todesfälle in Pandemien, aktive Kraftwerke und die Anlieferung radioaktiver Stoffe. All diese Dinge habe eine Sache gemeinsam: man berechnet sie auf exakt diesselbe Weise. Das Stichwort ist Faltung. Als ich vor kurzem auf Google nach Faltung gesucht habe, war ich überrascht davon dass scheinbar keine deutsche Webseite eine allgemein-verständliche Erklärung dafür liefert. Und das, obwohl es ein sehr spannendes und nützliches mathematisches Konzept ist. Ich möchte versuchen den Grundgedanken hinter der Faltung hier so zu erklären, dass man es auch ohne Vorwissen gut nachvollziehen kann.
Wie würde man ein Echo berechnen? Genauer gesagt werde ich hier von Hall sprechen: das Nachklingen von Tönen durch Reflektionen an Wänden und Gegenständen. Aber da im Volksmund Echo und Hall meistens synonym verwendet werden, bleibe ich trotzdem bei dem Begriff Echo.
Stellen wir uns vor, dass eine Person am Klavier sitzt und durch Drücken der Tasten Töne erzeugt. Die Höhe der Töne ist egal, es geht nur um die Lautstärke. Er startet eine Stoppuhr und erzeugt zur Zeit t = 1 s einen Ton, nochmal einen zur Zeit t = 2 s, wieder einen zur Zeit t = 3 s und einen letzten Ton zur Zeit t = 4 s. Die jeweiligen Lautstärken L sind:
t = 1 s — L = 40 dB
t = 2 s — L = 70 dB
t = 3 s — L = 90 dB
t = 4 s — L = 40 dB
Also leise, lauter, sehr laut und wieder leise. Gäbe es kein Nachklingen der Töne, etwa weil die Töne sofort durch die Wände verschluckt werden (wie z.B. in Tonstudios), dann wäre die Lautstärke zu Zeit t = 5 s gleich Null. In der Praxis wird die Lautstärke zu t = 5 s aber nicht Null sein, da alle Töne durch Reflektionen an Wänden und Gegenständen nachklingen. Aber wie berechnet man diesen Wert?
Der Grundgedanke: Je weiter ein Ton in der Vergangenheit liegt, desto weniger wird von ihm noch da sein. Von dem Ton, der zu t = 1 s erzeugt wurde, wird später weniger übrig sein als von dem Ton bei t = 4 s. Man muss also vor der Berechnung eine Verteilung bestimmen die sagt, wieviel von vergangenen Tönen jeweils übrig bleibt. Diese Verteilung nennt man die Impulsantwort und charakterisiert das Echoverhalten eines Raumes vollständig. Hier eine mögliche Impulsantwort. Von Tönen, die vor X Sekunden erzeugt wurden, bleibt noch der Anteil Y übrig:
X = 0 s — Y = 100 %
X = 1 s — Y = 50 %
X = 2 s — Y = 25 %
X = 3 s — Y = 12,5 %
X = 4 s — Y = 6,25 %
Jede Sekunde verschluckt der Raum also die Hälfte des verbleibenden Wertes. Sobald die Impulsantwort bekannt ist, kann man diese Impulsantwort (die Prozentwerte) mit dem Signal (die Lautstärken) falten. Wie laut ist das Echo zu t = 5 s?
1 s vor t = 5 s wurde ein Ton mit Lautstärke 40 dB erzeugt. Laut Impulsantwort ist davon noch 50 % vorhanden, also 20 dB.
2 s vor t = 5 s wurde ein Ton mit Lautstärke 90 dB erzeugt. Laut Impulsantwort ist davon noch 25 % vorhanden, also 22,5 dB.
3 s vor t = 5 s wurde ein Ton mit Lautstärke 70 dB erzeugt. Laut Impulsantwort ist davon noch 12,5 % vorhanden, also 8,8 dB.
4 s vor t = 5 s wurde ein Ton mit Lautstärke 40 dB erzeugt. Laut Impulsantwort ist davon noch 6,25 % vorhanden, also 2,5 dB.
Gegeben dieser Impulsantwort, beträgt die Lautstäke des Echos zu t = 5 s also 53,5 dB. Und zu t = 6 s?
2 s vor t = 6 s wurde ein Ton mit Lautstärke 40 dB erzeugt. Laut Impulsantwort ist davon noch 25 % vorhanden, also 10 dB.
3 s vor t = 6 s wurde ein Ton mit Lautstärke 90 dB erzeugt. Laut Impulsantwort ist davon noch 12,5 % vorhanden, also 11,3 dB.
4 s vor t = 6 s wurde ein Ton mit Lautstärke 70 dB erzeugt. Laut Impulsantwort ist davon noch 6,25 % vorhanden, also 4,4 dB.
5 s vor t = 6 s wurde ein Ton mit Lautstärke 40 dB erzeugt. Laut Impulsantwort ist davon noch 3,13 % vorhanden, also 1,3 dB.
Zu t = 6 s bleibt noch ein Echo von 27 dB. Man sieht, dass man so zu jedem Zeitpunkt (und das nicht nur für t > 4 s, sondern auch darunter) die Lautstärke des Echos berechnen kann. In der Praxis sind die Zeitschritte natürlich viel feiner unterteilt als in 1-Sekunden-Schritten. Dort sind es Millisekunden-Schritte. Aber das ist der einzige Unterschied. Die Berechnung funktioniert exakt so.
Wenn niemand zuhört, nenne ich die Faltung eine “gewichtete Vergangenheitssumme”. Ich denke das fasst am besten zusammen, was man hier macht. Man nimmt einen Signalwert aus der Vergangenheit und lässt ihn gewichtet mit einem Prozentwert in die Summe einfließen. Sowohl die Signalkurve als auch die Verteilung der Prozentwerte bleibt unverändert, also hängen nicht davon ab, zu welchem Zeitpunkt man das Echo auswertet. Was sich ändert ist nur, wie man die beiden kombiniert. Bei t = 5 s kombiniert man die Kurven etwas anders wie bei t = 6 s. Aber das Prinzip, die Signalkurve und die Impulsantwort bleiben immer gleich.
Man könnte meinen, dass ein Echo, das mathematisch erzeugt wurde sicherlich anders klingt als eine echte Aufnahme in einem Raum. Interessanterweise gibt es hier keinen Unterschied. Das berechnete Echo klingt weder schief noch künstlich, da die Impulsantwort, sofern sauber gemessen, alle Informationen zur Echobildung enthält. Es charakteristiert das Echoverhalten eines Raumes vollständig und kann jedem trockenen (unverhallten) Signal ohne Qualitätsverlust hinzugefügt werden.
Die Impulsantwort ist auch sehr einfach messbar. Man erzeugt einen normierten, knallartigen Ton (z.B. mittels einer Schreckschusspistole) und zeichnet das Echo auf. An der Kurve lässt sich leicht sehen, wieviel Prozent des Tones nach welcher Zeit noch übrig bleibt. Bis auf einen Faktor hat man die Impulsantwort also schon vor sich. Diese Verteilung kann man in einen Computer speisen und mittels Faltung jedem Signal hinzufügen, dem man dieses Echo geben möchte.
Was hat das mit Pandemien zu tun? Nehmen wir mal folgende Fallzahlen zu den jeweiligen Tagen an. Das wird unser Signal:
Tag 1 — 100 neue Fälle
Tag 2 — 200 neue Fälle
Tag 3 — 400 neue Fälle
Tag 4 — 800 neue Fälle
Tag 5 — 1600 neue Fälle
Zu der Tödlichkeit der Krankheit nehmen wir folgende (der Krankheit typische) Verteilung an. Von denen, die sich vor einer Zeit T angesteckt haben, sterben heute D Prozent. Das ist das Analog zur Impulsantwort.
T = 0 — D = 0 %
T = 1 — D = 0 %
T = 2 — D = 0 %
T = 3 — D = 0 %
T = 4 — D = 1 %
T = 5 — D = 2 %
T = 6 — D = 1 %
T = 7 — D = 0 %
T = 8 — D = 0 %
Also am gefährlichsten ist die Krankheit an Tag 5 nach der Ansteckung. 2 % der Menschen, die sich anstecken, sterben nach dieser Zeit an der Krankheit. Auch an Tag 4 und Tag 6 nach Ansteckung kann die Krankheit tödlich sein. Aber davor gibt es keine Todesfälle (Symptome haben sich noch nicht entwickelt) und danach auch nicht (Symptome klingen wieder ab). Wieviele Todesfälle sind an Tag 6 der Pandemie zu erwarten?
T = 1 Tag vor Tag 6 haben sich 1600 Leute infiziert. Von diesen sterben an diesem Tag 0 %, also 0 Menschen.
T = 2 Tage vor Tag 6 haben sich 800 Leute infiziert. Von diesen sterben an diesem Tag 0 %, also 0 Menschen.
T = 3 Tage vor Tag 6 haben sich 400 Leute infiziert. Von diesen sterben an diesem Tag 0 %, also 0 Menschen.
T = 4 Tage vor Tag 6 haben sich 200 Leute infiziert. Von diesen sterben an diesem Tag 1 %, also 2 Menschen.
T = 5 Tage vor Tag 6 haben sich 100 Leute infiziert. Von diesen sterben an diesem Tag 2 %, also 2 Menschen.
An Tag 6 der Pandemie muss man also 4 Todesfälle erwarten. Und an Tag 7? Wieder faltet man das Signal mit der Impulsantwort:
T = 2 Tage vor Tag 7 haben sich 1600 Leute infiziert. Von diesen sterben an diesem Tag 0 %, also 0 Menschen.
T = 3 Tage vor Tag 7 haben sich 800 Leute infiziert. Von diesen sterben an diesem Tag 0 %, also 0 Menschen.
T = 4 Tage vor Tag 7 haben sich 400 Leute infiziert. Von diesen sterben an diesem Tag 1 %, also 4 Menschen.
T = 5 Tage vor Tag 7 haben sich 200 Leute infiziert. Von diesen sterben an diesem Tag 2 %, also 4 Menschen.
T = 6 Tage vor Tag 7 haben sich 100 Leute infiziert. Von diesen sterben an diesem Tag 2 %, also 1 Mensch.
An Tag 7 der Pandemie wird man, unter Vorraussetzung des obigen Krankheitsverlaufs, mit 9 Todesfälle rechnen müssen. So lässt sich immer vorausberechnen, wieviel Todesfälle in einer Pandemie zu erwarten sind. Mehr als nur im übertragenen Sinne, sondern mathematisch wortwörtlich gesprochen, sind die Todesfälle das Echo der Fallzahlen.
Man kann es sich wieder als eine gewichtete Vergangenheitssumme denken: die vergangenen Fallzahlen fließen gewichtet mit den Prozentwerten des typischen Krankheitsverlaufs in die Summe ein. Das Prinzip, die Fallzahlen und der Krankheitsverlauf ändern sich bei der Berechnung späterer Zeitpunkte nicht. Sondern nur, wie man die Fallzahlen mit dem Krankheitsverlauf kombiniert.
Die Formel für Faltung sieht so aus:
Sie fasst knapp und elegant zusammen, was man oben macht. Das Zeichen nach dem Ist-Gleich-Symbol bedeutet Summe von i = 0 bis k. Beim Berechnen der Summe durchläuft der Parameter i alle Werte von 0 bis k:
Das sind die obigen Rechenschritte: Signal fp mal Impulsantwort fq. Das k ist der Zeitpunkt der Auswertung, also die t = 5 s bzw. t = 6 s oder Tag = 6 bzw. Tag = 7. In die Summe fließen also alle Zeitpunkte bis dahin ein. Die Argumente, also die Zahlen in den Klammern, geben Auskunft darüber, welche Werte man genau kombiniert. Damit ist alles enthalten, was man (oder ein Computer) zur praktischen Berechnung benötigt.
Unabhängig davon, ob man es gewohnt ist Formeln zu lesen oder nicht, darf man nicht vergessen, dass diese Formel nicht mehr tut als den Ansatz zur Berechnung zusammenzufassen. Versteht man die obigen Beispiele, dann versteht man auch was Faltung ist, Formel hin oder her.
Es gibt Unmengen an Anwendungen für die Faltung. Hier einige Beispiele, die ich mir ausgedacht habe, ganz grob skizziert:
Kraftwerke eines Typus werden mit einer Anzahl über die Jahre in Betrieb genommen. Im Jahr 1 sind es N = 10 Stück, im Jahr 2 sind es N = 35 Stück, usw … Es gibt auch eine typische Betriebsdauer für Kraftwerke: Im Jahr 0 nach Einschaltung sind 100 % in Betrieb, in Jahr 1 nach Einschaltung 100 %, usw … Irgendwann geht das natürlich auf kleinere Prozentzahlen über. Faltet man die Anzahl neuer Kraftwerke mit der Verteilung der Betriebsdauer, kann man berechnen, wieviele aktive Kraftwerke es zu einem beliebigen Zeitpunkt gibt.
Radioaktive Stoffe werden mit einer bestimmten Menge über die Zeit angeliefert. An Tag 1 bekommt man m = 10 kg, an Tag 2 m = 8 kg, usw … Diese Stoffe zerfallen (zerstrahlen die Masse) aber gemäß einer Halbwertszeit. Am Tag 0 nach Anlieferung sind noch 100 % einer Lieferung vorhanden, am Tag 1 nach Anlieferung sind noch 50 % einer Lieferung vorhanden, usw … Das entspräche einer Halbwertszeit von einem Tag. Faltet man die angelieferten Mengen mit der Zerfallskurve, dann kann man berechnen, welche Menge des radioaktiven Stoffs zu einem beliebigen Zeitpunkt noch vorhanden ist.
Hat man das Prinzip einmal verinnerlicht, sieht man überall Prozesse, die nach dem Prinzip der Faltung funktionieren. Es ist ein weitverbreiteter Mechanismus in der Natur. Entsprechend ist es sehr schade, dass diese Methode nie Einzug in Schulen gefunden hat und auch außerhalb der Community der Mathematiker und Mathe-Nerds kaum bekannt ist.
Bei Pandemien ist der Zugang zu Supermärkten unbedingt notwendig, aber kann mit gewissen Einschränkungen verknüpft werden um a) einen sicheren Abstrand zwischen den Kunden und b) eine geringe Konzentration des Viruses in der Luft zu gewährleisten. Aktiv steuern lassen sich vor allem zwei Variablen:
Einlassrate r (in Personen / Stunde)
Maximale Verweildauer t (in Stunden)
Um Einblick darüber zu bekommen, welchen Einfluss die Variation der beiden Variablen hat, hier einige Annahmen zur Modellentwicklung. Alles weitere folgt aus diesen Annahmen:
Die Infektionswahrscheinlichkeit p hängt ausschließlich von einem Parameter ab, hier einfach Maßzahl M genannt: p = p(M).
p steigt streng monoton mit M
Die Maßzahl M ist proportional zu exp(-k*d), wobei d der mittlere Abstand zwischen den Kunden in Metern ist
Die Maßzahl M ist proportional zur Verweildauer t
Die Maßzahl M ist proportional zur Infektionsrate i
Ausgehend von diesen Annahmen, kann man folgendes herleiten. Bei steigender Infektionsrate i muss die Einlassrate r den folgenden Wert annehmen, damit die Infektionswahrscheinlichkeit pro Einkauf für einen Kunden unverändert bleibt:
r = (k*L) / (t*ln(i/g))
Wobei L die gesamte Weglänge innerhalb des Ladens ist und g die kleinste Infektionsrate, ab der Einschränkungen eingeleitet werden müssten. Wenig überraschend ist, dass die Einlassrate r mit steigender Infektionsrate i gesenkt werden muss. Wobei sich aber das Problem ergeben kann, dass ab einer kritischen Infektionsrate die Einlassrate so klein gewählt werden muss, dass nicht mehr alle Kunden bedient werden können.
Die Entstehung einer solchen Situation lässt sich aber durch zusätzliche Beschränkung der maximalen Verweildauer verhindern. Beschränkt man die Zeit, die ein Kunde im Laden bleiben darf, auf diesen Wert …
T = (24*k*L) / (N*ln(1/g))
… so ist immer gewährleistet, dass alle Kunden mit gering-bleibendem Infektionsrisiko bedient werden können. Dabei ist N die Anzahl Kunden, die pro Tag bedient werden müssen. Hier eine Schätzung der Werte:
Nimmt man an, dass sich die Maßzahl für jeden Meter halbiert, so hat die Konstante k den Wert k = ln(2) = 0,7.
In Italien gab es etwa ab 300 Fällen pro 1 Million Menschen Schlangen an den Supermärkten. Damit ist grob: g = 0,0003.
Eingesetzt und liberal gerundet: T = 2*L/N
Die kritische Verweildauer T ist also etwa das Zweifache des Verhältnisses von Weglänge L im Geschäft geteilt durch Anzahl Kunden pro Tag N. In den heißesten Phasen einer Pandemie sollte z.B. ein Supermarkt, der mit einer Weglänge von 100 Metern 2000 Kunden pro Tag bedient, die Zeit pro Kunde auf 0,1 Stunden bzw. 6 Minuten beschränken.
Eine so deutliche Beschränkung ist jedoch nur notwendig, wenn die Infektionsraten extreme Ausmaße annehmen (Infektion einer Mehrheit der Bevölkerung). Für Pandemien, bei denen i < 15 % bleibt, wäre keine Einschränkung der Verweildauer zusätzlich zur Kontrolle der Einlassrate erforderlich. Und selbst bei i < 30 % wäre eine Einschränkung auf 15-20 Minuten immer noch ausreichend.
In dieser Publikation vom 11. März 2020 findet sich ein mathematisches Modell, welches Forscher derzeit nutzen um die Ausbreitung des Coronaviruses zu analysieren und projezieren. Es ist eine erweiterte Variante des Standard-SIR-Modell, mit dem man schon lange Ausbrüche simuliert. Hier eine Erklärung, wie es funktioniert:
Die Population wird in die folgenden Gruppen unterteilt:
S = Susceptible = Empfängliche: Das sind die Menschen, die den Virus nicht haben, aber ihn durch Kontakt mit infizierten Menschen bekommen könnten. Also alle nicht-infizierten Menschen ohne Immunität. dS/dt ist die Änderungsrate der Empfänglichen S mit der Zeit
E = Exposed = Exponierte: Das sind jene, die schon infiziert sind, aber keine Symptome zeigen, entweder weil sie sich noch in der Inkubationszeit befinden oder weil bei ihnen die Krankheit generell ohne Symptome verläuft (asymptomatische Fälle). dE/dt ist die Änderungsrate von E mit der Zeit
I = Infected = Infizierte: Das sind die Menschen, die infiziert sind und auch Symptome zeigen. dI/dt ist die Änderungsrate von I mit der Zeit
R = Recovered = Genesene: Diese Variable sammelt alle Menschen, die sich infiziert hatten und nun wieder gesund sind. Das Modell nimmt Immunität an. dR/dt ist die Änderungsrate von R mit der Zeit
Jeder Mensch befindet sich zu jeder Zeit in einer der vier Gruppen. Zusätzlich gibt es noch die Variable V, die die Konzentration des Viruses in der Umwelt erfasst (Luft & Oberflächen). So funktioniert das Modell:
Die Zahl der Empfänglichen S nimmt durch Geburten und Migration zu (erster Term) und nimmt durch natürlich Tode ab (letzter Term)
Je größer die Anzahl der Empfänglichen S und Exponierten E, desto mehr Leute infizieren sich pro Zeiteinheit. Diese landen in der Gruppe der Exponierten E. Die Konstante Beta(E) gibt die Wahrscheinlichkeit für eine Infektion pro Kontakt an
Je größer die Anzahl der Empfänglichen S und Infizierten I, desto mehr Leute infizieren sich pro Zeiteinheit. Diese landen auch in der Gruppe der Exponierten E. Die Konstante Beta(I) gibt die Wahrscheinlichkeit für eine Infektion pro Kontakt an
Je größer die Anzahl der Empfänglichen S und Konzentration V in der Umwelt, desto mehr Leute infizieren sich pro Zeiteinheit. Diese landen ebenso in der Gruppe der Exponierten E. Die Konstante Beta(V) gibt die Wahrscheinlichkeit für eine Infektion pro Empfänglichem und Einheit Konzentration an
Das deckt alle Wege ab, wie sich die Anzahl der Empfänglichen ändern kann. Alle Veränderungen der letzten drei Punkten landen in der Gruppe der Exponierten E, also die frisch infizierten, die noch keine Symptome zeigen. Nach einer Inkubationszeit (Kehrwert der Konstante Alpha), landet jeder Exponierten E in der Gruppe der Infizierten I. Ausnahme: Jene, die in dieser Zeit eines natürlichen Tod sterben.
Die Anzahl Infizierter I reduziert sich:
Durch Genesung. Jene landen natürlich in der Gruppe der Genesenen R. Die Wahrscheinlichkeit pro Infiziertem dafür ist Gamma
Durch Tod infolge von Komplikationen, welche durch den Virus verursacht wurden. Die Wahrscheinlichkleit dafür ist w
Durch natürlichen Tod
Alle Genesenen landen also in der Gruppe der Genesenen R, welche sich nur durch natürlich Tod reduzieren kann. Hier wäre der Punkt, an dem man einen Term einbringen könnte, wollte man modellieren dass nicht alle Genesenen automatisch (und für alle Zeiten) immun sind. Das würde man tun, indem man in der Gleichung für R den Term -k*R einfügt, wobei 1/k die Durchschnittsdauer der Immunität ist, und bei der Gleichung für S entsprechend den Term +k*R, um sie dort wieder zu sammeln.
Die Annahme von Immunität dürfte aber akzeptabel sein. Zwar ergibt sich selten eine permanente Immunität bei Viren, aber meistens doch eine Immunität, die über Jahre reicht, während ein Ausbruch selbst nur einige Monate andauert. In dieser relativ kurzen Zeit eine permanente Immunität anzunehmen wird die Ergebnisse also kaum verzerren können.
Schlussendlich wird noch angenommen, dass der Konzentrationszuwachs linear mit der Anzahl der Exponierten E und Infizierten I steigt, aber die Konzentration bei sehr hohen Werten von E und I einem Grenzwert zustrebt (letzter Term).
Vor dem Fit haben die Forscher auch diese Annahmen gemacht:
Die Warscheinlichkeiten, dass sich jemand durch Kontakt infiziert, ob nun durch Kontakt mit einem Exponierten E, Infizierten I oder Kontakt mit dem Virus in der Umwelt (Konzentration V), sinken mit steigender Verbeitung des Viruses. Diese Abhängigkeiten modellieren, dass Menschen vorsichtiger werden, besser informiert sind und zunehmend durch Quarantänemaßnahmen eingeschränkt werden, je weiter verbreitet das Virus ist. Die mathematische Form der Annahme ist generisch, eine Näherung erster Ordnung welche zwar die Grenzbedingungen erfüllt, aber keine empirische Motivation hat.
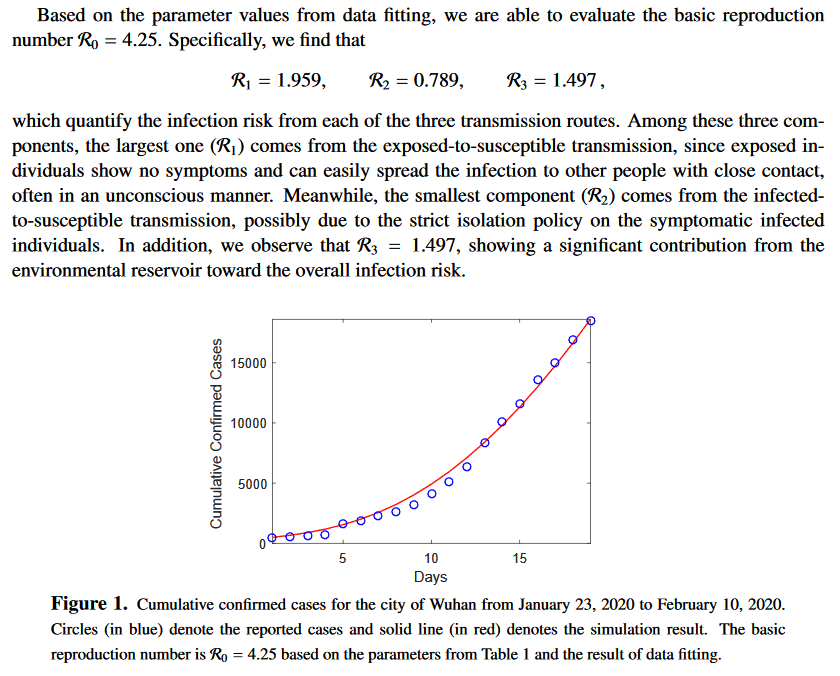
In der Publikation ermitteln die Forscher noch den Gleichgewichtszustand. Das ist ziemlich einfach. Gleichgewicht heißt, dass sich die Werte aller Variablen nicht mehr mit der Zeit ändern, sondern bei einem konstanten Wert bleiben. Das heißt auch: Die Änderungsrate jeder Variable mit der Zeit ist dann Null. Man findet also das Gleichgewicht, indem man jede obige Gleichung gleich Null setzt.
Dann folgt noch viel Mathematik, die nur dazu dient zu untersuchen, ob dieses Gleichgewicht stabil oder labil, mit dem Schluss dass es stabil ist. Stabil heißt in diesem Kontext: Wird das System aus dem Gleichgewicht ausgelenkt, strebt es diesem wieder zu. Der Fit des Modells ist ziemlich gut und zeigt, dass sich …
circa 45 % durch Kontakt mit Exponierten infizieren
circa 20 % durch Kontakt mit Infizierten infizieren
circa 35 % durch über die Luft & Oberflächen infizieren
Eigentlich ist der Grundgedanke ganz einfach. Um zu wissen, wie tödlich eine Krankheit ist, teilt man die Anzahl tödlicher Ausgänge D durch die Gesamtanzahl der Fälle N: CFR = D / N (CFR steht für Case Fatality Rate). Bei D = 100 tödlichen Ausgängen unter N = 1000 Fällen wäre die Mortalität CFR = 100/1000 = 0,1 = 10 %. Wieso sollte diese Zahl problematisch sein?
Problem Nummer 1: Der Zeitverlauf
Nehmen wir eine fiktive Krankheit an, an der sich jeden Tag 100 Leute anstecken. Von 100 angesteckten sterben immer genau 10 und zwar immer genau 5 Tage nach der Infektion. Die echte Case Fatality Rate ist also 10/100 = 0,1 = 10 %. Wieso echt? Gibt es eine falsche?
Stellen wir uns vor, dass wir an Tag 8 des Ausbruchs sind. Jeden Tag stecken sich 100 Leute an, somit haben wir am achten Tag 800 infizierte Personen. Wieviel Todesfälle gibt es? Die ersten Todesfälle kommen erst an Tag 5. An diesem Tag sterben 10 Menschen, dann nochmal 10 an Tag 6, nochmal 10 an Tag 7 und nochmal 10 an Tag 8. Das sind bis Tag 8 also insgesamt 40 Todesfälle bei 800 Fällen. Macht eine naive Case Fatality Rate von 40/800 = 0,05 = 5 %. Nur halb soviel wie die tatsächliche Mortalität.
Es reicht also nicht, nur die Anzahl tödlicher Fälle durch die Gesamtanzahl der Fälle zu teilen. Für einen korrekten Wert, müssen wir die Anzahl der Todesfälle zu Zeit t durch die Gesamtanzahl der Fälle zur Zeit t-T teilen, wobei T die mittlere Dauer von Infektion zum Tod ist:
CFR = D(t) / N(t-T)
Dies ist ein Detail, dass die Rechnung etwas verkompliziert, aber es stellt kein unüberwindbares Problem dar. Durch Beobachtung der Fälle lässt sich die mittlere Dauer von Infektion zum Tod verlässlich abschätzen und die entsprechende Korrektur anwenden. Ein viel größeres Problem sind die asymptomatischen und milden Fälle.
Problem Nummer 2: Asymptomatischeund milde Fälle
Asymptomatisch heißt: Eine Person ist infiziert, aber es folgen keine Krankheitssymptome. Die Person wirkt also gesund. Wieso ist das ein Problem für die Berechnung der Mortalität? Stellen wir uns vor, dass sich 1000 Leute an einer Krankheit infizieren. 500 Fälle sind asymptomatisch und die restlichen 500 Fälle zeigen Symptome der Krankheit. Sagen wir, dass von diesen 1000 Menschen insgesamt 100 Leute sterben. Macht wieder eine echte Mortalität von 100/1000 = 0,1 = 10 %.
Aber was sieht der Betrachter? Der Betrachter sieht die asymptomatischen Fälle nicht. Diese tragen zwar den Virus, werden aber nie in einer Arztpraxis oder im Krankenhaus auftauchen. Entsprechend werden diese Menschen, sofern es keine Massentests gibt, auch in keiner Statistik erfasst. Der Betrachter sieht 500 Fälle und 100 Tote und berechnet somit eine Mortalität von 100/500 = 0,2 = 20 %. Ein deutlich überschätzter Wert.
Milde Fälle wirken ganz ähnlich. Von diesen werden zwar mehr in der Statistik auftauchen als von den asymptomatischen Fällen, doch viele Leute werden bei einem milden Verlauf nicht zum Arzt gehen und so auch nie auf dem Radar auftauchen. Je mehr asymptomatische und milde Fälle es gibt, desto mehr wird die beobachtete Mortalität vom echten Wert abweichen und zwar immer in Richtung Überschätzung der tatsächlichen Mortalität.
Bezeichnet man mit p1 und p2 den Anteil asymptomatischerund milder Fälle und mit q1 und q2 den entsprechenden Anteil, den man in der Statistik nicht erfasst, so gilt für den echten CFR:
CFR = (1 – p1*q1 – p2*q2) * D(t) / N(t-T)
Ohne Massentests bleibt dies ein unüberwindbares Problem. Nur ein breites Testen kann die asymptomatischen und milden Fällen erfassen. Deshalb sollte man z.B. bei den Daten zum Coronavirus auf Länder achten, die Massentests durchführen. Hier ist vor allem Südkorea zu nennen. Die Mortalität, die in Südkorea ermittelt wird, spiegelt die tatsächliche Mortalität bei Covid-19 wohl am besten wieder.
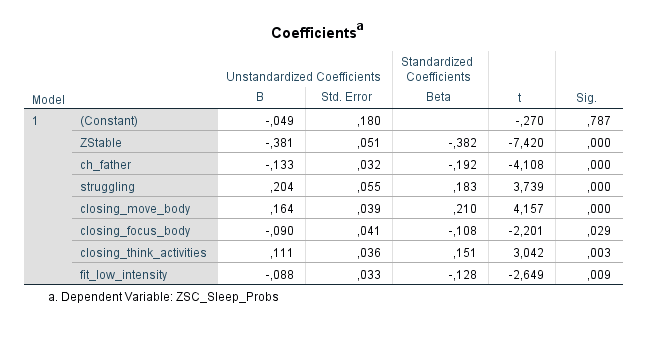
Schlafprobleme sind eine Volkskrankheit, doch es gibt Wege dem effektiv zu begegnen. Hier die Analyse eines interessanten Datensatzes (n = 264), der zeigt dass es auch darauf ankommt, an was man denkt sobald man die Augen schließt. Erst das gesamte Modell:
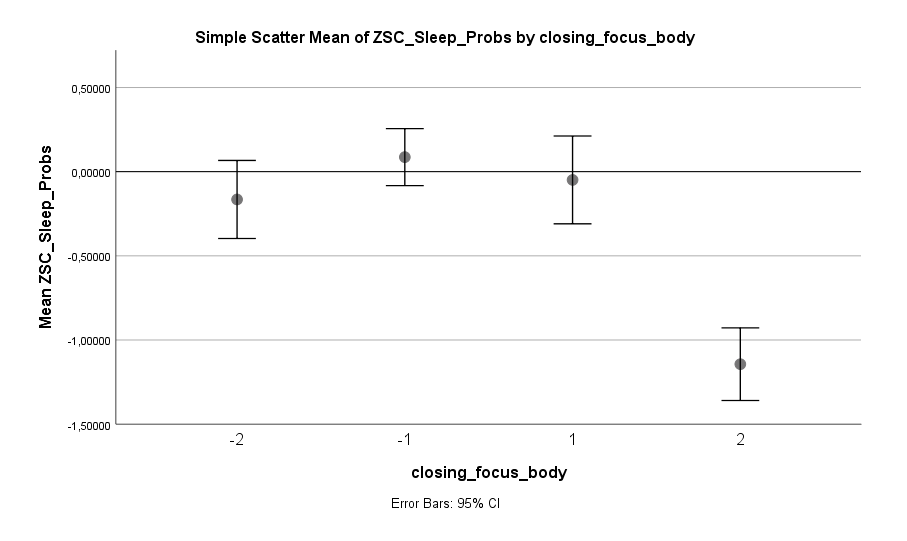
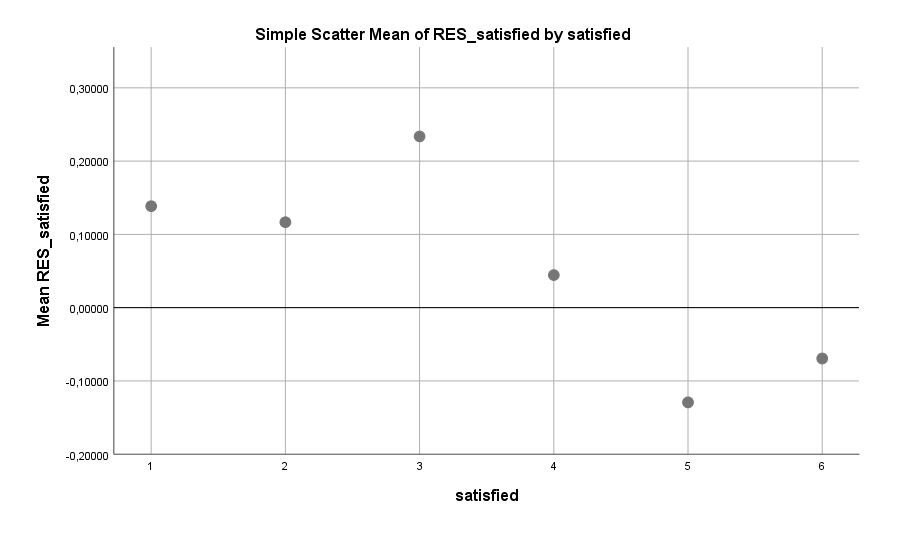
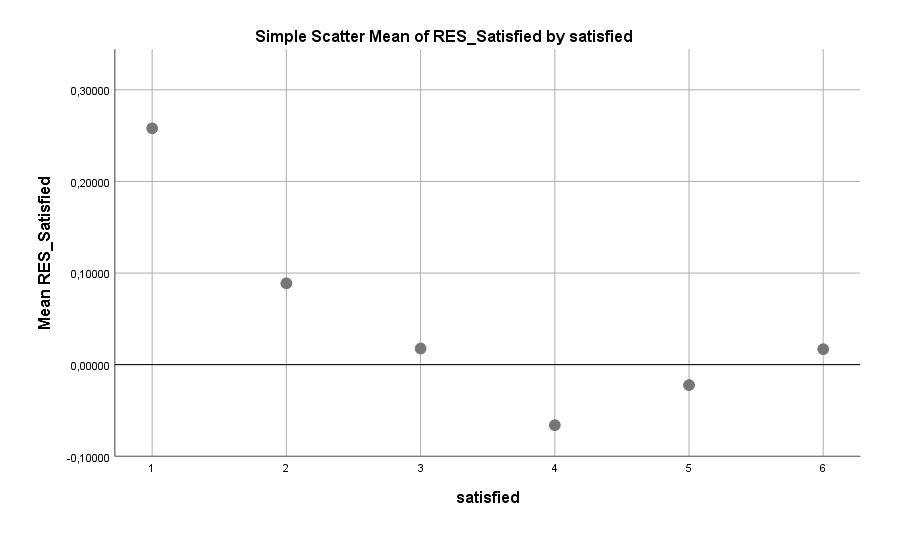
Eine Sache, die sich als problematisch zeigt, ist das Denken an kommende (berufliche oder private) Aktivitäten. Menschen, die ihre Gedanken im Bett zu diesen Aktivitäten wandern lassen, zeigen ein signifikant erhöhtes Risiko für Schlafprobleme:
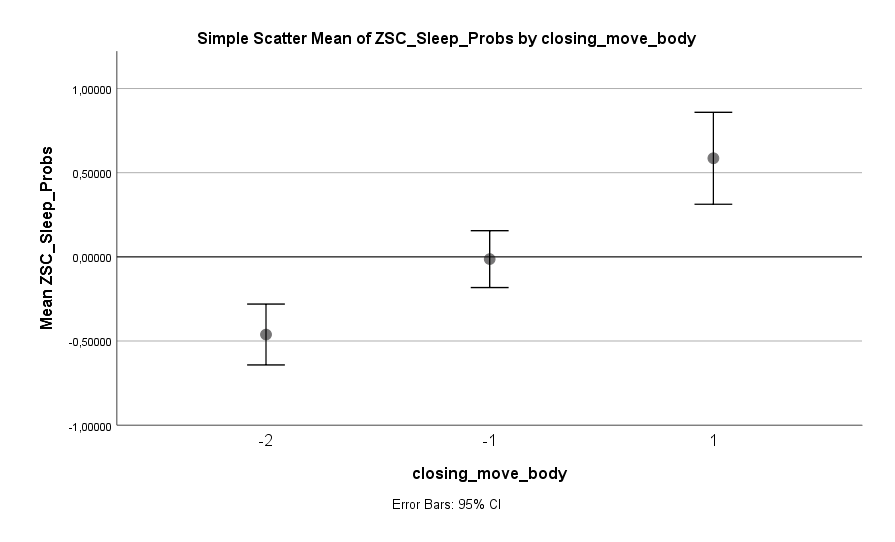
Schon etwas weniger an kommende Aktivitäten zu denken, kann einen deutlichen Unterschied machen. Besser ist es aber, diese Gedanken komplett aus dem Bett zu verbannen. Doch was kann man stattdessen machen? Glücklicherweise gibt der Datensatz darauf einen Hinweis: auf den Körper konzentrieren. Das Konzentrieren auf Empfindungen im Körper scheint das Risiko von Schlafproblemen senken zu können:
Dabei sollte man aber darauf achten, den Körper bewusst still zu halten. Es gilt die Empfindungen im Körper nur passiv wahrzunehmen, ohne etwas verändern zu wollen, denn sich im Bett zu bewegen ist Gift für das Einschlafen:
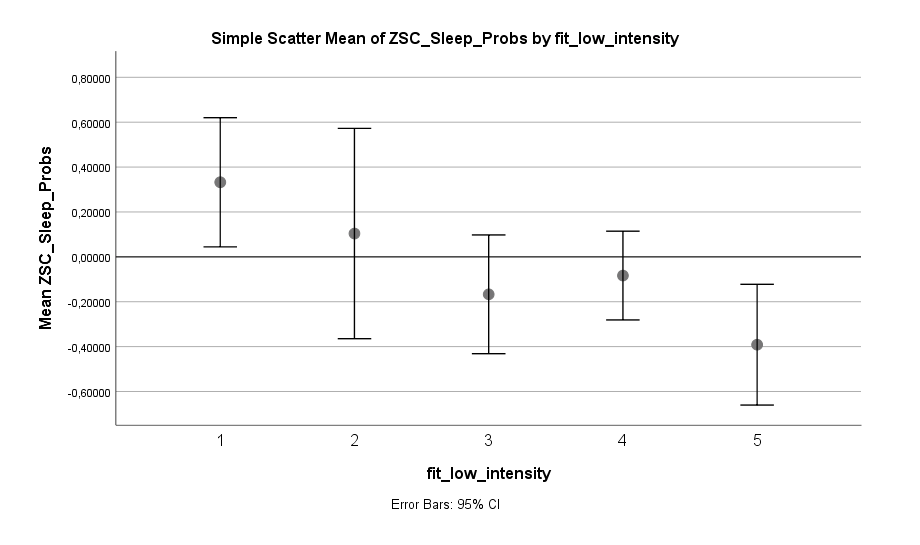
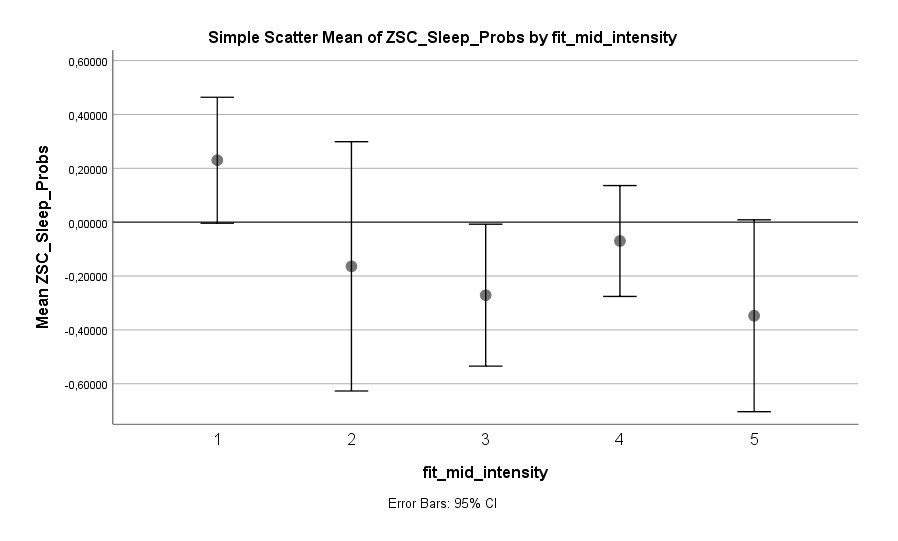
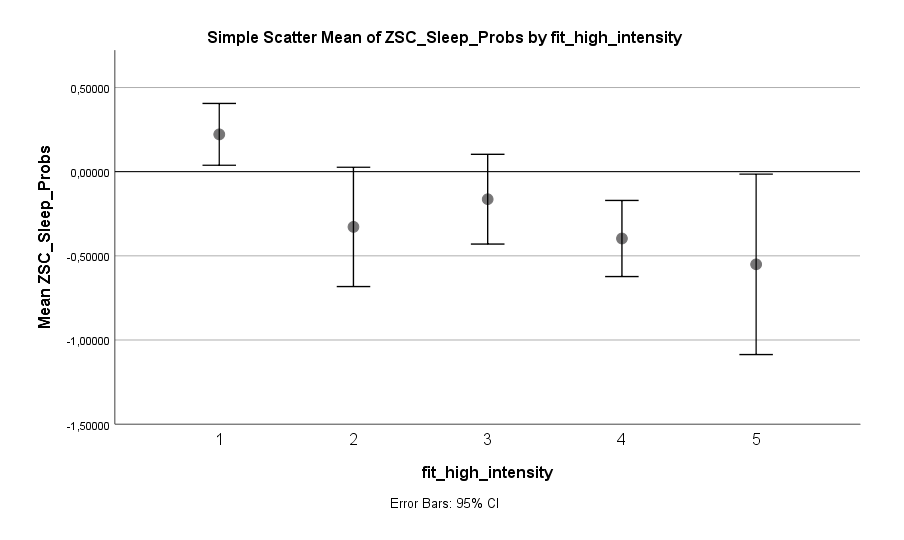
Fitness hilft auch beim Einschlafen. Und es gilt explizit nicht der Grundsatz des Auspowerns! Eine Stunde bequem laufen gehen scheint genauso effektiv zur Reduktion von Schlafproblemen zu sein wie Mid Intensity Training (z.B. Jogging) oder High Intensity Training (z.B. Volles Auspowern im Gym). Man muss nicht halbtot ins Bett fallen, um in den Genuss des positiven Effekts zu kommen. Der Grundsatz scheint eher zu sein: Hauptsache viel bewegt, egal in welcher Intensität.
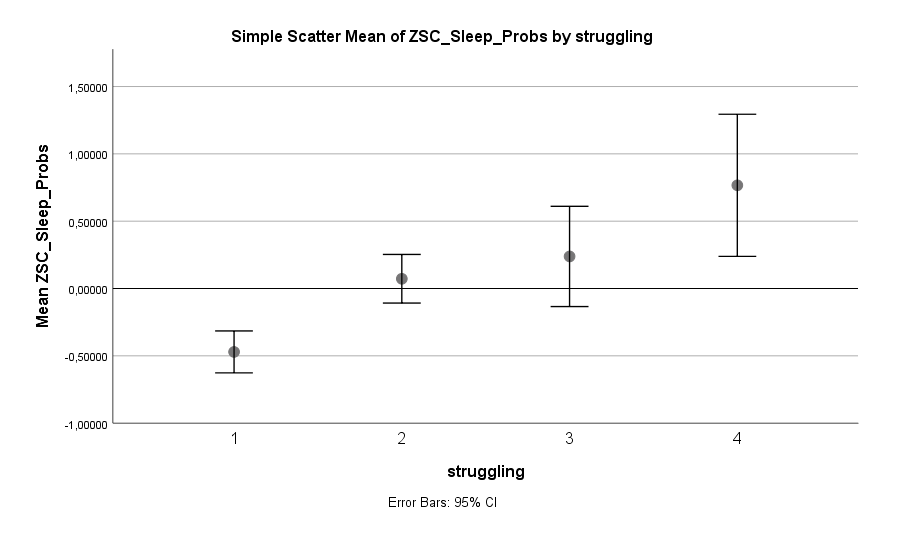
Etwas, das sich leider nicht so leicht ändern lässt, aber sich sehr deutlich auf den Schlaf auswirkt, sind finanzielle Probleme. Menschen, die davon berichten dass sie der Zahlung ihrer Rechnungen und Schulden nicht nachkommen, haben ein stark erhöhtes Risiko von Schlafproblemen:
Das ist etwas, dass ich schon in einem anderen Datensatz in ähnlicher Stärke gesehen habe. Man darf den obigen Graph somit als eine Reproduktion dieses Effekts betrachten. Aber betrachtet man die Effektstärken der anderen hier genannten Effekte, lässt sich auch dieser Zuwachs an Risiko durch eine positive Lenkung der Aufmerksamkeit und mehr Bewegung gut wettmachen.
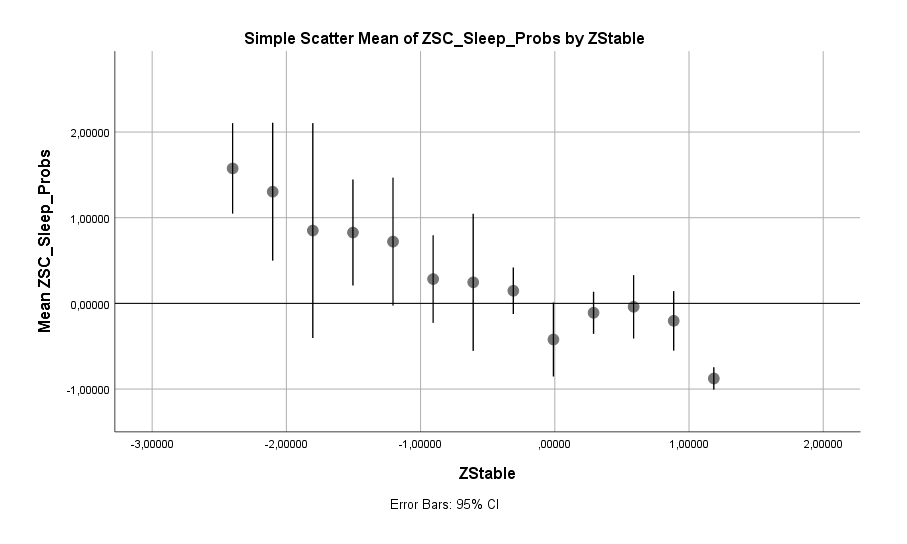
Schlussendlich: Der Hauptfaktor bei Schlafproblemen ist und bleibt natürlich immer noch die emotionale Stabilität / Labilität.
Hier zeigt sich ein fieser und destruktiver Teufelskreis. Die veranlagte Labilität führt zu Schlafproblemen und der Schlafmangel erhöht wiederrum die Labilität. Diese Kombination kann sich schnell zu einer Krise hochschaukeln. Um so wichtiger ist es hier, die richtigen Maßnahmen einzuleiten um das Abrutschen in diesen Teufelskreis zu vermeiden.
Anmerkungen zur Verlässlichkeit des Modells:
Ausreißer: Für alle Fälle gilt Cook’s Distance < 0.3. Es gibt also keine Ausreißer im Datensatz, die das Modell verzerren könnten.
Fehler erster Art: Sehr unwahrscheinlich, da für alle Prediktoren außer einem p < 0,01 gilt (und für alle p < 0,05)
Fehler zweiter Art: Extrem unwahrscheinlich laut diesem Rechner für Statistical Power. Alles müsste sich gut reproduzieren lassen.
Insgesamt kann man das Modell als sehr verlässlich betrachten.
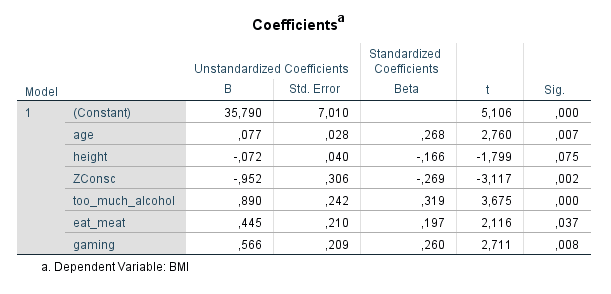
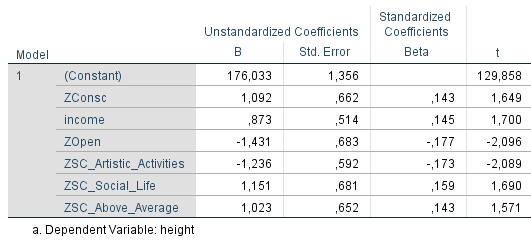
Der BMI ist die gängigste Kennzahl zur Erfassung und Kategorisierung der Körperform. Sowohl in der Medizin als auch in der Psychologie wird der BMI als Diagnosekriterium verwendet (z.B. bei Anorexia). Welche Faktoren zeigen bei Männern einen Einfluss auf den BMI? Hier ist ein Modell, dass sich aus einem kleinen Sample (n = 152) ergibt:
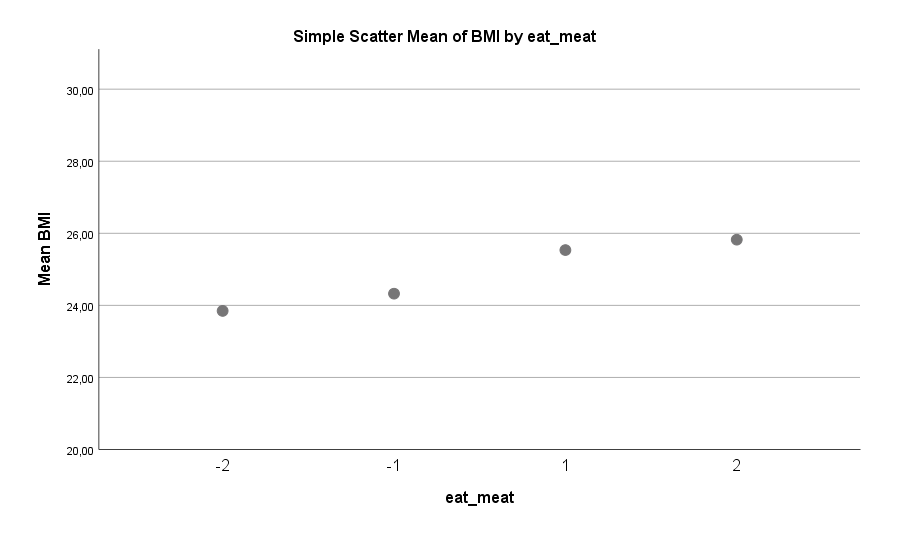
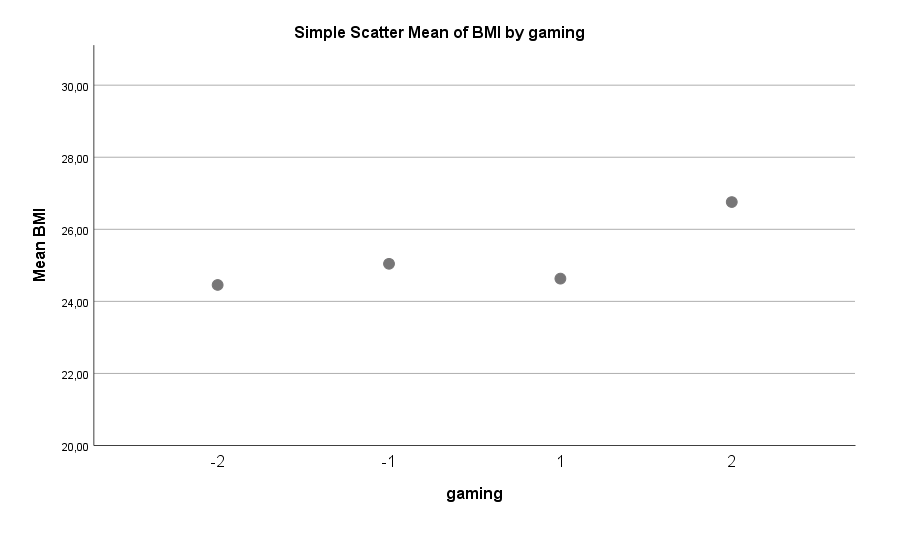
Neben dem Alter und der Körpergröße (ein insignifikanter Prediktor, zur Korrektur trotzdem im Modell enthalten) finden sich im Datensatz vier signifikante Faktoren: Ordentlichkeit gemäß der Big-Five, Alkoholkonsum, Fleischkonsum und das Computerspielen.
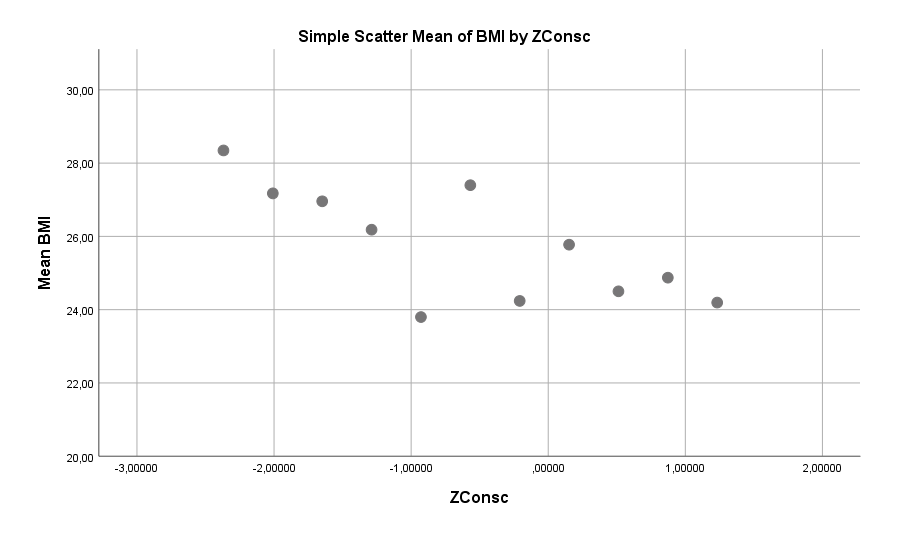
Unordentliche Männer haben im Durchschnitt einen höheren BMI als ordentliche Männer. Die Effektstärke beträgt, bereinigt nach allen anderen Faktoren im Modell (siehe zweiter Graph), etwa 3 BMI-Punkte. Das übersetzt sich, bei einem 175 cm großen Mann, in einen Gewichtsunterschied von etwa 9 kg – ein sehr deutlicher Unterschied.
Übermäßiger Alkoholkonsum scheint auch ein sehr klarer Risiko-Faktor für Übergewicht bei Männern zu sein. Hier beträgt der bereinigte Unterschied zwischen gar keinem Alkoholkonsum und starkem Alkoholkonsum etwa 4 BMI-Punkte. Das macht 12 kg Unterschied bei einem 175 cm großen Mann.
Einen schwächeren, aber immer noch signifikanten Einfluss auf die Körperform hat der Konsum von Fleisch (dies gilt auch bei Frauen und zwar in ähnlicher Stärke). Übermäßiger Fleischkonsum bringt um die 1,5 BMI-Punkte oder 4,5 kg beim 175 cm großen Mann.
Fehlt noch das übermäßige Spielen am Computer, das sich bei Männern als ein merklich gewichtsförderndes Hobby entpuppt. Zu oft am Computer zu spielen bringt um die 2 BMI-Punkte oder 6 kg beim 175 cm Mann. Das ist natürlich kaum überraschend, denn bei diesem Hobby fehlt es nicht nur an Bewegung, sondern oft konsumieren Gamer nebenbei auch noch ungesunde Produkte wie Chips oder zuckerhaltige Cola.
Dank Bereinigung darf man hier frei addieren. Ein 175 cm Mann, der von Null Alkoholkonsum und Gaming auf übermäßig Alkoholkonsum und Gaming über geht, muss eine Gewichtszunahme von 18 kg erwarten. Kommt dazu noch der Schritt von Vegetarier zu übermäßigem Fleischkonsum, landet er sogar bei einem Plus von etwa 23 kg.
Wie verlässlich ist das Modell? Ein kurzer Überblick:
Dank der Sig-Levels von p < 0,01 für alles außer Körpergröße (p > 0,05) und Fleischkonsum (p < 0,05), ist die Wahrscheinlichkeit für einen Fehler erster Art ziemlich gering.
Die Warscheinlichkeit für einen Fehler zweiter Art beträgt laut einem Rechner für Statistical Power um die 5 %. Das ist okay, aber nicht spektakulär. Die stärksten Effekte dürften gut reproduzierbar sein, bei den schwächeren Effekten gilt das vielleicht jedoch nicht.
Ausreißer, welche einen übermäßigen Einfluss auf das Modell zeigen, sind im finalen Modell keine mehr enthalten. Für alle Fälle liegt die Cook’s Distance unter 0,5.
Insgesamt recht zufriedenstellend, aber noch etwas grenzwertig. Die obigen Resultate zu Ordentlichkeit, Alkoholkonsum und Gaming sind wohl ziemlich zuverlässig, diesen traue ich, das Resultat zu Fleischkonsum darf man aber kritisch sehen.
Unter der Gruppe der Psychopathen (kein Krankheitsbild gemäß DSM, aber man darf Psychopathie grob als eine antisoziale Persönlichkeitsstörung mit Gewaltbereitschaft verstehen) sind die Männer in der deutlichen Überzahl. Die Schätzungen schwanken, aber Pi Mal Daumen kommen auf eine weibliche Psychopathin etwa zwanzig männliche Psychopathen. Oder anders gesagt: Nur circa 5 % aller Psychopathen sind weiblich. Das Warum zu verstehen ist ein interessantes und nützliches Lehrstück in Sachen Statistik.
Wir konzentrieren uns hier auf die Abwesenheit von Agreeableness (Herzlichkeit, Empathie), eine Vorraussetzung für Psychopathie. Im Mittel unterscheiden sich Männer und Frauen nur sehr wenig im Hinblick auf Agreeableness. Standardisiert man den Score von Agreeableness auf 100 Punkte, dann liegen Frauen bei etwa 105 und Männer bei 95. Kein sonderlich großer Unterschied. Zu jedem Mann finden sich leicht zahllose Frauen, die weniger empathisch sind. Trotzdem reicht dieser geringe Unterschied der Mittelwerte aus, um das auffällige verschobene Geschlechterverhältnis bei Psychopathen zu erklären.
Der Trick ist nur das extreme Ende der Verteilung zu betrachten. Nimmt man eine Standardabweichung von 10 Einheiten an (ein Fantasiewert zum Zwecke der Demonstration), dann würde die Verteilung des Agreeableness-Scores bei Frauen so aussehen:
Berechnet man auf Basis dieser Annahmen, wieviele Frauen praktisch empathielos sind, hier definiert als Agreeableness-Scores < 80, dann erhält man einen Wert von 0,6 %. Es fallen also nicht viele Frauen unter diesen Cut-Off und dies liegt daran, dass die Normalverteilung sehr stark zum Ende hin abfällt. Genau diese scharfe, nichtlineare Abnahme ist auch der Grund, wieso eine leichte Verschiebung des Mittelwertes eine so große Veränderung in extremen Bereichen der Skala erzeugen kann!
Nehmen wir für Männer diesselbe Standardabweichung an und setzen einen Mittelwert von 95 voraus, nur leicht unter dem Mittelwert für Frauen, so erhält man diese Verteilung:
Gemäß dem Output der App fallen 6,7 % der Männer unterhalb des oben definierten Cut-Off von Agreeableness < 80. Das macht, wenn man nur die Gruppe der empathielosen Menschen betrachtet, ein sehr auffälliges Geschlechterverhältnis von 6,7 % / 0,6 % = 11. Auf eine empathielose Frau kommen bei den gegebenen Mittelwerten und Standardabweichungen demnach elf empathielose Männer. Oder anders gesagt: Laut Output sind nur 8 % aller empathielosen Menschen Frauen.
Die Zahlen, die ich hier als Voraussetzungen verwendet habe, sind möglichst an der Realität orientiert, jedoch nicht hundertprozentig korrekt. Doch das Prinzip zählt. Wenn Eigenschaften von Populationen einer Normalverteilung genügen (oder einer ähnlichen beschaffenen Verteilung), dann machen sich geringe Differenzen im Mittelwert als starke Unterschiede an den Rändern der Skala bemerkbar.
Diese mathematische Tatsache erklärt, wieso es viel mehr männliche als weibliche Psychopathen gibt. Es ist schlicht eine Konsequenz der Normalverteilung jener Eigenschaften, die Psychopathie ausmachen, gepaart mit einer (für sich genommen) unspektakulären Differenz der Mittelwerte bei diesen Eigenschaften.
Das gilt natürlich auch für das andere Ende des Spektrum. Es gibt keinen gängigen Begriff für Menschen, die übermäßig Empathisch sind, aber nennen wir sie hier einfach mal Hyperempathen und definieren Hyperempathie beginnend ab Agreeableness > 120. Es ergibt sich exakt das umgekehrte Bild: auf einen männlichen Hyperempathen kommen elf Hyperempathinnen. Das erklärt vielleicht auch, wieso Frauen trotz Gelichberechtigung immer noch in den Pflegeberufen dominieren.
Diese Resultate haben mich sehr überrascht da ich bisher davon ausging, dass die Körpergröße eher eine Zufallsgröße ist, die keine psychologische Manifestation hat. Dem scheint aber nicht so zu sein. Ob nun aus genetischen Gründen, Gründen des Feedbacks / Sozialisierung oder einer Mischung davon – Es lassen sich merkliche Unterschiede in der Persönlichkeit zwischen größeren und kleineren Männern feststellen.
In der Summe gilt: Große Männer haben in der Tendenz einen höheren Score auf der Big-Five-Skala für Ordentlichkeit (ordentlicher und verlässlicher), aber einen geringeren Score auf der Skala für Offenheit (weniger intellektuell und künstlerisch). Sie haben auch, und das kann man als Bestätigung der obigen Punkte sehen, im Mittel ein höheres Einkommen und betreiben seltener künstlerische Hobbies.
Nur am Rande: Interessanterweise gilt der Zusammenhang zwischen Körpergröße und Offenheit auch bei Frauen. Frauen > 160 cm erzielen einen niedrigeren Score auf der Offenheitsskala als Frauen < 160 cm.
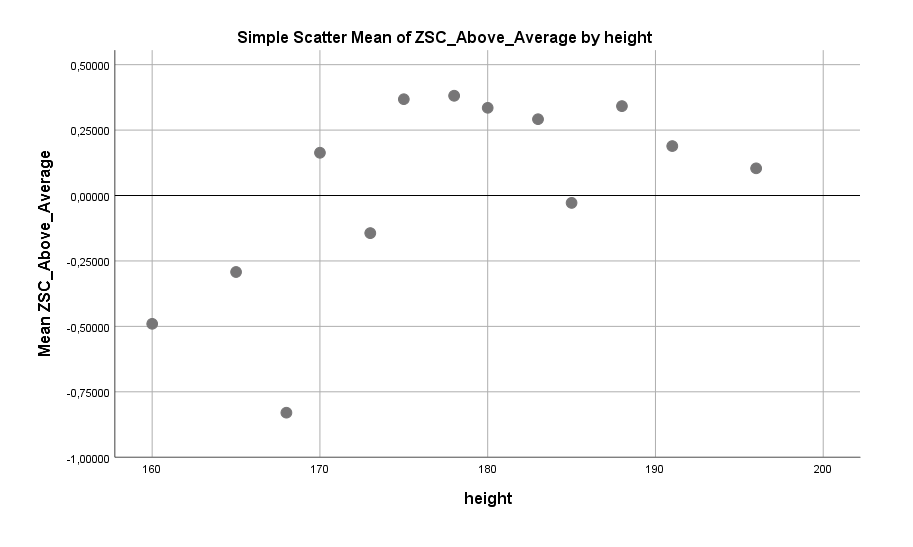
Daneben berichten große Männer auch von einem besseren Sozialleben mit Freunden / Bekannten (es gibt kein Unterscheid bei der Beziehung zur Familie) und erzielen einen höheren Score bei drei Fragen, die sich auf den Above-Average-Effekt beziehen. Männer sehen sich im Vergleich zu Frauen generell als eher überdurchschnittlich kompetent und zwar bei fast allen Skills. Das ist ein altbekanntes Resultat des Above-Average-Effekts: Mann-Sein ist der größte Faktor. Aber auch innerhalb der Männerschaft scheint es nochmals eine Aufspaltung zu geben.
Große Männer geben im Vergleich zu kleineren Männern signifikant häufiger an, überdurchschnittlich gute soziale und intellektuelle Skills zu haben und sehen sich eher als überdurchschnittlich gute Autofahrer. Interessant ist, dass ihre Einstufung als überdurchschnittlich intellektuell den Resultaten des Big-Five-Tests direkt widerspricht, während die Überdurchschnittlichkeit bei sozialen Skills durchaus im Einklang mit den restlichen Angaben (aktiveres Sozialleben) liegt.
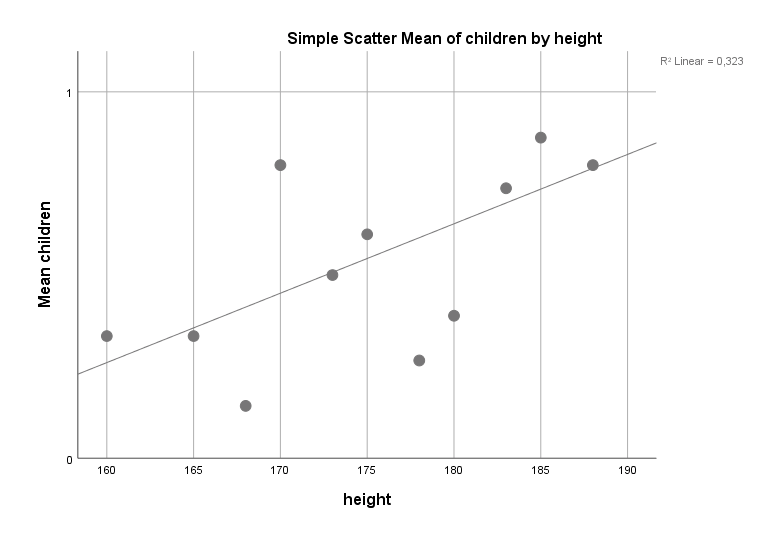
Noch ein Fun Fact: Große Männer produzieren im Mittel mehr Kinder (Graph siehe unten). Das lässt sich aber zum Teil durch die höhere Ordentlichkeit und das höhere Einkommen erklären. Aufgrund dieses Zusammenhangs habe ich diese Variable nicht ins Regressionsmodell aufgenommen. Eng korrelierende unabhängige Variablen können leicht zu Kollinearitätsproblemen führen und die Koeffizienten grob verzerren. Eine der drei Variablen musste somit raus. Danach gab es, gemessen am VIF, auch keine Kollinearitätsprobleme mehr im Modell.
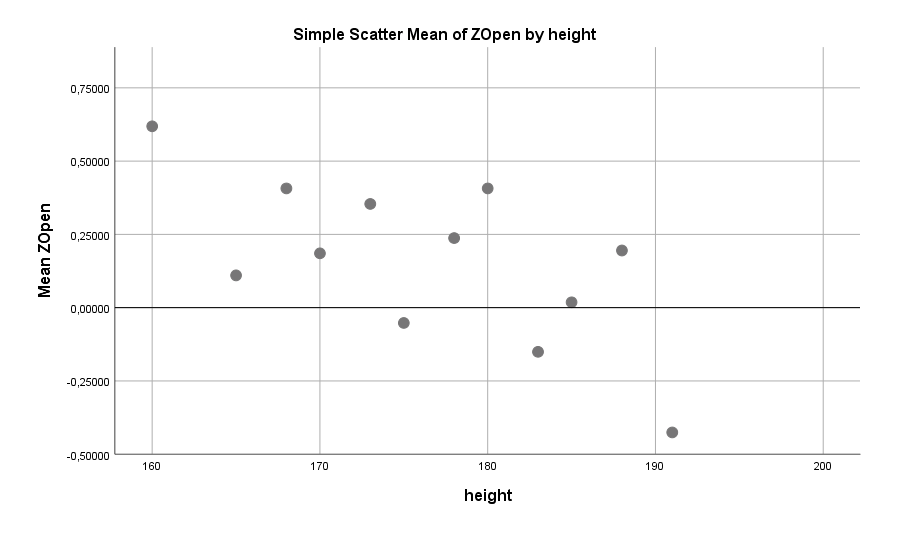
Körpergröße und Ordentlichkeit bei Männern:
Körpergröße und Offenheit:
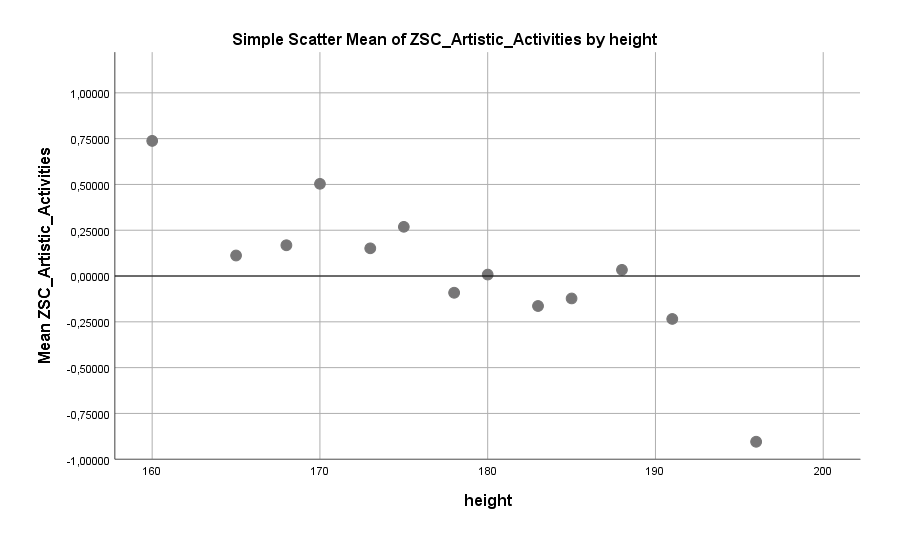
Körpergröße und künstlerische Hobbies (hier der Mittelwert aus den Betätigungen “Musikinstrument spielen” und “Malen”):
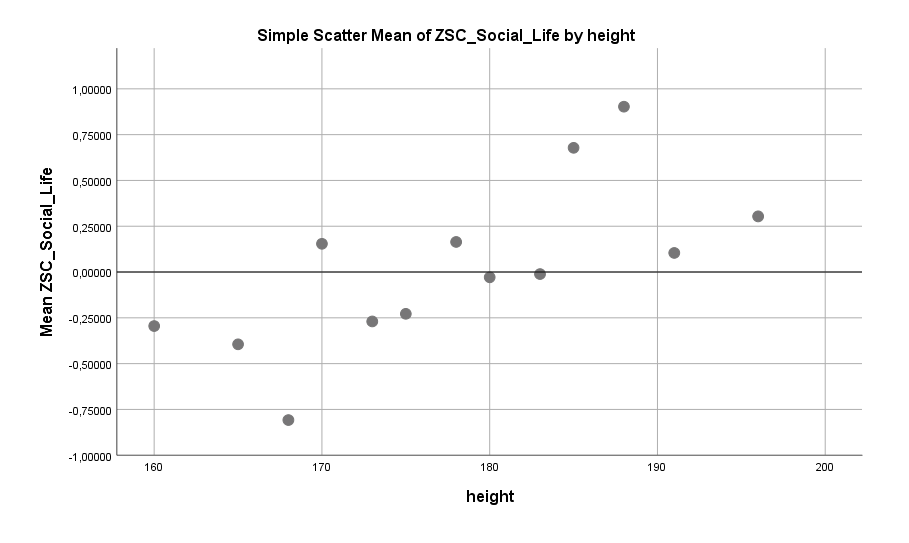
Körpergröße und berichtete Beziehung zu Freunden, Größe des Bekanntenkreis und Häufigkeit des Treffens von Freunden:
Sowohl in den USA als auch in Europa ist Baldrian aufgrund der leicht sedierenden Wirkung eines der beliebtesten Mittel, die bei Schlafproblemen genommen werden. Wie effektiv ist es aber wirklich? Mittlerweile gibt es vier Meta-Studien zum Thema Baldrian und Schlaf, alle zwischen 2006 und 2014 veröffentlicht:
Valerian for Sleep: A Systematic Review and Meta-Analysis
A systematic review of valerian as a sleep aid: Safe but not effective
Effectiveness of Valerian on insomnia: a meta-analysis of randomized placebo-controlled trials
Herbal medicine for insomnia: A systematic review and meta-analysis
Alle vier Meta-Studien stellen fest, dass vorhandene Studien zum Thema Baldrian (wie es oft bei frei verfügbaren Kräutern der Fall ist) im Allgemeinen nur wenig methodisch rigoros waren, was die Bewertung deutlich erschwert. So wurde z.B. das verwendete Baldrian oft unterschiedlich präpariert und verabreicht und nur selten wurde der Schlaf objektiv gemessen. Letzteres ist zwar kein prinzipielles Problem, da sich viele Studien in der Psychologie auf Selbstberichte verlassen müssen, ist aber trotzdem ziemlich schade da es sich beim Schlaf um einen Faktor handelt, der (im Gegensatz zu Aspekten wie Lebenszufriedenheit oder Erschöpfung) durchaus objektiv erfasst werden kann.
Desweiteren stellen zwei der vier Meta-Analysen Beweise für Publication Bias fest. Es ist also zu vermuten, dass viele der Studien zum Thema Baldrian, die keinen Effekt gefunden haben, schlicht in der Schublade der Forscher verschwunden sind. Das lässt sich, sofern eine ausreichende Anzahl Studien vorhanden sind, gut durch die Erzeugung von Funnel Plots ermitteln. Trägt man gefundene Effektstärken über den Umfang der Studien auf (gemessen z.B. an der Anzahl Teilnehmer oder dem Standard Error of the Mean), so sollte sich bei Abwesenheit von Publication Bias eine Trichterform ergeben. Dies liegt daran, dass die größten Studien zu einer mittleren Effektstärke tendieren, während kleinere Studien gleichmäßig links und rechts davon streuen. Eine einseitige Streuung ist ein deutlicher Hinweis dafür, dass Studien mit negativem Resultat nicht oder zumindest seltener veröffentlicht wurden. Dies scheint bei Studien zu Baldrian der Fall zu sein.
Alle vier Meta-Studien finden einen statistisch signifikanten Effekt von Baldrian auf die subjektive Schlafqualität, wobei der Effekt nur bei zwei der vier über die Wirkung eines verabreichten Plazebos hinaus geht. Bei der Einschlafdauer geht die Wirkung von Baldrian bei keiner Meta-Studie über das Plazebo hinaus. Insgesamt darf man daraus schließen, dass Baldrian ohne spezielle Verabreichung also entweder nur die Wirkung eines Plazebos zeigt oder eine Wirkung hat, die nur schwach über ein Plazebo hinaus geht.
Ein effektives Mittel zur Behandlung von Schlafproblemen ist es also nicht, wobei es bei schwachen bis mittelstarken Schlafproblemen aufgrund der Plazebo- oder plazeboähnlichen Wirkung durchaus empfehlenswert sein kann. Bei starken Schlafproblemen, so stellt eine Studie fest, kann Baldrian jedoch sogar schädlich sein und zwar in dem Sinne, dass es die betroffene Person davon abhält, eine effektive Behandlung aufzusuchen.
Ich habe hier den Zusatz “ohne spezielle Verabreichung” angefügt, da durchaus eine Form der Präparation und Verabreichung existieren könnte, die Baldrian zu einem effektiveren Mittel machen würde. Zum Beispiel weist eine der Meta-Studien darauf hin, dass die Verabreichung als Flüssigkeit wohl zu bevorzugen sei. Leider sind die derzeitigen Studien zu Baldrian nicht rigoros genug, um Effekte der Präparation und Verabreichung systematisch analysieren zu können und so bleibt diese Frage offen.
Ich werde Baldrian (neben anderen Lösungsansätzen) weiterhin benutzen. Eine plazeboähnliche Wirkung ist nicht zu unterschätzen und ein vielfältiger Ansatz zur Lösung eines multikausalen Problems ist immer besser als sich auf nur einen Lösungsansatz zu verlassen. Man darf die Macht der Formel “Viel hilft viel” nie unterschätzen.
Nachdem ich hier einen kurzen Überblick darüber gegeben habe, welche Faktoren bei Frauen im Hinblick auf die Frage Single Ja / Nein relevant sind, nun eine Wiederholung der Analyse bei Männern. Alles folgende basierend auf einer Umfrage, welche ich über Harvard Dataverse bezogen habe und aus n = 236 Teilnehmern besteht. Hier das altersbereinigte Modell, welches sich schlussendlich aus den Daten ergeben hat:
Ich möchte die Faktoren Schritt für Schritt durchgehen und dabei den jeweiligen Effekt durch einen Graphen visualisieren. Bei jedem der Graphen gilt: Je niedriger der Punkt liegt, desto niedriger das “Single-Risiko”. Und je weiter rechts, desto mehr ist von der genannten Variable vorhanden. Außerdem: Jeder Graph zeigt den Effekt so, wie ihn die Regression sieht, also bereinigt nach allen anderen Variablen im Modell. Das ist die reinstmögliche Form zur Darstellung des Effekts.
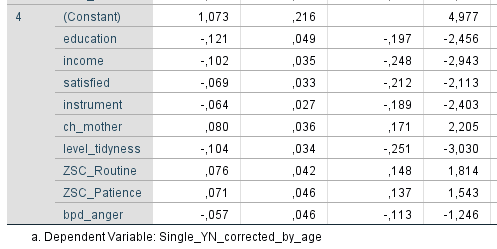
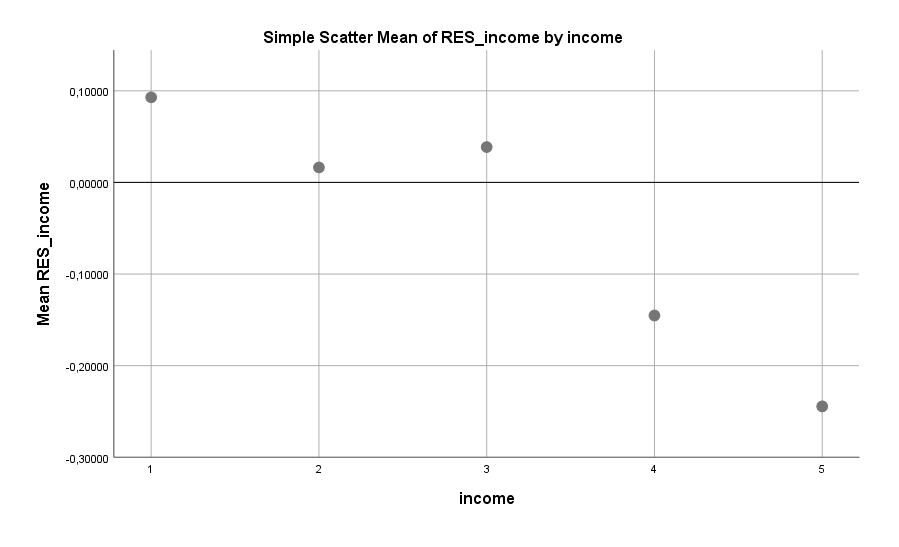
Als ein signifikanter Faktor hat sich das Einkommen erwiesen. Es gilt mit guter Verlässlichkeit: Je höher das Einkommen eines Mannes, desto geringer das Risiko Single zu sein. Die mögliche Angabe des Einkommens (Netto) erfolgte in Schritten von $ 25.000. Also Stufe 1 bedeutet $ 0 bis $ 25.000 pro Jahr, Stufe 2 entspricht $ 25.000 bis $ 50.000 pro Jahr, usw …
Dieser Effekt dürfte nicht überraschen, denn ein hohes Einkommen gewährleistet eine sichere Versorgung im Falle einer Familiengründung, bei welcher die Frau trotz aller Fortschritte bei der Gleichberechtigung zumindest für ein paar Monate den eigenen Beruf ruhen lassen muss. Das Einkommen bietet natürlich auch darüber hinaus einem potentiellen Nachwuchs viele Sicherheiten und Vorteile.
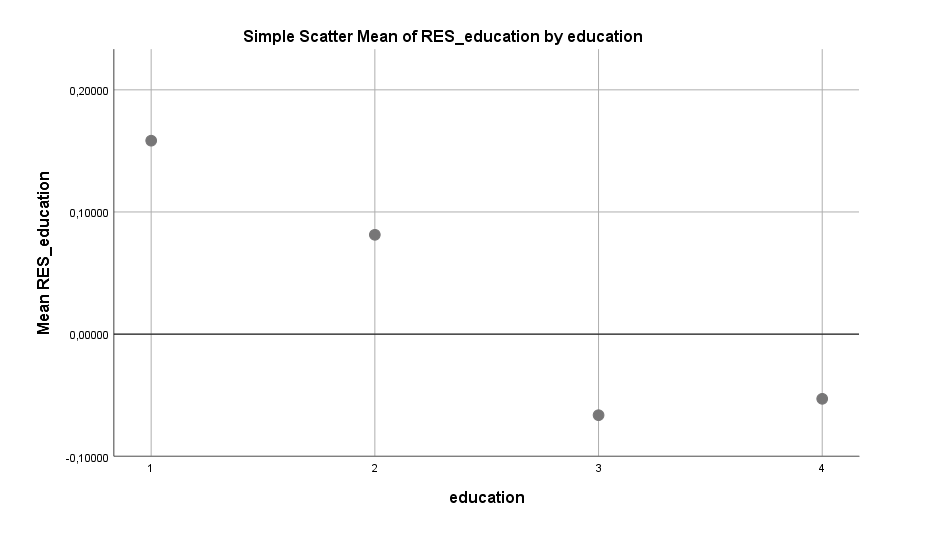
Neben einem hohen Einkommen scheint auch, und das ganz unabhängig vom Einkommen, der Bildungsgrad eine Rolle zu spielen. Der Effekt ist sehr interessant, weil dieser bei Männern in die entgegengesetzte Richtung wie bei den Frauen geht. Laut dem gleichen Datensatz sind Frauen umso häufiger Single, je höher ihr akademischer Grad ist. Bei Männern gilt jedoch: Je höher der Bildungsgrad, desto seltener Single.
Es gibt hier viele mögliche Interpretationen. Man könnte, trotz Bereinigung, wieder den Bogen zum Einkommen schlagen, da Bildung in gewisser Weise “verzögertes Einkommen” darstellt. Eine hohe Bildung heute bedeutet i.d.R. ein hohes Einkommen morgen. Oder man könnte beide Aspekte, Einkommen und Bildung, unter dem Begriff Status zusammenfassen und hier von einer Status-Wirkung sprechen. Oder es kann auch sein, dass Frauen Männer bevorzugen, die ihren Intellekt unter Beweis gestellt haben. Jede dieser möglichen Erklärung ist so spekulativ wie die nächste. Entsprechend sollte man keine in Stein gemeißelt sehen. Die Regression sagt nur: Mehr Bildung, seltener Single. Gründe liefert sie keine.
In diesselbe Richtung wie bei Frauen geht aber der Effekt der allgemeinen Lebenszufriedenheit. Bei beiden Geschlechtern gilt: Je zufriedener, desto seltener als Single anzutreffen. Diese Formulierung ist sehr gezielt gewählt da auch hier die Huhn-Ei-Frage offen bleibt. Aber wahrscheinlich gelten beide Richtungen: je zufriedener als Single, desto einfacher findet sich ein Partner. Und gibt es einen Partner im Leben, ist man auch zufriedener.
Lustig finde ich den nächsten Faktor, vor allem da er in einer ordentlichen Stärke auftritt: Musikinstrument. Männer, die angeben häufig auf einem Musikinstrument zu spielen, sind merklich seltener Single als Männer, die kein Instrument spielen. Lassen sich Frauen “einlullen”? Oder gibt es eine andere plausible Erklärung? Was auch immer die Erklärung sei, Musik hält den Geist fit und bringt Freude. Insofern lohnt es sich immer, ein Instrument zu lernen, ob nun zum Einlullen oder nicht.
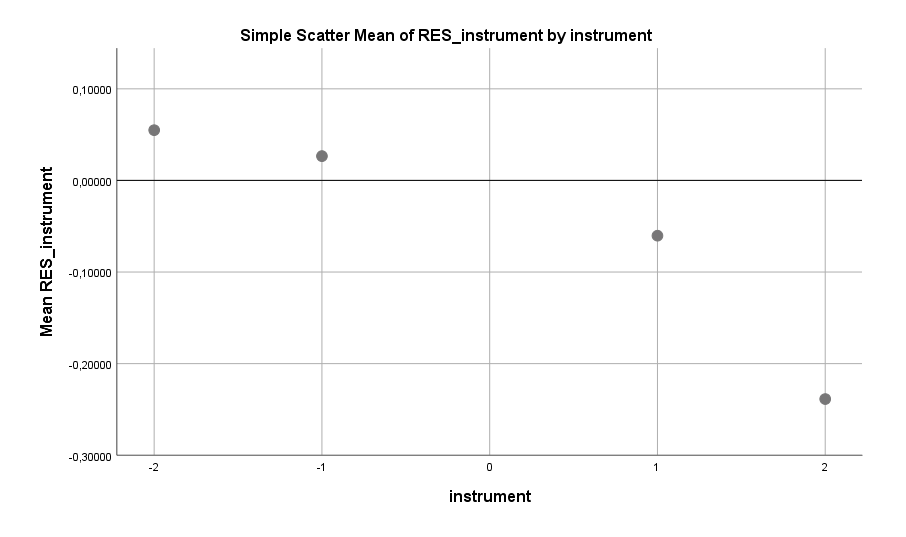
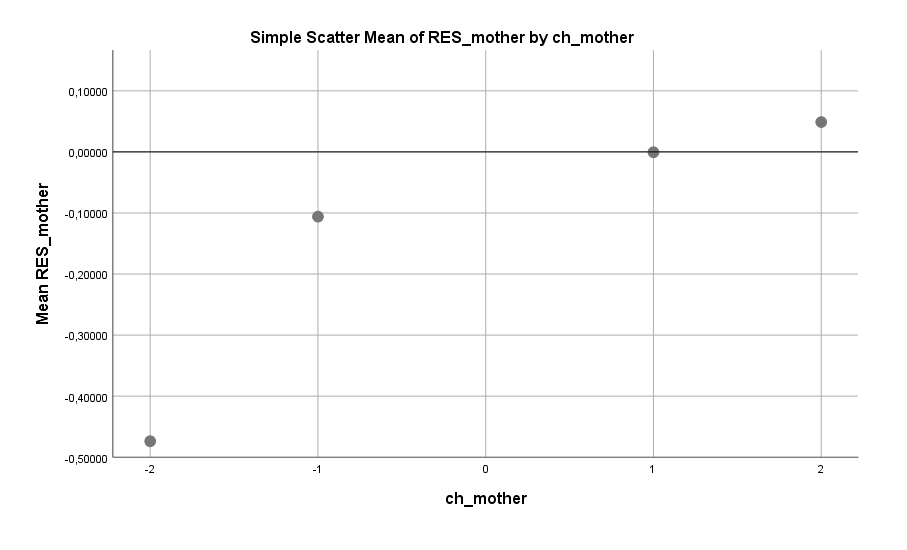
Auch interessant war der folgende Faktor: die Beziehung zur Mutter (im Kindesalter). Männer mit einer sehr schlechten Beziehung zur Mutter befinden sich deutlich häufiger in einer Beziehung als Männer mit einer mäßig schlechten bis sehr guten Beziehung. Das drängt eine dreiste Spekulation auf: Möchten diese Männer die Abwesenheit der Mutter durch das Hineinstürzen in und festhalten an Beziehungen kompensieren? Das ist eine naheliegende Interpretation, aber auch andere Erklärungsansätze sind denkbar.
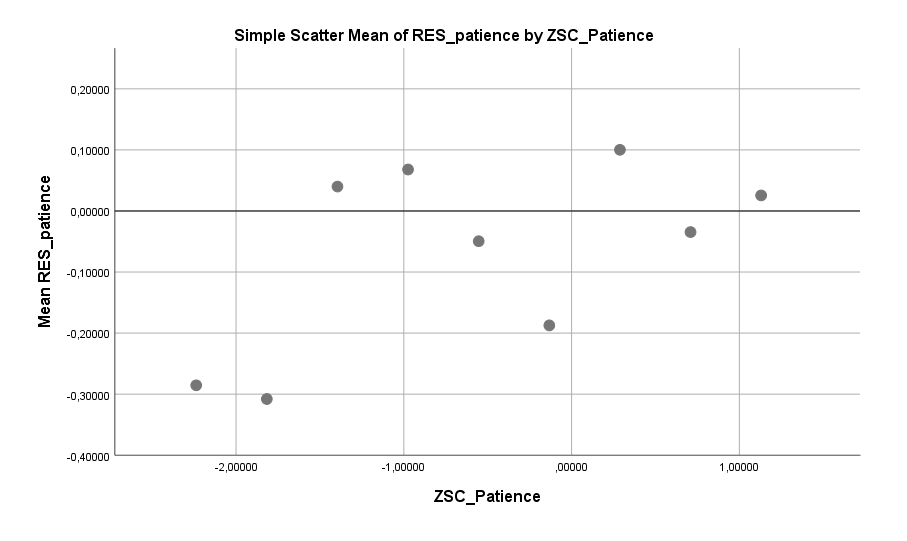
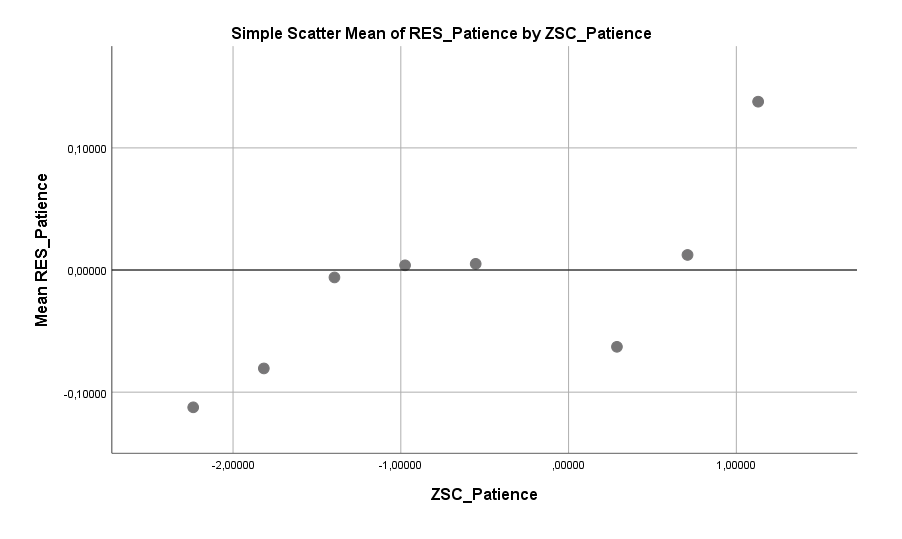
Weiter geht es mit dem Faktor Geduld, der sich schon bei Frauen gezeigt hat. Auch bei Männern gilt: zuviel Geduld kann nach hinten losgehen. Beziehungsweise, wenn man sich den Graphen einmal genauer anschaut, scheint hier eher zu gelten: Viel Ungeduld geht nach vorne los! Mäßig geduldige bis sehr geduldige Männer zeigen in etwa dasselbe Single-Risiko, bei sehr ungeduldigen Männern scheint dies aber merklich reduziert. Schnell vorzupreschen macht sich, zumindest im Mittel, bezahlt.
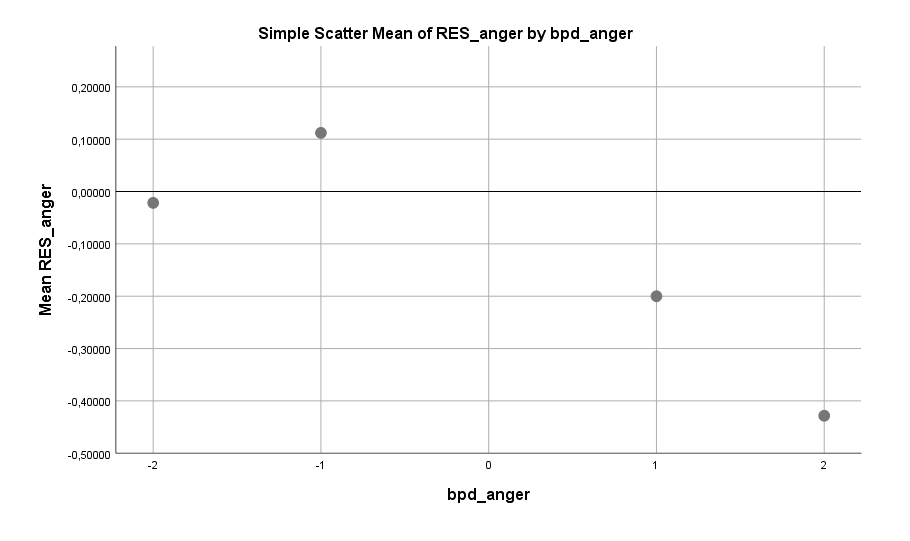
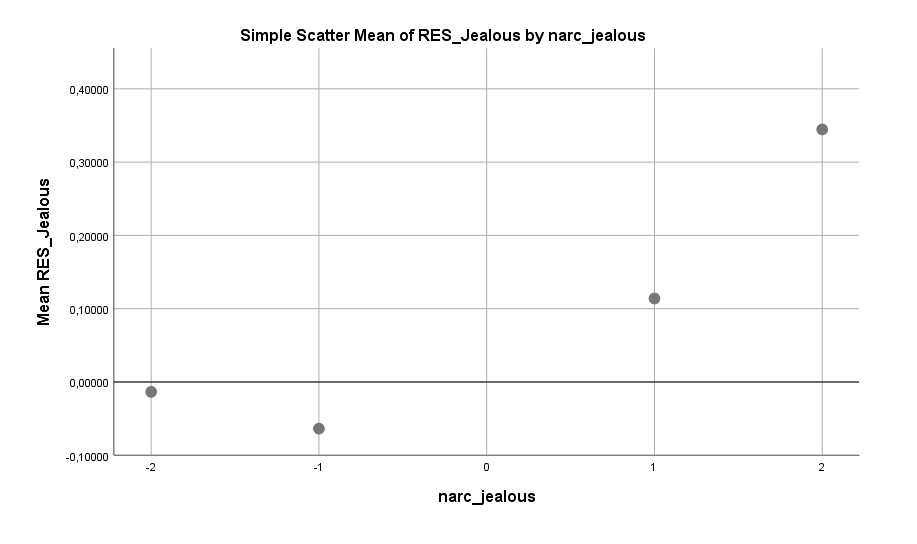
Wut jedoch nicht. Generell gilt, bei Männern wie bei Frauen, dass Borderline-Symptomatiken in der Summe kein erhöhtes Single-Risiko bringen. Aber auch bei Männern gibt es genau eine Symptomatik, die doch einen Effekt zeigt, nämlich Wutausbrüche. Wobei diese selbstverständlich ganz ohne Borderline auftauchen können. Männer, die berichten häufig Wutausbrüche zu haben, sind häufiger als Single anzutreffen. Oder sind sie wütender, weil Single? Wie bei der Zufriedenheit ist es wohl beides.
Hier zeigt ein Vergleich mit dem Regressionskoeffizienten, dass dieser nicht immer die Stärke eines Effektes gut erfasst. In der Regel ist dies bei einem nichtlinearen Verlauf der Fall. Es lohnt sich stets auch die Spannweite zu betrachten, die bei der Wut von +0,1 bis -0,4 reicht, also insgesamt 0,5 Einheiten umfasst. Trotz des niedrigen Koeffizienten kann der Effekt also in der Stärke mit den vorherigen Effekten konkurrieren.
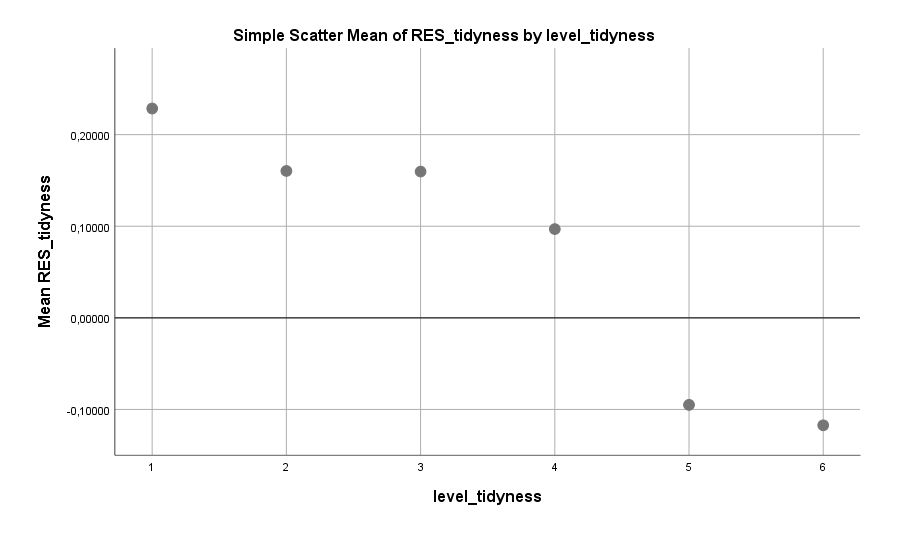
Bleibt die Ordentlichkeit der Wohnung als letzter relevanter Faktor. Diesen habe ich etwas aufgeschoben, da hier die Situation noch verworrener als zuvor ist. Männer, die angeben dass sich ihre Wohnung stets auf einem ordentlichen Niveau befindet, haben ein geringeres Single-Risiko als jene, die ihre Wohnung desöfteren schleifen lassen.
Klingt vernünftig, aber Achtung: Ist die Wohnung der Männer, die in einer Beziehung sind, vielleicht oft deshalb so ordentlich, weil sie eine Frau an der Seite haben, die die Wohnung zumindest kritisch beäugt? Und oft gar mit in Schuss hält? Es ist also nicht ganz klar, was der vorliegende Zusammenhang wirklich ausdrückt. Wahrscheinlich eine Mischung aus der Ordentlichkeit des Mannes und dem Vorhandensein einer helfenden Hand.
Für die Verlässlichkeit des Modells gilt, bezüglich dem Entfernen von Ausreißern sowie der Reproduzierbarkeit, alles was ich in dem entsprechenden Blog-Eintrag über Frauen erwähnt habe. Die Verlässlichkeit des Modells ist insgesamt zufriedenstellend. Zusammengenommen erklären die oben genannten Faktoren etwa 40 bis 50 % der erklärbaren Varianz in der Variable “Single Ja / Nein” und erzählen somit etwa die Hälfte der Geschichte. Auch das ist ziemlich zufriedenstellend.
Dieser Blog-Eintrag wird etwas umfangreicher und hat auch einiges an Vorbereitung benötigt, aber es hat sich gelohnt. Nach mehreren gescheiterten Ansätzen konnte ich einem Datensatz mit n = 265 Umfrageteilnehmer doch noch ein Modell entlocken, das zeigt welche Faktoren bei Frauen das “Risiko” des Single-Seins steigern bzw. senken. Ich will jeden Faktor durchgehen und am Ende kurz betrachten, wie verlässlich die Resultate wohl sind.
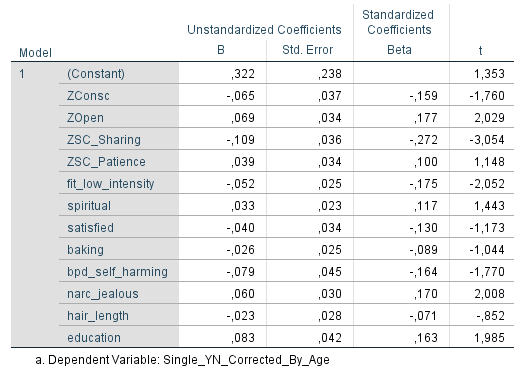
Hier die Regressionstabelle (nach Alter bereinigt):
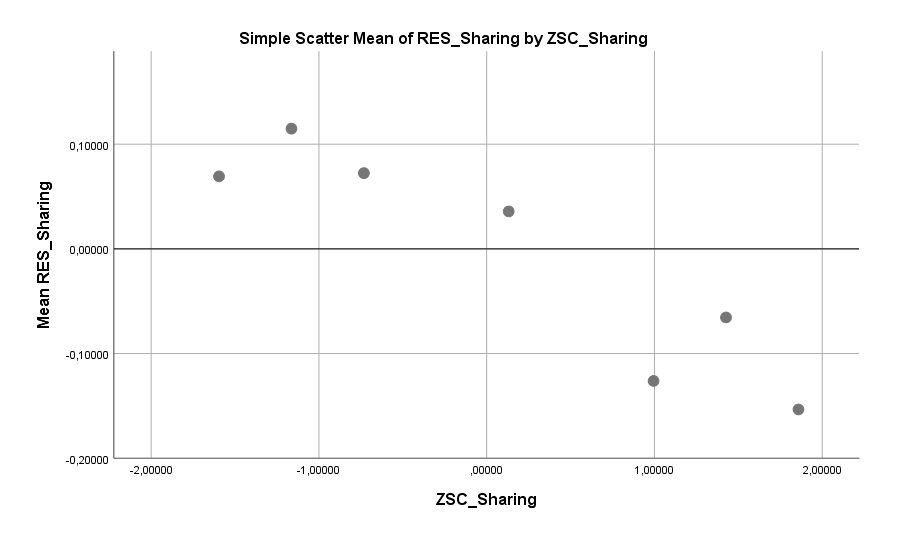
Ich gehe die Faktoren der Effektstärke nach durch. Den stärksten Einfluss, gemessen am standardisierten Regressionskoeffizienten (nicht immer auch der Effekt mit der größten Spannweite – siehe unten), hat die Variable Sharing. Diese Variable ist der Mittelwert dreier Fragen, die alle darauf abzielen zu ermitteln, wie häufig und frei eine Umfrageteilnehmerin mit nahestehenden Personen über die eigenen Probleme und Gefühle redet. Also wie willig eine Person Probleme und Gefühle teilt. Die Daten sagen: Je mehr sich eine Teilnehmerin anderen mitteilt, desto geringer die Wahrscheinlichkeit, dass sie Single ist.
Bei jedem der folgenden Graphen gilt: Je niedriger der Punkt, desto niedriger das “Single-Risiko”. Und je weiter rechts, desto mehr ist von der genannten Variable vorhanden. Außerdem: Jeder Graph zeigt den Effekt so, wie ihn die Regression sieht, also bereinigt nach allen anderen Variablen im Modell. Das ist die reinstmögliche Form zur Darstellung des Effekts. Der Graph zeigt also dass je mehr eine Teilnehmerin sich anderen mitteilt (Richtung rechts), desto weniger Single-Risiko (Richtung unten).
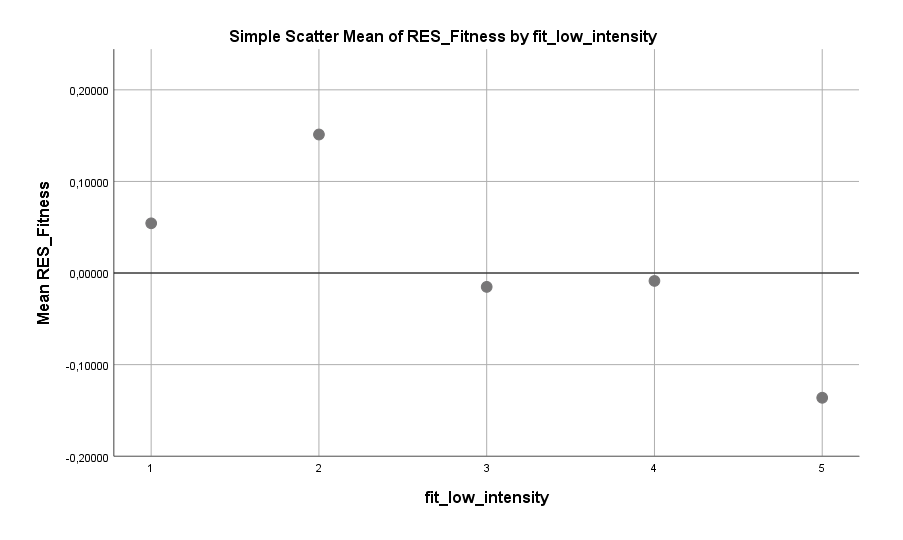
An Stelle zwei ist Fitness, wobei interessanterweise nur die Low Intensity Fitness (viel bequemes Laufen) relevant war. Mid Intensity und High Intensity Fitness war weder im positiven noch im negativen mit dem Single-Sein assoziiert. Wenig überraschend gilt: Je mehr Bewegung, desto geringer die Wahrscheinlichkeit des Single-Seins. Hier ist wohl implizit auch die Körperform enthalten, die explizit im Datensatz leider nicht abgefragt wurde, sowie das allgemeine Aktivitätsniveau.
Frauen mit viel Offenheit für neue Ideen und Erfahrungen, eine Dimension die eng verbunden ist mit intellektueller Neugier und Kunstaffinität, scheinen sich häufiger im Single-Leben zu befinden als ihre weniger offenen Geschlechtsgenossinnen. Das könnte vielleicht daran liegen, Achtung Spekulation, dass ihnen die engen Grenzen und Routinen einer Beziehung nicht so sehr zusagen. Eine stagnierende Beziehung bietet nur wenig intellektuelle Stimulation und nur wenig Raum für neue Erfahrungen. Man kann also leicht einsehen, dass ein solcher Drang hinderlich für das Niederlassen in fixe Routinen sein kann.
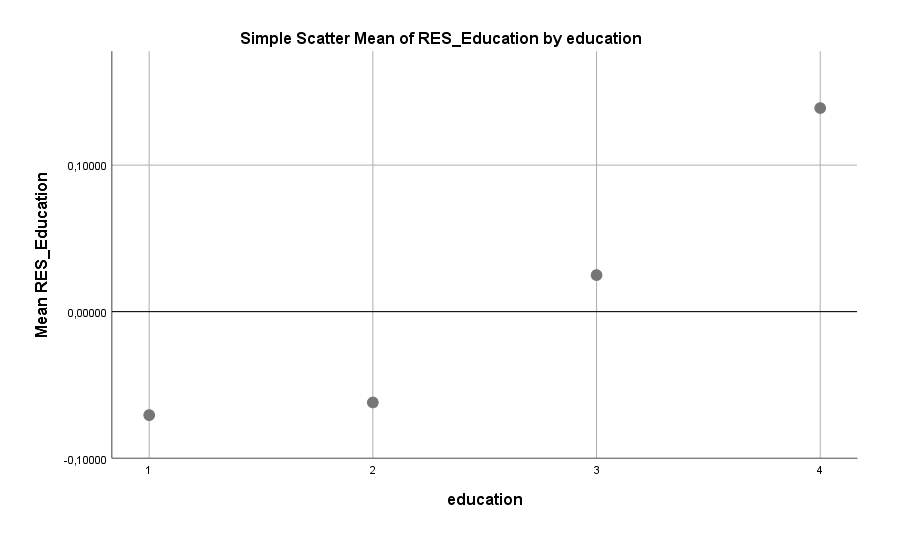
Auch ein hoher Bildungsgrad ist mit mehr Single-Sein assoziiert. Die in der Umfrage ermittelten und unten abgebildeten Stufen sind: 1 = Keine Universität, 2 = Universität besucht, aber kein Bildungsabschluss, 3 = Bachelor-Grad und 4 = Master- oder Doktor-Grad. Wichtig ist der Hinweis, dass Bildung und Offenheit zwar allgemein eng korrelieren, aber der hier gezeigte Effekt des Bildungsgrades sich nicht (!) durch Offenheit erklären lässt. Bei der Ermittlung der Effektstärke bereinigt das Statistik-Programm automatisch nach allen anderen Variablen im Modell, inklusive der Offenheit. Es handelt sich hier also um einen separaten Effekt.
Ein weiterer Faktor ist das Big-Five-Merkmal Ordentlichkeit, welches neben dem, was das Wort schon ausdrückt, auch beschreibt, wie verlässlich eine Person im Allgemeinen ist. Ordentliche und verlässliche Frauen sind in der Tendenz seltener Single, was in diesem Fall womöglich daran liegt, dass diese Qualitäten von einem potentiellen Partner geschätzt werden. Schließlich muss das Zusammenleben organisiert und gemeinsame Pläne verwirklicht werden. Dem kommt die Ordentlichkeit natürlich entgegen.
Nun zur allgemeinen Lebenszufriedenheit. Frauen in einer Beziehung fühlen sich zufriedener. Oder ist es so, dass zufriedene Frauen leichter einen Partner finden? Hier ist es schwierig eine Richtung zu sehen. Sehr wahrscheinlich ist es beides. Ein Teil der Zufriedenheit ist in der emotionalen Stabilität verankert, welche sich schon vor dem Alter von fünf Jahren etabliert. Das spricht für die Richtung: Besteht Zufriedenheit im Leben, dann klappt es mit der Liebe. Aber mit der Liebe klappen kann, unabhängig von dem Maß an emotionaler Stabilität, der Zufriedenheit auch einen ordentlichen Boost geben. Eine scharfe Trennung von Ursache und Wirkung ist hier jedenfalls nicht möglich (und wohl auch nicht nötig).
Hier ein beruhigender Effekt: Frauen, die schnell neidisch werden wenn jemand anderes ein besseres Auto / Haus oder einen schöneren Partner hat, was auch immer das sein mag, scheinen recht unbeliebt bei Männern zu sein. Neid bringt Single-Risiko und das ganz saftig. Es ist aber das einzige abgefragte Narzissmus-Merkmal, das sich negativ auf Beziehungschancen auswirkt. Insgesamt gilt, dass eine narzisstische Ader bei Frauen weder hinderlich noch förderlich bei der Partnersuche ist.
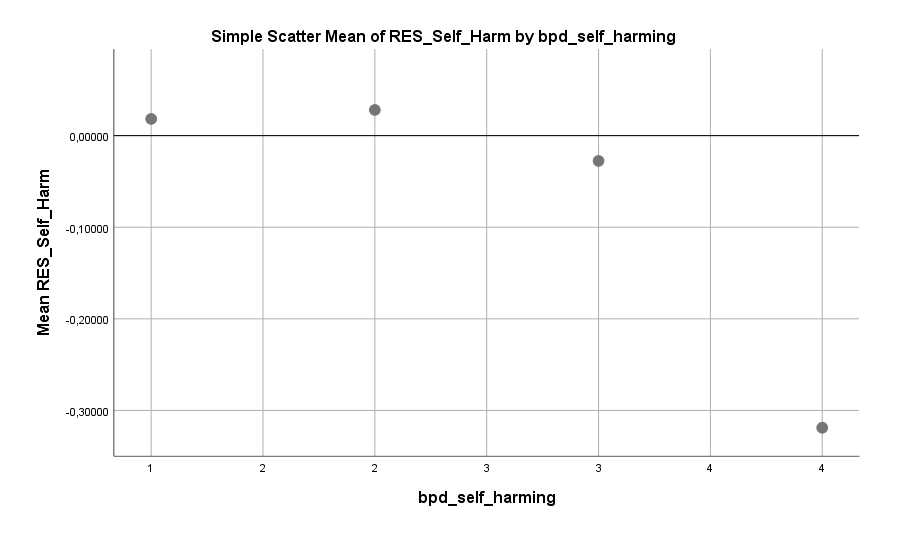
Ähnliches gilt auch für die abgefragten Borderline-Merkmale. Zumindest bereinigt nach den anderen Variablen, vor allem ist hier die Ordentlichkeit zu nennen, zeigt der Score auf der verwendeten Borderline-Skala keinen Zusammenhang mit dem Single-Sein. Bis auf eine Ausnahme: Selbstverletzung. Frauen, die berichten sich selbst verletzt zu haben, sind deutlich seltener in einer Beziehung. Hier sind die Stufen: 1 = Noch nie nah an der SV gewesen, 2 = Manchmal daran gedacht, aber nie gemacht, 3 = SV gemacht, aber nur oberflächliche Wunden und 4 = SV mit tiefen Wunden.
Interessant ist, dass der Zusammenhang nur bei tiefen Wunden gilt. Frauen, die sich in der Vergangenheit oberflächliche Wunden zugefügt haben, sind genauso häufig in einer Beziehung wie jene, die sich nie selbst verletzt haben. Hier könnte also, Achtung Spekulation, die Scham eine Rolle spielen. Oberflächliche Wunden sind nach einigen Monaten und Jahren kaum mehr zu erkennen und somit besteht kein Hinderungsgrund, die betroffenen Hautpartien zu zeigen. Tiefe Wunden, unabhängig davon wo sich diese befinden, werden aber immer Fragen aufwerfen. Das Zeigen solcher Hautpartien benötigt somit ohne Zweifel viel Überwindung.
In der Umfrage wurden die Teilnehmer auch gebeten zu sagen, an welche der folgenden übernatürlichen Phänomene sie glauben: Geister, Hellseher, Telepathen, Horoskope. Das Ergebnis wurde als Maß für die Spiritualität verwendet, welche auch eine geringe Verbindung zum Single-Sein zeigt. Frauen, die der Spiritualität nahe stehen, scheinen häufiger Single zu sein.
Wieso? Vielleicht liegt es daran, dass Frauen generell eine stärkere Tendenz zur Spiritualität haben als Männer (das zeigt auch diese Umfrage) und es für einen potentiellen männlichen Partner entsprechend schwierig ist, diesen Glauben nachzuvollziehen. Sympathie ergibt sich zu einem großen Teil aus Ähnlichkeit und so kann man einsehen, dass die Unähnlichkeit beim Thema Spiritualität einen potentiellen Partner verschrecken könnte.
Ein weiterer Faktor ist wohl auch Geduld. Prinzipiell eine sehr positive Eigenschaft, scheint sich zu viel Geduld jedoch negativ bei der Beziehungssuche auszuwirken. Laut den Daten sind geduldige Frauen jedenfalls etwas seltener in Beziehungen anzutreffen als ihre geständig-ungeduldigen Geschlechtsgenossinnen. Mag sein, dass diese Frauen zu geduldig waren, als es darauf ankam, einen Impuls zu geben.
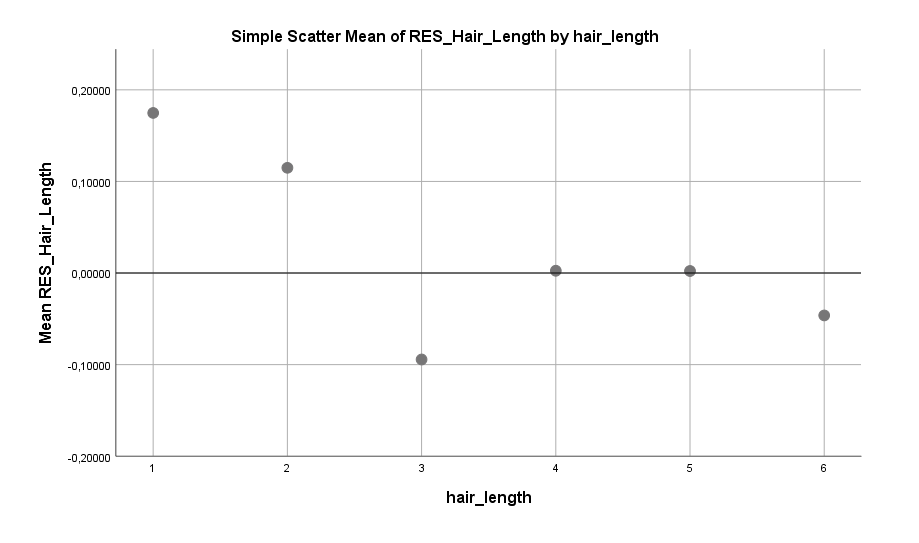
Ein weiterer relevanter Faktor scheint die Haarlänge zu sein. Sehr kurze Haare kommen bei einem potentiellen männlichen Partner wohl nicht so gut an. Zumindest sagen die Daten, dass Frauen mit kurzen Haaren häufiger Single sind als Frauen mit mittellangen oder langen Haaren.
Man beachte dass die Spannweite des Effekts recht groß ist und das trotz des geringen Koeffizienten, mit dem der Effekt in der Tabelle aufgelistet ist. Generell ist der Regressionskoeffizient ein verlässliches Maß für die Stärke eines Effektes. Jedoch kann es zu Verzerrungen kommen, wenn der Verlauf der Kurve sehr nichtlinear ist. So wie hier zum Beispiel, wo ein exponentieller Fit den Verlauf wohl um einiges besser beschreiben würde.
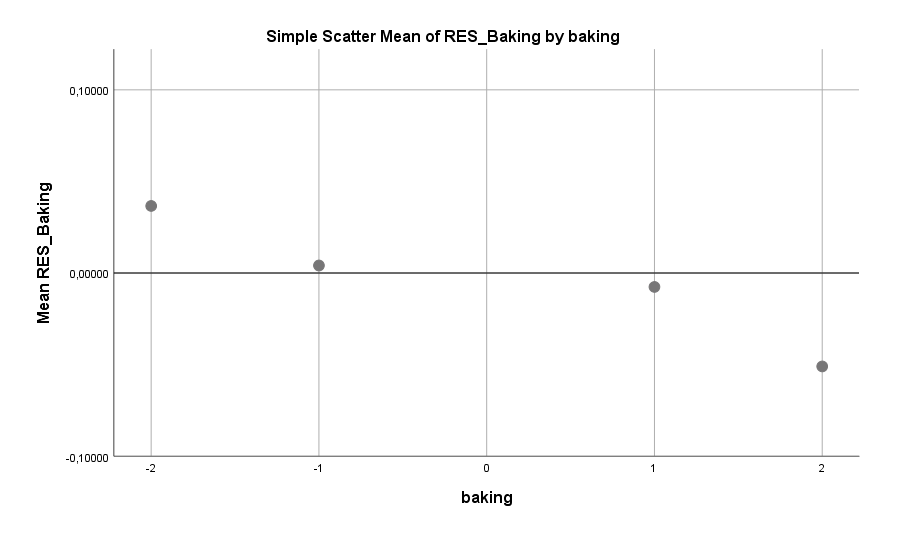
Zuletzt ein Effekt, der sehr schwach ist, aber konsistent und interessant genug war um ihn doch noch ins Modell aufzunehmen. Der Volksmund sagt bekanntlich, dass Liebe durch den Magen geht. Und eventuell ist an dieser Weisheit auch etwas dran. Frauen, die angeben gerne zu backen, zeigen in der Umfrage auch ein leicht reduziertes Single-Risiko.
Ingesamt erklären die obigen Faktoren insgesamt etwa 30-40 % der Varianz in der Variable “Single Ja / Nein”. Plump gesagt zeigt es weniger als die Häfte der Geschichte. Was nicht überraschend ist, da Sympathie und Attraktivität im Allgemeinen sehr individuell sind. Die spezifische und somit einzigartige Kombination zweier Individuen macht eine Beziehung und so etwas lässt sich durch eine Umfrage nicht erfassen. Es hilft nichts, ordentlich, fit und zufrieden zu sein, wenn die spezifische Kombination mit der anderen Person nicht passt. Und oft ist auch egal, chaotisch, bequem und unzufrieden zu sein, wenn die Kombination doch passt.
Wie oben angedeutet, gilt alles Gesagte bereinigt nach dem Alter. Es gibt einen typischen Verlauf des Single-Seins mit dem Alter, bei Frauen scheint dies eine U-Kurve zu sein mit einem Single-Risiko-Minimum zwischen 30-50 Jahren, aber bei der obigen Betrachtung war die Frage stets: “Neben dem Alter, was noch?”. Dies war alleine schon deshalb nötig, weil der Altersverlauf sehr nichtlinear ist und die direkte Aufnahme des Alters in die lineare Regression grobe Verzerrungen gebracht hätte. Somit wurde die Variable “Single Ja/Nein” zuerst durch eine nichtlineare (parabolische) Regression bereinigt und diese Variable dann als unabhängige Variable in der linearen Regression verwendet. Der parabolische Fit war recht gut.
Wie verlässlich ist das Modell? Um eine größtmögliche Verlässlichkeit zu gewährleisten, wurden zuerst bei den individuellen Skalen alle Ausreißer mit einer absoluten Entfernung von mehr als drei Standardabweichungen zum Mittelwert gelöscht und danach alle einflussreichen Ausreißer in der gesamten Regression, jene mit einer Cook’s Distance größer als dreimal des Mittelwerts (so wie hier als Faustregel empfohlen), entfernt. Somit besteht nicht die Gefahr, dass einzelne Antwortfälle einen ungewöhnlich hohen Einfluss auf das Modell auswirken.
Laut einem Post-Hoc-Rechner liegt die Statistical Power, ein Maß für Reproduzierbarkeit, für die Umfrage und Regression bei etwa 93 %. Man darf also annehmen, dass bei den stärksten Effekten (Absolutwert des Koeffizienten > 0.15) die Reproduzierbarkeit gewährleistet ist. Bei den Effekten, die schwächer sind als dieser Grenzwert, darf man auch optimistisch sein, von Gewährleistung würde ich hier jedoch nicht sprechen. Insgesamt ist die Verlässlichkeit zufriedenstellend.
Sowohl für Frauen und für Männer gilt: Je höher das Einkommen, desto geringer die Wahrscheinlichkeit des Single-Seins. Und das gilt explizit auch bereinigt nach Alter und Persönlichkeit. Genauer gesagt spielt die Persönlichkeit (gemessen an den Big-Five-Merkmalen) praktisch keine Rolle dabei, ob jemand einen Partner findet oder nicht. Das kann man als eine statistische Bestätigung der alten Weisheit “Auf jeden Topf passt ein Deckel” sehen. Alles basierend auf n = 1860 Teilnehmer, was einem ziemlich großen Sample entspricht.
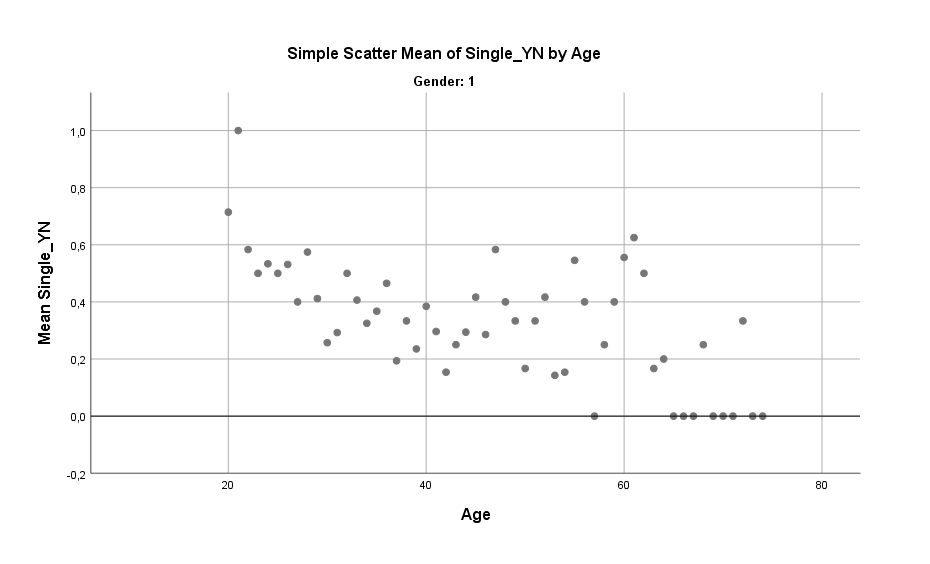
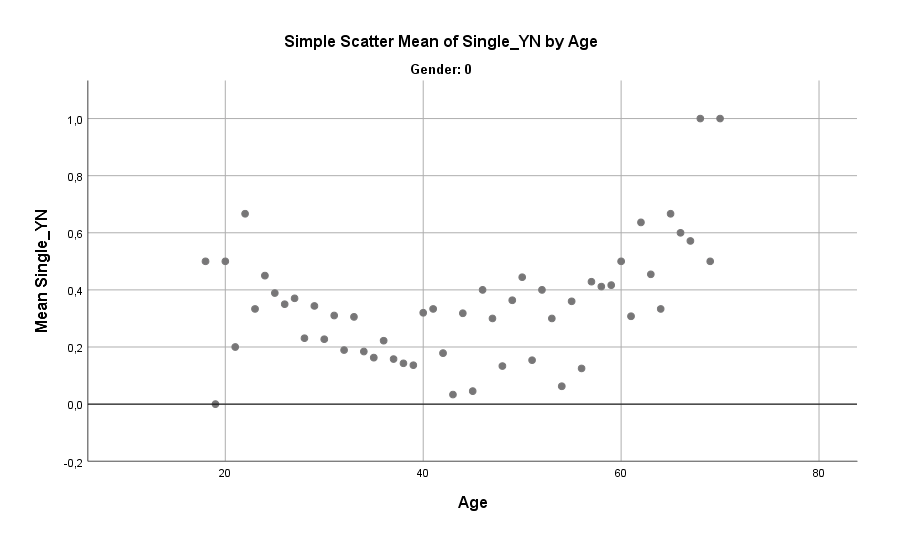
Zuerst aber mal einen Blick auf das Alter. Bei Männern gibt es einen klaren Trend: Je älter, desto weniger Single. Während Anfang 20 der Anteil Singles bei etwa 50 % liegt, reduziert sich dieser Anteil bis zum Alter 40 stetig und bleibt dann in der Spanne von 40-60 Jahren etwa konstant bei 30 %. Danach fällt es weiter ab auf gemittelt etwa 10 % und weniger.
Bei Frauen ergibt sich eine merklich verschiedene Kurve. Anfang 20 sind nur etwa 30 % der Frauen Single (weniger als bei Männern des gleichen Alters) und das reduziert sich bis zum Alter 40 noch weiter auf etwa 20 % (auch weniger als bei den Männern). Hier gilt ebenso, dass der Anteil zwischen 40 und 60 Jahren recht konstant auf etwa 30 % bleibt. Ab dem Alter 60 Jahren steigt der Anteil Singles bei den Frauen jedoch deutlich an, auf 50 % und mehr (verglichen mit 10 % und weniger bei den Männern).
Bei den Frauen zeigt sich also eher eine U-Kurve, was zu einem großen Teil sicherlich daran liegt, dass Männer eine geringere Lebenserwartung haben und zudem in der Beziehung i.d.R. etwas älter sind als die Partnerin. Eine geringere Lebenserwartung von 5 Jahren und gleichzeitig 5 Jahre älter sein als die Partnerin ergibt im Mittel 10 Jahre früher sterben als die Partnerin. Man kann es auch so sehen: Für Männer wird das frühere Sterben damit ausgeglichen, dass sie zumindest viel seltener als Single sterben.
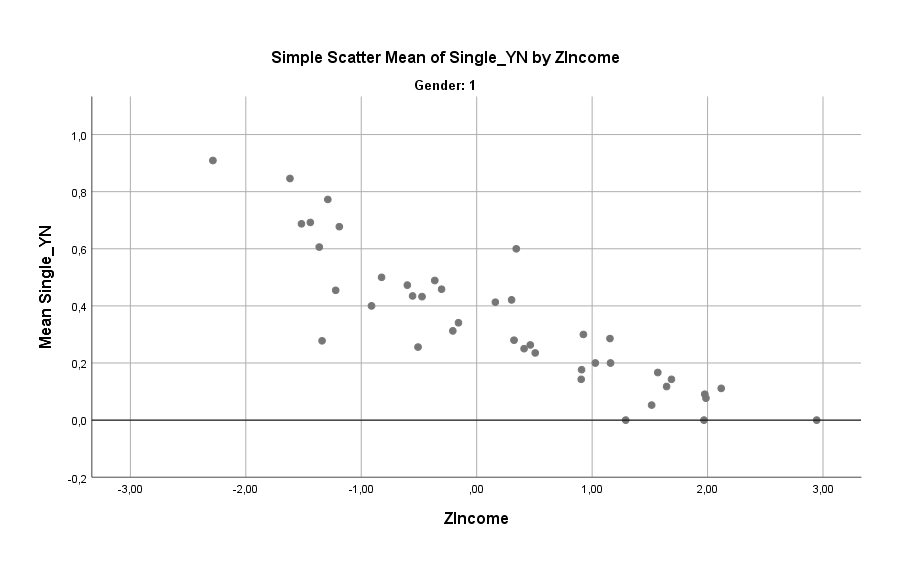
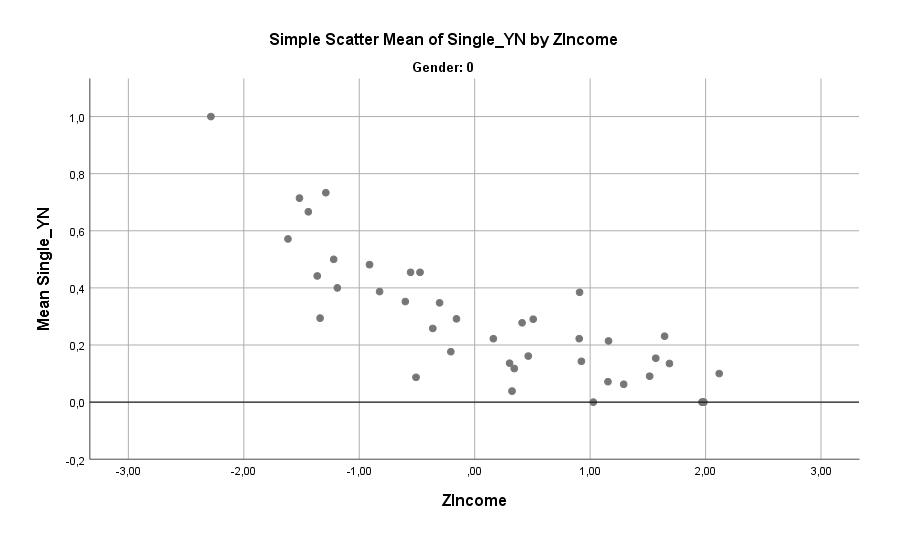
Das Einkommen spricht bei beiden eine sehr deutliche Sprache. Viel Einkommen zerstört das schöne Single-Leben. Hier der Graph zuerst für Männer und dann für Frauen, mit dem expliziten Hinweis dass der unten abgebildete Effekt auch bereinigt nach Alter und Persönlichkeit sehr stark bestehen bleibt:
Das Einkommen ist mit Abstand der beste Prediktor für die Frage ob Single Ja oder Nein. Trotz des deutlichen Zusammenhangs sollte man jedoch den Einfluss sowohl des Alters als auch des Einkommens nicht überschätzen. Denn insgesamt besitzen die beiden Faktoren nur relativ wenig an Erklärungskraft. Hier eine Schätzung, wieviel Prozent möglicher Varianz die obigen Faktoren erklären. Bei Männern sieht es so aus:
Alter: 3 % der Varianz
Einkommen: 17 % der Varianz
Persönlichkeit: 0.5 % der Varianz pro Merkmal
Zusammengenommen: 21 % der Varianz
Und bei Frauen:
Alter: nur schlecht abschätzbar (*)
Einkommen: 12 % der Varianz
Persönlichkeit: 0.2 % der Varianz pro Merkmal
Zusammengenommen: nur schlecht abschätzbar (*)
(*) Aufgrund der Nichtlinearität des Zusammenhangs
Großzügig gesprochen erklärt das Alter und Einkommen wohl bis zu 25 % der möglichen Varianz, was sicherlich nicht zu vernachlässigen ist, jedoch auch sehr viel Spielraum offen lässt für andere Einflüsse, wie zum Beispiel die Erfahrungen in der Kindheit (womöglich insbesondere das Bindungsschema) und Aspekte der Lebensführung. Die Persönlichkeit erklärt, wie schon zuvor angemerkt, praktisch nichts an Varianz, aber geht man von der Topf-Deckel-Hypothese aus, ist das auch nicht überraschend.
Es gäbe hier viele Warnungen anzubringen, ich belasse es aber dabei hinzuweisen, dass die obige Erklärungskraft sogar noch deutlich überschätzt sein könnte, trotz bestem Wissen und Gewissen. Dies liegt daran, dass man die Regression “zwingt” die vorhandene Varianz mit einer niedrigen Anzahl an Variablen zu erklären. Diese Variablen können somit auch Varianz “aufsaugen”, die andere Variablen eigentlich viel besser erklären könnten. Etwas banaler gesagt: Regressionskoeffizienten tendieren dazu anzusteigen, wenn man Variablen aus dem Modell entfernt und so überschätzt man leicht den Einfluss der Variablen, die noch im Modell verbleiben.
TL;DR: Reich oder 40 Jahre alt zu sein macht definitiv weniger Single, aber des Rätsels Lösung ist es nicht. Und die Sache mit dem Topf und Deckel stimmt wohl – kein Persönlichkeitsmerkmal bringt messbare Nachteile.