Das Space-Shuttle hatte gerade genug Treibstoff, um einen niedrigen Orbit (LEO = Low Earth Orbit) zu erreichen und etwas später mit einem kurzen Deorbit-Burn die Atmosphäre anzukratzen. Das Starship von SpaceX steht etwas besser da, aber nicht viel besser. Mit den Trockenmassen, Treibstoffmassen sowie den spezifischen Impulsen der beiden Stufen lässt sich relativ leicht berechnen, wieviel Delta-V (und somit Reichweite für alles weitere) nach Erreichen eines LEO übrig bleibt.
Erste Stufe (Booster): Trockenmasse = 180 t, Treibstoffmasse = 3600 t, Isp = 340 s
Δv = 4,0 km/s (praktisch unabhängig von zusätzlicher Payload-Masse)
Zweite Stufe (Starship): Trockenmasse = 100 t , Treibstoffmasse = 1200 t , Isp = 365 s
Δv = 8,6 km/s (bei 20 t Payload)
Δv = 7,9 km/s (bei 50 t Payload)
Δv = 7,0 km/s (bei 100 t Payload)
Das gesamte verfügbare Delta-V ab Start ist also:
Δv = 12,6 km/s (bei 20 t Payload)
Δv = 11,9 km/s (bei 50 t Payload)
Δv = 11,0 km/s (bei 100 t Payload)
Abzüglich der 9,5 km/s, die benötigt sind, um in einen LEO zu kommen:
Δv = 3,1 km/s (bei 20 t Payload)
Δv = 2,4 km/s (bei 50 t Payload)
Δv = 1,5 km/s (bei 100 t Payload)
Soviel Delta-V bleibt dem Starship demnach für weitere Manöver. Wie weit man damit kommt, kann man an folgender Karte erkennen. Man benötigt ab LEO ein Delta-V von 4,8 km/s um in einen Mond-Orbit zu gelangen und ein Delta-V von 6,5 km/s bis hinab zur Mond-Oberfläche. Weit mehr als verfügbar, und das, ohne den Rückweg überhaupt betrachtet zu haben. Der Mars ist unter diesen Vorraussetzungen natürlich auch noch sehr weit außerhalb des Machbaren. Wie geht es weiter?
Jeder Schritt über einen Erdorbit hinaus wird ein Nachtanken im Orbit benötigen, so wie es die Pläne von SpaceX auch vorsehen. Pro Start lässt sich eine Payload-Masse von maximal 180 t in einen LEO bringen, wovon aber 30 t benötigt werden, wenn man anschließend zur Oberfläche der Erde zurückkehren will. Ein Tanker-Spaceship könnte einem Spaceship, welches sich schon in LEO befindet, also 150 t Treibstoff übergeben. Sieben Tanker-Starts würden ausreichen, um ein Spaceship in LEO voll aufzufüllen und somit wieder das komplette Delta-V der zweiten Stufe zu bekommen.
Solche Tanker-Missionen klingen auf den ersten Blick vielleicht etwas wild, aber man muss bedenken, dass Docking im Orbit schon seit Jahrzehnten in der Raumfahrt praktiziert wird und das auch ohne besondere Vorkommnisse. Ein Nachtanken im Orbit wäre ohne Zweifel aufwendig und teuer, aber an dem Know-How oder der Technik würde es nicht scheitern.
Aber, und ab hier wird es richtig problematisch: Zur Mond-Oberfläche und zurück reicht es trotz Nachtanken nicht. Bei voller Nutzung von Aerobraking werden ab einem LEO hierfür circa Δv = 10 km/s benötigt versus den verfügbaren Δv = 8,6 km/s des Starships bei 20 t Payload. Und für eine Reise zum Mars und zurück erst recht nicht (Δv = 14 km/s). Es fehlt in beiden Fällen sogar noch ziemlich viel. Was tun? Für das Weitere hilft es mal zu betrachten, wie weit man auf einer Mars-Mission mit den gegebenen Δv = 8,6 km/s kommen würde:
LEO – TO (Transfer Orbit): 2,5 km/s
LEO – LMO (Low Mars Orbit): 6,1 km/s
LEO – MS (Mars Surface mit Aerobraking): 6,6 km/s
LEO – LMO’ (LMO nach Landung): 10,7 km/s
Eine Landung auf dem Mars wäre demnach gut machbar. Scheitern würde es aber an der anschließenden Rückkehr in einen LMO. Das in LEO betankte Spaceship mit 20 t Payload würde auf der Mars-Oberfläche mit einer Restmasse von 209 t ankommen, hätte also (minus Trockenmasse und Payload) noch 89 t Treibstoff verfügbar. Alleine der Aufstieg zurück in einen LMO würde aber 257 t erfordern, eine Rückkehr zumindest zu einem hohen Erdorbit sogar 809 t. Wie kommt man an den Treibstoff?
Es gibt prinzipiell zwei Wege: Tanker-Missionen zum Mars oder Treibstoff von der Mars-Oberfläche. An Letzterem wird gerade intensiv geforscht und SpaceX baut darauf, dass der Treibstoff vor Ort produziert werden kann. Aber angenommen, das würde scheitern: Wäre dann der Traum vom Mars vorbei? Mit dem Spaceship in jetzigem Design definitiv. Aber mit einer Anpassung im Stile der Apollo-Missionen wäre eine Mars-Mission auch ohne Gewinnung von Treibstoff auf dem Mars machbar.
Nochmal zu dem Spaceship, dass mit einem Payload von 20 t und nur 89 t Treibstoff auf dem Mars gestrandet ist. Eine Tanker-Mission (selbst ein in LEO betanktes Spaceship) könnte 106 t Treibstoff zur Mars-Oberfläche bringen. Etwas mehr als die 89 t des gestrandeten Spaceships, da der Tanker die 20 t Payload nicht mittragen musste. Um das gestrandete Spaceship soweit zu füllen, dass es zumindest wieder in einen hohen Erdorbit kommen kann, wären sieben Tanker-Missionen zum Mars notwendig.
Das klingt erstmal ganz vernünftig, man muss aber bedenken, dass jeder Mars-Tanker selbst im LEO betankt werden muss, um 106 t Treibstoff zum Mars bringen zu können! Pro Tanker-Mission zum Mars sind also acht Spaceship-Starts benötigt: Der Tanker zum Mars und seine sieben LEO-Betankenden. Für sieben Mars-Tanker benötigt man also 8*7 = 56 Spaceship-Starts.
Man sieht daran, dass das Spaceship wirklich um den Gedanken der Gewinnung von Treibstoff vor Ort (sowie Kapazität und Nachhaltigkeit) gebaut ist. Das Spaceship bietet viel Raum für viele Leute. Und es verzichtet auf einen Lander, der sich in Orbit von dem Hauptmodul trennt, zur Oberfläche geht und sich dann beim Aufstieg wieder mit dem Hauptmodul vereint. Dieser “Luxus” geht nur mit Treibstoff vor Ort. Ohne Vor-Ort-Treibstoff wird eine Rückkehr zur Apollo-Mentalität notwendig sein: So wenig Raum wie möglich für so wenige Leute wie möglich. Und das mit einem separaten Lander, der so leicht wie möglich ist. Dann wäre viel mehr machbar.
Mit einer Reduktion der Trockenmasse auf 80 t, einer Payload-Masse von 16 t (gerade genug, um drei Astronauten über die Dauer einer Mars-Mission am Leben zu halten), einem Lander mit Trockenmasse 5 t (ähnlich dem Apollo-Lander) sowie dem üblichen 1200 t Tank, würde man einen LMO mit einer Restmasse 237 t und somit Treibstoffmasse 136 t erreichen. Der Lander benötigt für Ab- und Aufstieg bei einer Restmasse 5 t eine Gesamtmasse von 17 t, also 12 t Treibstoff. Macht 124 t Treibstoff, mit dem man sich auf den Rückweg zur Erde machen kann, was einem Delta-V von 2,9 km/s ab LMO entspricht.
Das wäre noch etwas zu wenig für den Übergang in einen hohen Erdorbit, hierfür sind 3,4 km/s erforderlich, aber eine einzige Tanker-Mission zum Mars würde in diesem Fall das Problem lösen. Der Umstieg auf weniger Raum, weniger Leute und einen separaten Lander verwandeln die sieben Tanker-Missionen mit 56 Spaceship-Starts in nur eine Tanker-Mission mit 8 Spaceship-Starts. Und quetscht man noch ein paar weitere Tonnen raus, dann würde man sogar ganz ohne Tanker-Missionen in einen hohen Erdorbit kommen, oder, da man ab dort durch sehr liberales Aerobraking mit nur 1 km/s zur Oberfläche der Erde kommen kann, sogar den kompletten Weg nach Hause.
Auf lange Sicht ist die Gewinnung von Treibstoff vor Ort ideal. Durch Analyse der Marsoberfläche ist bekannt, dass alle Stoffe vorhanden sind, die zur Produktion von Methan und Sauerstoff notwendig sind. Ebenso ist bekannt, mit welchen chemischen Prozessen sich die Stoffe in Methan und Sauerstoff umwandeln lassen (etwa die Sabatier-Reaktion, die schon in U-Booten und Raumschiffen zur Gewinnung von Sauerstoff genutzt wurde). Notwendige Elektrizität lässt sich recht problemlos durch Solarpanele und RTGs erzeugen. Von einer prinzipiellen Machbarkeit der Vor-Ort-Produktion von Treibstoff darf man mit gutem Gewissen ausgehen.
Aber da dies noch nie gemacht wurde, muss die Technik erst geschaffen und auf dem Mond getestet werden. Die Technik muss mit einer gewissen Mindestrate produzieren, um Zeitfenster zu beachten. Sie muss Sand und erhöhte Strahlung aushalten können. Muss sich von den Astronauten schnell und einfach reparieren lassen können. Und so weiter. Es könnte dauern, bis diese Technik vorhanden ist und der Fokus auf Vor-Ort-Gewinnung könnte somit einer zeitigen bemannten Mars-Mission im Weg stehen.
Ende der 60er-Jahre sowie Anfang der 70er-Jahre wurde im Rahmen des NERVA-Projekts ein voll-funktionsfähiges nukleares Raketentriebwerk mit exzellenter Effizienz gebaut und getestet. Seitdem das Projekt 1973 von Richard Nixon gestrichen wurde, schien das Thema nuklearer Antrieb gegessen. Der Fokus von Forschung & Entwicklung lag in den letzten Jahrzehnten klar auf der Optimierung chemischer Antriebe sowie der Konstruktion elektrischer Antriebe wie etwa dem Hall-Effekt-Thruster. Seit kurzem treibt die NASA (1, 2) die Forschung von nuklearen Antrieben wieder voran und auch SpaceX hat schon angekündigt, auf lange Sicht in diese Richtung gehen zu wollen. Wieso das erneute Interesse?
Nukleare Antriebe würden eine klaffende Lücke schließen, die derzeit bemannten Missionen zu anderen Planeten im Wege steht. Chemische Antriebe wie etwa das RS-25, welches das Haupttriebwerk des Space Shuttles war und von der NASA bei der Konstruktion des SLS praktisch unverändert übernommen wurde, können einen fantastischen Schub produzieren (F = 1.900.000 N), haben aber eine relativ geringe Effizienz (Isp = 450 s). Sie sind perfekt für die erste Phase jeder Raummission geeignet: Die Rakete vom Boden in einen Orbit bringen. Einbußen in Effizienz werden dabei gerne in Kauf genommen, sofern das System gut konstruierbar ist und die enormen Anforderungen an den Schub erfüllt.
Bestehende elektrische Antriebe sind das exakte Gegenteil davon. Sie produzieren einen extrem geringen Schub (F = 0,15 Newton), aber das mit einer spektakulären Effizienz (Isp = 6.000 s). Sie werden dann eingesetzt, wenn nur kleine Korrekturen notwendig sind, zum Beispiel zur Erhaltung des Orbits eines Satelliten oder zum Deorbiting eines Satelliten am Ablauf der Lebenszeit, oder wenn bei größeren Korrekturen der Faktor Zeit keine Rolle spielt, etwa bei einer unbemannten interplanetaren Mission. Für jegliche bemannte Missionen ist der Schub von heutigen elektrischen Antrieben viel zu gering.
Es bleiben somit nur chemische Antriebe, bei denen die Effizienz aber wiederum so gering ist, dass eine unheilige Menge an Treibstoff für eine Reise zu einem anderen Planeten mitgeführt werden muss. Eine solche große Menge, dass der Treibstoff über mehrere Missionen in einen Erdorbit gebracht und dort über Rendevous zusammengeführt werden muss bzw. Treibstoff für den Rückweg auf dem Zielplaneten produziert werden muss. Beides ist prinzipiell möglich, aber leider auch ziemlich sperrig und voller zusätzlicher Risiken.
Der Reiz von nuklearen Antrieben ist, dass sie in die Mitte fallen. Eine große Variante des NERVA-Triebwerks würde einen guten Schub (F = 113.000 N) mit guter Effizienz (Isp = 910 s) produzieren. Zu wenig, um vom Boden in den Orbit zu kommen, aber genau richtig für alle weiteren Schritte einer interplanetaren Reise. Den Effekt der höheren Effizenz darf man nicht unterschätzen.
Mit dieser Karte lässt sich das benötigte Delta-V für interplanetare Missionen abschätzen. Angenommen ein Trägersystem hätte eine nukleare Rakete schon in einen Low Earth Orbit (LEO) gebracht, dann wäre ein Delta-V von circa ∆v = 16,2 km/s nötig, um zur Marsoberfläche und zurück zu kommen. Für eine Reise zum Mars kann man, alle Aspekte Raumschiff, Cargo und Lebenserhaltung inklusive, mit dem Richtwert 6 Tonnen pro Personen rechnen. Bei einer Crew mit 3 Personen wären das also 18 Tonnen. Dazu kommen die 3,3 Tonnen des nuklearen Antriebs, nuklearer Reaktor inklusive. Die Trockenmasse läge in diesem Szenario bei m = 21,3 Tonnen. Welche Menge an Treibstoff wäre hier benötigt? Und wie wäre das bei einem chemischen Antrieb? Über Tsiolkovsky’s Gleichung lässt sich das leicht berechnen:
Bei dem nuklearen Antrieb benötigt man etwa das 5-Fache der Trockenmasse an Treibstoff (Liquid H2), bei dem chemischen Antrieb das 38-Fache der Trockenmasse an Treibstoff (Liquid O2 / H2 Gemisch). Das ist ohne Zweifel eine enorme Verbesserung. Und moderne Trägersysteme könnten eine solche Rakete durchaus stemmen. Das amerikanische System Saturn V kann eine Masse von 140 Tonnen in einen LEO bringen, etwas mehr, als die m ≈ 21,3+110 ≈ 131 Tonnen dieser nuklearen Rakete.
Ein Nachteil, mit dem man leben müsste, aber auch leben könnte, wäre der geringere Schub und die damit verbundene längere Dauer von orbitalen Manövern. Mit den obigen Werten würde die anfängliche Beschleunigung der Rakete bei a = 0,9 m/s² liegen oder circa 10 % der Schwerebeschleunigung g (im stabilen Orbit darf a < g sein). Der Ejection Burn, also die Phase der Beschleunigung, welche die Rakete über den Einflussbereich der Erde hinaus bringt, benötigt gemäß der verlinkten Karte ein Delta-V von ∆v = 3,3 km/s und eine Menge mp = 9,5 Tonnen an Treibstoff. Der maximale Massenfluss bei der großen Variante des NERVA-Triebwerks ist 12,7 kg/s und der Ejection Burn dauert entsprechend grob 12 Minuten. Das ist deutlich länger als mit einem chemischen Antrieb, wäre aber sicherlich machbar, notfalls unterteilt auf mehr als eine Umrundung der Erde (wie es bei elektrischen Antrieben typisch ist).
Diese Rechnungen zeigen jedenfalls, dass man nuklearen Antriebe nicht für tot erklären sollte, auch wenn lange kaum daran geforscht wurde. In den letzten Jahrzehnten sollten Antriebe bemannte Missionen zum Mond oder unbemannte interplanetare Missionen ermöglichen und hier waren chemische und elektrische Antriebe ausreichend. Der Blick in Richtung bemannte interplanetare Mission verändert die Anforderungen jedoch und macht den nuklearen Antrieb sehr attraktiv.
Zu erwähnen ist, dass NERVA und ähnliche System keine “reinen” nuklearen Systeme sind. Solche Konzepte gibt es und würden den Isp sogar ein weiteres Mal verdoppeln oder verdreifachen, sind aber bei dem aktuellen Stand der Technologie Zukunftsmusik. NERVA-ähnliche Antriebe fallen, wie heutige chemische Antriebe auch, in die Oberkategorie der thermischen Antriebe. Bei beiden resultiert der Schub aus der erhöhten Temperatur des Treibstoffs in der Kammer der Düse. Der Unterschied liegt darin, wie der Treibstoff erhitzt wird. Bei NERVA-ähnlichen Antrieben umströmt der Treibstoff einen nuklearen Reaktor und wird dabei erhitzt, bei chemischen Antrieben kommt die Wärme von chemischen Reaktionen. Wie der Treibstoff erhitzt wurde, ist dem thermischen Antrieb aber prinzipiell egal, denn für die Berechnung von Schub und Isp zählt nur der Kammerdruck pc, die Kammertemperatur Tc sowie zwei Größen, die den Treibstoff charakterisieren (molare Masse M und Isentropen-Exponent k). Genauer ergibt sich für den Isp eines Antriebs im Vakuum, siehe Seite 20 und man beachte die Relation v = g*Isp, die folgende Formel:
Isp (Vakuum) ≈ 0,88 * sqrt(Tc / M)
Wobei k = 1,3 verwendet wurde. Wie die Temperatur Tc erzeugt wird, ist irrelevant für das Ergebnis. Beim Triebwerk RS-25 ist Tc = 3500 K und M = 0,014 kg/mol (Liquid O2 / H2) und somit Isp ≈ 440 s, ziemlich nah am gemessenen Wert. Bei der großen NERVA-Variante hat man Tc = 2600 K und M = 0,002 kg/mol (Liquid H2), woraus Isp ≈ 1000 s folgt, etwas über dem simulierten Wert. Man erkennt, dass die Kammer-Temperatur bei NERVA-ähnlichen Antrieben sogar geringer ist als bei chemischen Antrieben. Der zentrale Vorteil ist, dass man bei nuklearen Antrieben die Energie nicht mehr aus den Bindungen der Moleküle ziehen muss und somit zum leichtesten Treibstoff wechseln kann. Der höhere Isp dieser nuklearen Antriebe reflektiert also vor allem den Schritt zu einem Treibstoff mit einer geringeren molaren Masse.
(Molare Masse = Gewicht von 602 Trilliarden Moleküle einer Substanz)
Der Hohmann-Transfer ist die energetisch-günstigste Variante, eine Rakete von einem Planeten zu einem anderen Planeten zu bringen. Das Konzept birgt ein paar sehr interessante Hürden für das Verstehen, die sich vor allem daraus ergeben, dass man sowohl mit Geschwindigkeiten relativ zu einem Planeten wie auch mit Geschwindigkeiten relativ zur Sonne arbeiten muss. Achtet man aber genau darauf, diese Werte nicht zu vermischen, dann ergibt sich am Ende ein sehr schlüssiges Bild.
Erstmal die graphische Darstellung:
Die Ellipse von Erde zu Zielplanet im rechten Bild ist der Hohmann-Orbit. Diesen möchte man durch Beschleunigung der Rakete auf die Geschwindigkeit v(p) relativ zur Sonne einstellen. Anfangs befindet sich die Rakete in einem stabilen Orbit um die Erde, siehe den kleinen blauen Kreis im linken Bild. Auf diesem soll die Geschwindigkeit v(orb) relativ zur Erde betragen.
Ein erster wichtiger Punkt, und die kleinere von zwei Hürden, ist die Geschwindigkeit der Erde selbst, in dem Bild bezeichnet durch v(+). Die Geschwindigkeit auf dem Hohmann-Orbit v(p) ist die Summe der Geschwindigkeit des Planeten v(+) und der Geschwindigkeit v(∞), mit welcher die Rakete den gravitativen Einfluss der Erde verlässt. Entsprechend muss die Rakete den Einfluss der Erde nicht mit dem vollen Betrag der Geschwindigkeit für die Hohnmann-Bahn verlassen, sondern es reicht eine um die Geschwindigkeit des Planeten reduzierten Geschwindigkeit v(∞) = v(p)-v(+).
1) v(∞) = v(p) – v(+)
Man beachte die sorgfältige Formulierung: Die Rede ist von der Geschwindigkeit v(∞), mit welcher die Rakete den Einfluss der Erde verlässt. Angenommen man würde die Rakete, derzeit noch im Orbit um die Erde, in relativer kurzer Zeit auf diese Geschwindigkeit v(∞) beschleunigen. Die Rakete beginnt sich dank dieser Beschleunigung von der Erde zu entfernen, siehe die rote hyperbolische Bahn im linken Bild. Während die Rakete sich entfernt, reduziert sich die Geschwindigkeit aber noch etwas. Das ist ein wichtiger Punkt und die zweite konzeptionelle Hürde. Man würde somit den gravitativen Einfluss der Erde mit einer Geschwindigkeit unterhalb v(∞) verlassen (was man nicht möchte).
Um den Einfluss der Erde mit v(∞) zu verlassen, muss die Rakete im Orbit auf eine Geschwindigkeit oberhalb v(∞) beschleunigt werden. Bezeichnet man mit v(orb)’ die Geschwindigkeit der Rakete im Orbit nach dem Beschleunigungsvorgang, so muss also v(orb)’ > v(∞) gelten. Nur als konzeptionelle Hilfe soll die Reduktion der Geschwindigkeit beim Flug vom anfänglichen Orbit bis zum Verlassen des Einflusses der Erde mit v(red) bezeichnet werden. Es gilt dann:
2) v(orb)’ = v(∞) + v(red)
Vor dem Beschleunigungsvorgang hat die Rakete die orbitale Geschwindigkeit v(orb). Die notwendige Änderung der Geschwindigkeit ∆v (Delta-V), die man der Rakete beim Beschleunigungsvorgang im Orbit mitgeben muss, um schlussendlich in den Hohmann-Orbit zu kommen, ist also:
3) ∆v = v(orb)’ – v(orb)
Der konzeptionelle Teil des Transfers (bzw. der Einleitung des Transfers) ist damit geschafft. Um in den Hohmann-Orbit zu kommen, muss die Rakete den Einfluss der Erde mit der Geschwindigkeit v(∞) verlassen, welche der Geschwindigkeit auf dem Hohmann-Orbit v(p) minus der Erdgeschwindigkeit v(+) entspricht. Um diese Bedingung zu erreichen, muss man die Rakete im Orbit aber auf eine Geschwindigkeit v(orb)’ oberhalb dieser Zielgeschwindigkeit v(∞) beschleunigen. Und zwar genau soweit oberhalb, dass man am Ende mit v(∞) den interplanetaren Raum betritt. Die notwendige Änderung der Geschwindigkeit ∆v im Orbit ist v(orb)’ minus v(orb).
Die mathematische Behandlung ist relativ überschaubar. Man benötigt nur das Prinzip der Erhaltung der Energie, etwa ausgedrückt durch die Vis-Viva-Formel. Sei eine Rakete auf einem elliptischen Orbit um einen Körper der Masse M. Beim Durchlaufen des Orbits ändert sich wegen der elliptischen Form der Abstand der Rakete zum Körper ständig. Der geringste Abstand dabei sei rp (Periapsis), der größte Abstand ra (Apoapsis). Die orbitale Geschwindigkeit v der Rakete beim geringsten Abstand ist:
v² = 2*G*M*(ra/rp)/(ra+rp)
Daraus lässt sich schon mal ohne viel Mühe die Geschwindigkeit auf dem Hohmann-Orbit bestimmen. Der Hohmann-Orbit läuft um die Sonne, somit ist M = M(Sonne). Geht die Rakete von der Erde zu einem Planeten mit größerem Abstand zur Sonne, etwa Mars oder Jupiter, dann ist der geringste Abstand zur Sonne auf dem Hohmann-Orbit rp = R(Erde) = Abstand Sonne-Erde und der größte Abstand ra = R(Ziel) = Abstand Sonne-Zielplanet. Die Geschwindigkeit auf dem Hohmann-Orbit v(p) ist also:
Das sieht nicht schön aus, aber man erkennt, dass sich diese Geschwindigkeit aus nur wenigen Parametern ergibt, die allesamt gut bekannt sind: M(Sonne), R(Erde), R(Ziel) sowie v(+), was die Geschwindigkeit bezeichnet, mit der die Erde die Sonne umläuft.
Wie sind aber die beiden Geschwindigkeiten v(orb)’ und v(∞) miteinander verbunden? Auf welche Geschwindigkeit v(orb)’ muss man die Rakete im Orbit beschleunigen, damit sie mit v(∞) den Einfluss der Erde verlässt? Dazu reicht wieder ein Blick auf die Erhaltung der Energie:
Mit R(Orbit) dem Radius des anfänglichen kreisförmigen Orbits der Rakete um die Erde und nun der Masse M(Erde) statt M(Sonne), da dieser Orbit um die Erde läuft. Fehlt noch die anfängliche orbitale Geschwindigkeit, um angeben zu können, um welchen Betrag ∆v = v(orb)’-v(orb) die Geschwindigkeit im Orbit erhöht werden muss, um in den Hohmann-Orbit zu kommen. Der Wert v(orb) lässt sich mit der Vis-Viva-Formel mit rp = ra = R(Orbit) und M = M(Erde) bestimmen:
v(orb)² = G*M(Erde)/R(Orbit)
∆v = v(orb)’ – sqrt( G*M(Erde)/R(Orbit) )
3) ∆v = v(orb)’ – sqrt( G*M(Erde)/R(Orbit) )
So lässt sich in drei Schritten aus gut bekannten Parametern das notwendige Delta-V zum Übergang in den Hohmann-Orbit (und somit dem Einleiten des Transfers zum Zielplaneten) bestimmen. Und ist das Delta-V erstmal bekannt, so lassen sich auch relativ leicht viele andere wichtige Parameter bestimmen. Zum Beispiel die benötigte Menge an Treibstoff, die direkt aus Tsiolkovsky’s Raketengleichung folgt. Angenommen das Triebwerk der Rakete stößt den Treibstoff mit der effektiven Geschwindigkeit v(eff) relativ zur Rakete aus. Die Menge an Treibstoff, die ausgestoßen werden muss, um eine Änderung der Geschwindigkeit ∆v zu erzielen, ist dann:
m(Treibstoff) = m(0) * ( e∆v/v(eff) – 1 )
Mit der Anfangsmasse der Rakete m(0) = m(Trocken)+m(Treibstoff). Die effektive Geschwindigkeit v(eff) ist dabei etwas höher also die reale Geschwindigkeit v(real), mit welcher die Rakete den Treibstoff ausstößt. Das liegt daran, dass der Schub bei Raketen zwei Komponenten hat. Einmal die Änderung des Impulses, die sich durch das Ausstoßen des Treibstoffs nach hinten ergibt. Ein guter Vergleich zum Verständnis ist hierbei die Boot-Analogie. Befindet man sich auf einem kleinen Boot, ohne Paddel, aber dafür mit einem Sack Steinen, so kann man Steine nach hinten werfen, um eine Bewegung nach vorne zu erzielen. Zum Bremsen wirft man die Steine nach vorne. Nichts anderes macht eine Rakete, jedoch mit Gasteilchen statt Steinen.
Bei der Rakete kommt aber noch eine zusätzliche Kraft durch die Druckdifferenz hinzu. In der Düse des Triebwerks besteht ein Druck, welcher deutlich höher als der Druck vor der Rakete. Diese Differenz des Drucks ∆p erzeugt wirkend auf die Querschnittsfläche A der Rakete die Druckkraft F = ∆p*A. Der gesamte Schub der Rakete, mit r der Rate, mit welcher der Treibstoff ausgestoßen wird (in kg/s), ist also:
F = r*v(real) + ∆p*A
Um sich das Leben etwas einfacher zu machen, definiert man gerne die effektive Geschwindigkeit des austretenden Treibstoffs über r*v(eff) = r*v(real)+∆p*A oder v(eff) = v(real)+∆p*A/r und schreibt für den Schub dann schlicht F = r*v(eff). Ist dieser Wert nicht verfügbar, dann lässt er sich auch aus dem spezifischen Impuls des Triebwerks berechnen: v(eff) = g*Isp mit g der Erdbeschleunigung 9,81 m/s².
Der Übergang in den Hohmann-Orbit wird i.d.R. bei voller Schubkraft F(max) gemacht, woraus man bestimmen kann, mit welcher Rate r man den Treibstoff bei der Änderung der Geschwindigkeit um ∆v verbrennen muss und welche Zeit t die Änderung der Geschwindigkeit dauert:
r = F(max) / v(eff)
t = m(Treibstoff) / r = m(0) * ( e∆v/v(eff) – 1 ) * F(max) / v(eff)
Soll der Übergang in den Hohmann-Orbit in einem einzigen Brennvorgang geschehen, dann muss gewährleistet sein, dass die orbitale Geschwindigkeit im Verhältnis zur maximalen Schubkraft nicht zu hoch ist. Idealerweise, zur Maximierung der Effizienz und Präzision, geschieht der gesamte Vorgang der Beschleunigung an einem einzigen Punkt P (siehe linkes Bild). Das ist in der Praxis nicht möglich. Da der Brennvorgang eine Zeit dauert, beginnt die Beschleunigung eine gewisse Zeit vor Erreichen von P und dauert eine gewisse Zeit über das Erreichen von P hinaus. Eine gute Effizienz bedeutet einen durchlaufenen Winkelbereich w deutlich kleiner als 360°.
Sei w(max) der größtakzeptable Winkelbereich, über welchen die Beschleunigung um ∆v laufen soll. Die Rakete hat während des Brennvorgangs grob die mittlere Geschwindigkeit v(m) = (v(orb)+v(orb)’)/2 = v(orb)+∆v/2, welche sich in eine Winkelgeschwindigkeit dw/dt = R(Orbit)*v(m) übersetzt. Der tatsächlich durchlaufene Winkelbereich ergibt sich somit aus dieser Gleichung:
Nur wenn die Schubkraft F(max) diesen Grenzwert überschreitet, ist der Übergang auf die Hohmann-Bahn innerhalb eines Umlaufs um die Erde möglich. Bei Werten darunter muss die Rakete während mehrerer Umläufe auf die hyperbolische Austrittsbahn gebracht werden. Das ist vor allem bei Ionen-Antrieben der Fall, da bei diesen die Effizient zwar sehr hoch ist, v(eff) um 40 km/s bzw. Isp um 4000 s, dieser Vorzug aber zum Preis einer sehr geringen Schubkraft erkauft wird, F(max) um 0,2 N. Gewöhnliche Liquid-Fuel-Antriebe hinken in Effizienz zwar deutlich hinterher, v(eff) um 4 km/s und Isp um 400 s, können aber eine millionfach-höhere Schubkraft erreichen, F(max) um 2.000.000 N.
Über die anfängliche Beschleunigung hinaus gedacht: Wie lange dauert es, bis die Rakete auf diesem Wege den Zielplaneten erreicht? Und welche Strecke legt sie auf dem Weg dahin zurück? Die erste Frage lässt sich gut beantworten. Die orbitale Periode ist nur eine Funktion der Sonnenmasse M(Sonne) und der großen Halbachse a der Ellipse, welche das arithmetische Mittel von Periapsis und Apoapsis ist. Es gilt also a = (rp+ra)/2 = (R(Erde)+R(Ziel))/2. Hier interessiert natürlich nur die Hälfte der Periode:
t (Erde->Ziel) = π*sqrt( (R(Erde)+R(Ziel))³ / (8*G*M(Sonne)) )
Die zurückgelegte Strecke ist schwieriger. Es gibt keine analytische Lösung für den Umfang U einer Ellipse. Aus der Näherung “Approximation 1” von dieser Seite lässt sich mit etwas Umformung herleiten, dass sofern die Ellipse nicht zu schmal ist, der Umfang der Ellipse in guter Näherung proportional zum geometrischen Mittel von Periapsis und Apoapsis ist. Genauer ist U ≈ 2*π*sqrt(rp*ra). Die Hälfte davon gibt eine Näherung für den auf der Hohmann-Bahn zurückgelegten Weg zum Ziel:
s (Erde->Ziel) ≈ π*sqrt(R(Erde)*R(Ziel))
Alles hier besprochene, insbesondere der berechnete Delta-V-Wert, bezieht sich rein auf den Übergang von einem Erdorbit auf die Hohmann-Bahn. Dieser Übergang ist natürlich nur die halbe Miete für den Transfer zum Zielplaneten. Einmal angekommen am Ziel, muss die Rakete wieder von der Hohmann-Bahn auf einen Orbit um den Zielplaneten gebremst werden (Insertion) und auch das erfordert ein gewisses Delta-V. Ohne diese Bremsung bleibt es bei einem Fly-By auf dem Hohmann-Orbit. Weitere Informationen zum Übergang (ab Seite 65) sowie eine detaillierte Besprechung der Insertion (ab Seite 71) findet man in diesen Präsentation-Slides, aus welchen auch das obige Bild entnommen wurde.
Das Modell von Salerian (0) erlaubt es, das Abhängigkeitspotential verschiedener Konsumformen einer bestimmten Substanz mittels leicht messbarer bzw. zugänglicher pharmakokinetischer Parameter abzuschätzen. Beim Vergleich innerhalb einer Substanz bleiben nach Verhältnisbildung nur noch die maximale Konzentration C_max der Substanz im Blut sowie die Dauer T_max von Konsum bis zum Erreichen der maximalen Konzentration in Blut in der Formel übrig. Je größer die maximale Konzentration und je schneller diese Konzentration erreicht wird, desto größer ist das Abhängigkeitspotential (AP):
AP’ / AP = C_max’ / C_max * T_max / T_max’
Ich habe für fast alle gängigen Konsumformen von Nikotin diese beiden Parameter gesammelt, siehe die Links (1) bis (10) für die entsprechenden Studien, und das Abhängigkeitspotential einer Konsumform relativ zur Abhängigkeit bei gewöhnlichen Zigaretten gemäß dem Modell von Salerian berechnet.
Konsumform
Quellen
C_max
T_max
Relatives AP
Nikotin-Kaugummi
1,2,3,4,5,9
6,5 ng/ml
42 min
6 %
Nikotin-Lutschtablette
7,8,9
5,4 ng/ml
35 min
6 %
Nikotin-Mundspray
7
5,3 ng/ml
12,5 min
16 %
Snuff (Schnupftabak)
8,10
17 ng/ml
33 min
19 %
E-Zigaretten
1,2,5,6
8,5 ng/ml
10,0 min
32 %
Zigaretten
1,2,3,4,5
18 ng/ml
6,8 min
100 %
Man erkennt, dass alle alternativen Konsumformen zur gewöhnlichen Zigarette ein deutlich geringeres AP aufweisen, wobei unter den Alternativen die beiden Konsumformen E-Zigarette und Schnupftabak das höchste AP aufweisen. Im Falle von E-Zigaretten liegt das vor allem an der schnellen Aufnahme des Nikotins. Hier bekommt Konsument den vom Rauchen wohlbekannten “Kick”, wenn auch einige Minuten später und in abgeschwächter Form. Bei Schnupftabak muss der Konsument ohne diesen “Kick” auskommen, erreicht aber im Maximum eine Konzentration, die mit jener nach dem Konsum einer Zigarette vergleichbar ist.
Besonders gering fällt hingegen das Abhängigkeitspotential bei Kaugummis und Lutschtabletten mit Nikotin aus. Es dauert hier mehr als eine halbe Stunde, bis die Nikotin-Konzentration im Blut sein Maximum erreicht und dieses Maximum bleibt auch weit unter dem, was man nach dem Konsum einer Zigarette feststellen kann. Die obigen Werte sind, da eine klare Trennung auf Basis der Quellen nicht möglich war, eine Mischung der auf dem Markt gängigen Stärken 2 mg und 4 mg Nikotin. Bei Kaugummis und Lutschtabletten mit 2 mg kann man also einen AP-Wert leicht unter dem oben angeführten Wert ansetzen, bei 4 mg etwas darüber. Der Unterschied ist aber tatsächlich recht gering. Auch in der Stärke 4 mg bleibt das Abhängigkeitspotential klein, wohl noch unter 10 %.
Anmerkungen am Rande: Diese Tendenz im Abhängigkeitspotential (Rauchen ist problematischer als nasale Aufnahme und nasale Aufnahme ist problematischer als orale Aufnahme) gilt auch für alle anderen Substanzen in gleicher Weise. Intravenöse Aufnahme ist bezüglich des AP grob vergleichbar mit Rauchen. Das erklärt zum Beispiel, wieso Studien durchweg ein höheres AP bei Crack-Kokain (Rauchen) als bei Pulver-Kokain (nasale Aufnahme) ermittelt haben.
Dieser Effekt der Konsumform zeigt auch, wieso man bei Vergleichen über Substanzen hinweg vorsichtig sein sollte. Für einen Vergleich, der tatsächlich nur Substanz-spezifische Variationen der Abhängigkeit erfasst, muss dieselbe Form der Aufnahme gegeben sein. Dass Amphetamin in der Praxis ein höheres AP als Koffein zeigt, kann daran liegt, dass die Substanz selbst ein höheres AP erzeugt, oder alternativ auch daran, dass Amphetamin in der Regel nasal aufgenommen wird, während Koffein in der Regel oral konsumiert wird. Ein Vergleich von Amphetamin bei oralem Konsum, etwa in Form von Lutschtabletten, mit Koffein-Pulver bei nasaler Aufnahme, könnte ein sehr anderes Bild zeichnen.
Das wissenschaftliche Interesse an Nahtod-Erfahrungen (Near-Death Experiences NDE) hat in den letzten zwei Jahrzehnten zugenommen, aber es bleibt ein Nischenthema mit einer überschaubaren Anzahl an empirischen Studien. Für Interessierte ist das enttäuschend, jedoch reicht die aktuelle Datenlage aus, um verlässliche Aussagen zur Prävalenz und den typischen Elementen einer NDE zu machen.
Beschränkt man die Suche auf Studien, welche a) eine validierte Skala zur Klassifizierung von NDE verwenden (WCEI, Greyson), b) nach 2000 veröffentlicht wurden, c) mehr als 20 Patienten untersuchen und d) ausschließlich Patienten mit tatsächlichem Herzstillstand betrachten, so lassen sich über Google Scholar die im Bild aufgeführten Studien finden. Die größte Studie analysiert 344 Patienten mit insgesamt 509 Wiederbelebungen, was schon einem beachtlichen Studienumfang mit hoher statistischer Aussagekraft entspricht. Daneben noch drei Studien mit einem kleineren, aber sehr ähnlichem Pool an Patienten und eine weitere Studie, welche spezifisch NDE bei geplantem Herzstillstand betrachtet.
Mit sehr hoher Sicherheit kann man die Prävalenz einer Nahtod-Erfahrung nach Herzstillstand und erfolgreicher Wiederbelebung im Bereich 15-25 % verorten. Bei einem geplanten hypothermischen Herzstillstand scheinen jedoch keine Nahtod-Erfahrungen aufzutreten. Eine umfassende korrelative Analyse findet man nur bei der niederländischen Studie, bei allen anderen Studien ist die Stichprobe zu klein um auf diese Weise schwache oder moderate Effekte zu identifizieren.
Das Gedächtnis scheint eine wichtige Rolle für das Berichten von NDE zu spielen. Patienten, bei denen nach einer Wiederbelebung ein geschädigtes Gedächtnis verbleibt, berichten seltener von NDE als jene mit intaktem Gedächtnis. Der einzige in einer zweiten Studie reproduzierte Effekt ist jener der vorherigen NDE. Patienten, die schon früher eine NDE gemacht haben, berichten eher von einer NDE als jene ohne eine solche Erfahrung. Das Alter ist scheint ebenso ein Faktor. Bei Patienten unter 60 Jahren sind NDE gängiger als bei Patienten über 60 Jahren. Die höchste statistische Signifikanz hat folgender überraschender Effekt: Patienten mit NDE haben eine höhere Wahrscheinlichkeit in den folgenden 30 Tagen zu versterben als jene ohne NDE. Es lohnt sich aber, all diese Effekte mit Vorsicht zu genießen bis sie durch eine Reproduktion bestätigt wurden.
Drei der Studien schlüsseln die NDE weiter auf:
Die größte Studie findet eine Verteilung nahe 50/50 bezüglich positiver und negativer Emotionen. In den beiden kleineren Studien überwiegen jedoch positive Emotionen klar. Die Wahrnehmung eines hellen Lichts scheint sehr typisch zu sein, bei grob 70 % aller NDE wurde das berichtet. Recht häufig, bei etwa 30 % aller NDE, wird von der Erfahrung eines Tunnels bzw. des Bewegens durch einen Tunnel berichtet.
Bei außerkörperlichen Erfahrungen zeigt sich eine große Diskrepanz der Anteile, 24 % bis 90 %, was sich jedoch durch die Definition erklären könnte. So berichtet in Schwanninger 2002 ein Anteil 90 % von einer außerkörperlichen Erfahrung, jedoch haben von diesen nur 20 % eine visuelle außerkörperliche Erfahrung (also eine, bei der sie ihren eigen Körper von außen sehen können). Je nachdem, ob man die außerkörperliche Erfahrung auf visuell-ähnliche Empfindungen begrenzt oder auch andere Formen einbezieht, wird man demnach deutlich verschiedene Anteile erhalten.
Einige Patienten berichten auch vom berühmten Lebensfilm, dem Abspielen von Erinnerungen in chronologischer Abfolge, jedoch scheint dieser bei der Mehrheit der NDE nicht aufzutreten. Die Prävalenz dürfte um 10 % liegen. Viel häufiger, bei 25-50 % aller NDE, ist die Erfahrung einer Begegnung mit einer verstorbenen Person, in der Regel ein naher Angehöriger. Es tritt bei NDE in manchen Fällen auch die Erfahrungen einer “Grenze zwischen Leben und Tod” bzw. das Erreichen eines “Point of no Return” auf. Eine Grenze also, die bei Überschreitung keine Rückkehr zulässt. Hier ist die Diskrepanz jedoch wieder sehr groß, eine verlässliche Aussage zur Prävalenz ist nicht möglich. Bei der größten Studie wurde auch das Bewusstsein des Todes erfasst. Die Hälfte der Patienten hat davon berichtet, dass sie sich während des Herzstillstands ihres eigenen Todes bewusst waren.
Es lohnt sich an diesem Punkt anzumerken, dass die Elemente einer NDE eine auffällige Ähnlichkeit zu den Erfahrungen nach dem Konsum des Dissoziativums Ketamin oder dem Konsum des Halluzinogens DMT zeigen. Gemäß dieser Studie aus Frontiers in Psychology kann DMT intravenös schon ab der relativ geringen Dosis 7 mg, grob ensprechend einer Dosis 15-20 mg geraucht, alle Elemente von NDE mit hoher Verlässlichkeit reproduzieren.
Bei einem klassischen Ponzi-Scheme wird den Investoren die Vervielfachung des investierten Geldes um den Faktor Γ > 1 innerhalb einer gewissen Zeit p versprochen. Frühe Investoren erhalten i.d.R. auch tatsächlich die versprochene Auszahlung, was den Ponzi-Scheme zu Beginn legitim erscheinen lässt und weitere Investoren anzieht. Was die Investoren jedoch nicht wissen: Eine Vermehrung des Geldes am Markt, ein weiteres Versprechen des Betreibers, findet nicht statt. Die frühen Investoren werden schlicht mit dem Geld neuer Investoren bezahlt. Das wird solange aufrecht erhalten, bis die Betrugsmasche entweder auffliegt, der Betreiber aufgrund nachlassender Anmeldungen Pleite geht oder dieser sich mit den noch nicht ausgezahlten Investitionsbeträgen davon macht (“Rug-Pull”).
Interessant ist der Blick darauf, welcher Anteil der Investoren ihre versprochene Auszahlung erhalten, wenn der Betreiber nach der Zeit t die verbliebenen Investitionen einbehält. Angenommen die Rate der Neuanmeldungen beträgt λ(t) Personen pro Zeiteinheit. Die Gesamtanzahl Personen, die bis zur Zeit t in den Ponzi-Scheme investiert haben, folgt aus:
Ein Anteil c wird nach Ablauf der Investitionsperiode p das Geld entnehmen, der verbliebene Anteil 1-c die gesamte Auszahlung reinvestieren. Die Anzahl ausgezahlter Personen ist demnach:
Für ein Fortdauern des Ponzi-Schemes muss λ(t) kontinuierlich wachsen. Mit dem exponentiellen Ansatz:
Ergibt sich für den Anteil Investoren q, welche die versprochene Auszahlung erhalten haben (also q = n/N):
Für t gegen unendlich nähert sich q(t) einem konstanten Wert:
Man sieht, dass der Anteil Investoren, die ihr Geld samt Vermehrung wieder erhalten, umso kleiner ist, je schneller der Ponzi-Scheme “explodiert” (große Wachstumsrate r) und je länger die Investitionsperiode p ist. Da die Wachstumsrate umgekehrt proportional zur Verdopplungsdauer d ist, es gilt r = ln(2)/d, kann man das Ergebnis auch so formulieren: Der Anteil erfolgreicher Investoren nimmt exponentiell mit dem Verhältnis Investitionsperiode zu Verdopplungsdauer p/d ab.
Das Kapital, das dem Betreiber zu Zeit t verbleibt, ist:
Wobei b der mittlere Investitionsbetrag pro Person ist. Es folgt für t gegen unendlich:
Das verfügbare Kapital wächst somit auch exponentiell. Interessant ist hier der Blick auf die Abhängigkeiten zwischen den Parametern. In der Praxis dürften λ0 (anfängliche Anmelderate) und r (Wachstumsrate) von den Rahmenbedingungen des Ponzi-Schemes abhängig sein. Je größer der Faktor der Vervielfachung Γ und je kleiner die Periode p dieser Vervielfachung, desto mehr “Hype” wird der Ponzi-Scheme generieren. Bei einem Ponzi-Scheme, der eine Verdreifachung des Geldes in zwei Wochen verspricht, wird die anfängliche Anmelderate und Wachstumsrate höher sein als bei einem, bei dem eine Verdopplung alle zehn Wochen erfolgen soll.
Nimmt man an, dass λ0 und r proportional zum Verhältnis Γ/p sind, also:
Dann folgt:
Man erkennt an dem Ausdruck in der Klammer, dass es ein Optimum für die versprochene Vervielfachung Γ geben muss, was auch intuitiv Sinn macht. Verspricht der Betreiber nur eine geringe Vervielfachung Γ, dann muss dieser zwar bei der Auszahlung an frühe Investoren nur wenig des Geldes neuer Investoren verwenden, generiert aber nur wenig Hype um den Ponzi-Scheme. Verspricht der Betreiber eine hohe Vervielfachung Γ, dann entsteht ein großer Ansturm und ein schnelles Wachstum, jedoch reduzieren die Auszahlungen an frühe Investoren das verfügbare Kapital erheblich. Es gibt also einen “Sweet Spot” für Γ.
Für verschiedenste Anwendungen ist es manchmal von Interesse, das Produkt von Zufallsvariablen zu berechnen. Also der folgende Ausdruck, wobei der Wert für jedes X_i derselben Dichtefunktion entnommen wird und die jeweiligen X_i unabhängig voneinander sein sollen, d.h. es soll cov(X_i , X_j) = 0 für alle i ≠ j gelten.
Der Weg zum Glück beginnt mit dieser Umformung:
Es wird also die Substitution L = ln(X) verwendet. Idealerweise kann man den Mittelwert und die Varianz von L exakt berechnen. In der Regel führt das aber zu analytisch unlösbaren Integralen. Ein cooler Trick ist hier der Rückgriff auf die Delta-Methode, mit der man schnell und einfach eine gute Schätzung für den Mittelwert und die Varianz einer transformierten Zufallsvariablen bekommt:
Für L = ln(X):
Für den Mittelwert und die Varianz der Summe S folgt dann:
Jetzt stellt sich die Frage nach der Verteilung von S. Der zentrale Grenzwertsatz sichert zu, dass die Verteilung von S für n gegen unendlich gegen die Normalverteilung mit den hier berechneten Parametern geht. Nimmt man entsprechend an, dass S in guter Näherung normalverteilt ist, dann folgt, dass Y lognormal ist:
Damit ergibt sich:
Noch etwas schöner wird das Resultat, wenn man statt des multiplikativen Faktors X die prozentuale Veränderung P als Zufallsvariable nimmt, also X = 1+P. Es lässt sich leicht folgendes zeigen:
Das ist eine schnelle und genaue Schätzung für den Mittelwert und die entsprechende Standardabweichung des Produktes Y gegeben Mittelwert und Standardabweichung der prozentualen Veränderung P je Schritt sowie die Anzahl Schritte n. Der Wert cv bezeichnet hier den Coefficient of Variation, das Verhältnis von Standardabweichung zu Mittelwert bei der prozentualen Veränderung.
Ein Beispiel: Bei jeder Gehaltserhöhung soll eine Person im Mittel eine Steigerung von mu_p = 0,15 = 15 % mit einer Standardabweichung sigma_p = 0,04 = 4 % erhalten. Nach n Gehaltserhöhungen beträgt das Gehalt, gegeben das Anfangsgehalt a, im Mittel also mu_y = a*exp(0,19*n) mit einer Standardabweichung von sigma_y = a*mu_y*sqrt(exp(0,016*n)-1). Das 95 % Konfidenzintervall für das Gehalt nach n Erhöhungen ergibt sich wie gewohnt aus y = mu_y ± 1,96*sigma_y. Nach drei Gehaltserhöhungen erhält man daraus zum Beispiel y = 1,77*a ± 0,76*a.
In der Theorie der Warteschlangen kann man ein ziemlich cooles und allgemein weniger bekanntes Paradoxon finden, dass auf den ersten Blick im harten Konflikt zur intuitiven Erwartung steht, sich aber mit einem kleinem Zusatz glücklicherweise schnell auflöst. Im Englischen wird das Paradoxon auch gerne als Hitchhiker’s Paradox (Anhalter-Paradoxon) bezeichnet, im Buch “Queueing Systems” von Kleinrock, wo ich es zum ersten Mal gesehen habe, läuft es unter dem Namen Hippie Paradoxon. Persönlich bevorzuge ich den Namen Zustandsparadoxon, weil das Paradoxon, obwohl durch Wartezeiten gut verdeutlicht, viel grundlegender als das ist. Es tritt bei jedem System auf, welches in verschiedene Zustände wechselt.
Angenommen man installiert eine Lichtschranke an einer Straße und misst kontinuierlich den zeitlichen Abstand zwischen den vorbeifahrenden Autos. Nach einer Phase der Beobachtung kennt man den mittleren zeitlichen Abstand zwischen zwei Autos recht genau, sagen wir 60 Sekunden. So lange dauert es, bis nach dem Vorbeifahren eines Autos das nächste Auto durchfährt. Es ist natürlich nur ein Mittelwert – manchmal ist der Abstand länger, manchmal kürzer. Aber im Mittel beträgt diese Zeit 60 Sekunden.
Angenommen man geht zu einem zufälligen Zeitpunkt an diese Straße. Wie lange muss man im Mittel warten, bis ein Auto vorbeifährt? Bei echter Zufälligkeit scheint die Antwort 30 Sekunden unvermeidbar. Um im Mittel weniger als 30 Sekunden zu warten, müsste man sich schon in irgendeiner Weise mit dem Verkehr abstimmen. Man könnte etwa, sobald man gehört hat, wie ein Auto vorbeifährt, eine gewisse Zeit warten und erst dann an die Straße gehen. So könnte man die mittlere Wartezeit drücken.
Umgekehrt könnte man sich natürlich mit dem Verkehr auch so abstimmen, dass die Wartezeit im Mittel mehr als 30 Sekunden beträgt. Wieso man das wollte sei dahingestellt, aber es wäre machbar. Ganz ohne Abstimmung jedoch, also bei echter Zufälligkeit, wird man im Mittel wohl 30 Sekunden warten müssen bis das nächste Auto kommt. Alles andere wäre ohne eine Form der Abstimmung mit dem Verkehr ein ziemlich seltsames Resultat.
Zum Glück muss man nicht raten. Ein Experiment bringt Klarheit. Man geht zufällig an die Straße und hält die Zeit bis zum nächsten Auto fest. Das wiederholt man zehntausend Mal und berechnet dann den Mittelwert. Die mittlere Wartezeit wäre … Trommelwirbel … 40 Sekunden. Nicht 30 Sekunden, sondern länger. Das gilt ganz allgemein. Geschehen zwei Ereignisse im Mittel mit den Zeitabständen T, dann wäre bei zufälliger Ankunft die Wartezeit bis zum nächsten Ereignis immer größer als T/2.
Das steht auf den ersten Blick auf sehr deutlichem Kriegsfuß mit der Intuition. Beispiel Verkehrslücken. Das Paradoxon sichert zu, dass die Verkehrslücke, die man bei Anfahren an eine Kreuzung bekommt, im Mittel größer ist die mittlere Verkehrslücke zwischen den Autos (etwa gemessen vom Helikopter aus). Und der verbliebene, zum Einfahren nutzbare Teil der Verkehrslücke, die man bei Anfahren vorfindet, wird im Mittel größer sein als die Hälfte der mittleren Verkehrslücke im System. Klingt ein bisschen wie Magie.
Die Erklärung ist sehr einfach: Die Stichprobe ist nicht so fair, wie sie erst scheint. Größere Lücken nehmen einen größeren Anteil der Straße ein. Und somit trifft man auch eher auf solche, wenn man zufällig an die Straße anfährt. Vom Helikopter aus lassen sich die Lücken kontinuierlich messen und man kann so den wahren Mittelwert der Lückengröße ermitteln. Beim zufälligen Anfahren werden jedoch große Lücke bevorzugt selektiert. Das ist der zentrale Punkt. Man kommt bei Messung mittels Anfahren also zu einem anderen, größeren Mittelwert. Entsprechend bleibt zum Einfahren auch mehr als die Hälfte der wahren mittleren Lücke im System, da man die Hälfte einer größeren Lücke zur Verfügung hat.
Ähnlich ist es mit dem zeitlichen Abstand der Autos. Wenn man zufällig an die oben beschriebene Straße tritt, wird man im Mittel dann ankommen, wenn die Lücke zwischen den Autos größer als 60 Sekunden ist. Solche Lücken nehmen anteilig schlicht mehr Raum. Entsprechend wird die mittlere Wartezeit bis zum nächsten Auto größer als 30 Sekunden sein. Die mittlere Wartezeit von 40 Sekunden war also kein Widerspruch zur Zufälligkeit, sondern ein sehr logisches Resultat.
Die Mathematik dahinter ist “relativ schmerzfrei”. Gegeben ein System mit den Zuständen 1, 2, 3 … Die Wahrscheinlichkeit, dass das System nach Beendigung eines Zustands auf Zustand k wechselt, sei pk. Die Dauer von Zustand k sei tk. Die mittlere Dauer T eines Zustands ist E(T) = [Summe über k] pk*tk. Es werden N Zustände beobachtet. Die gesamte vergangene Zeit ist N*E(T). Die Zeit in Zustand k ist N*pk*tk. Der Anteil der Zeit, den das System in Zustand k verbringt, ist also qk = pk*tk/E(T). Das entspricht auch der Wahrscheinlichkeit, das System bei zufälliger Messung in Zustand k vorzufinden. Die mittlere Dauer eines zufällig vorgefundenen Zustands ist E(T’) = [Summe über k] qk. Eingesetzt erhält man:
E(T’) = [Summe über k] pk*tk² / [Summe über k] pk*tk
E(T’) = E(T²) / E(T)
Wobei E(T²) der Erwartungswerts der quadratischen Dauer* eines Zustands ist. Mit der Varianz s² (Standardabweichung s) lässt sich das noch sehr deutlich vereinfachen. Eine zentrale Gleichung der Mathematik von Wahrscheinlichkeiten ist s² = E(T²) – E(T)². Es ist somit E(T’) = E(T)+s²/E(T). Die mittlere verbliebene Zeit im vorgefundenen Zustand E(V), das entspricht der mittleren Wartezeit bis zum nächsten Zustandswechsel, ist die Hälfte der Dauer des vorgefundenen Zustands, also E(V) = (1/2)*E(T’). Somit:
E(V) = (1/2)*(E(T) + s²/E(T)) > (1/2)*E(T)
Damit ist gezeigt: In jedem System mit von null verschiedener Varianz ist die verbliebene Zeit im angetroffenen Zustand im Mittel größer als die Hälfte der mittleren Dauer der Zustände. Mal zwei gerechnet kann man es auch einfacher formulieren, wobei aber der Bezug zur Wartezeit verloren geht: Der vorgefundene Zustand ist im Mittel länger als die mittlere Dauer eines Zustands im System. Das ist eine sehr grundlegende Feststellung. Es gilt für jedes System mit einem Mittelwert E(T) kleiner als unendlich und einer Varianz ungleich Null (also eigentlich alle realen Systeme).
Das Paradoxon ist nicht nur intellektuell spannend, sondern auch für praktische Zwecke ziemlich nützlich. In der Theorie der Warteschlangen wird das Ergebnis verwendet, um M/M/1 Warteschlangen (Ankunftszeiten und Servicezeiten exponentialverteilt) auf M/G/1 (Ankunftszeiten exponentialverteilt, Servicezeiten beliebig verteilt) zu verallgemeinern. Das Paradoxon erlaubt also, die strikte Annahme exponentialverteilter Servicezeiten fallen zu lassen und stattdessen mit einer beliebigen Verteilung mit Mittelwert m und Standardabweichung s zu arbeiten. Das wiederum führt zu sehr nützlichen Ergebnissen, mit denen man relativ leicht die mittlere Wartezeit, die mittlere Länge einer Schlange, etc … in Abhängigkeit von der Ankunftsrate von Kunden berechnen kann.
* Noch eine Anmerkung zu E(T²). E(T) ist der Erwartungswert der Dauer. Man misst n-Mal die Dauer und berechnet dann über E(T) = (1/n)*(T1+T2+T3+…+Tn) den gewöhnlichen Mittelwert / Erwartungswert. E(T²) ist der Erwartungswert der quadratischen Dauer. Man misst n-Mal die Dauer, quadriert diese jeweils und berechnet den Mittelwert dieser Quadrate E(T²) = (1/n)*(T1²+T2²+T3²+…+Tn²). Wieso sollte das sinnvoll sein? Beispiel Gasmechanik. Jedes Teilchen in einem Gas fliegt mit einer gewissen Geschwindigkeit v umher. Die kinetische Energie des Teilchens ist K = (1/2)*m*v². Was ist die mittlere kinetische Energie eines Teilchens? Naheliegend ist der folgende Ansatz: Man misst alle Geschwindigkeiten, berechnet die mittlere Geschwindigkeit E(V) und sagt E(K) = (1/2)*m*E(V)². Das Ergebnis wäre aber falsch. Für die mittlere kinetische Energie kann man nicht einfach die mittlere Geschwindigkeit quadrieren. Man müsste die Geschwindigkeiten messen, das Ergebnis jeder Einzelmessung quadrieren und den Mittelwert dieser Quadrate berechnen, also E(V²). Die korrekte mittlere kinetische Energie ist E(K) = (1/2)*m*E(V²). Es gilt in jedem System mit Varianz ungleich Null: E(V²) > E(V)². Mit dem ersten Ansatz hätte man die mittlere kinetische Energie, und somit etwa die Temperatur des Gases, unterschätzt.
Man liest immer mal wieder, dass bei einer Radarkontrolle in einer 100 Km/h Zone ein besonders enthusiastischer Autofahrer mit 180 oder 200 Km/h geblitzt wurde. Für den Betroffenen ist das eine ziemlich teuere Angelegenheit. Aber es führt auf ein sehr interessantes mathematisches Problem, welches sich auch zufriedenstellend lösen lässt. Angenommen wir beginnen eine Messung der Geschwindigkeit. Welche maximal gemessene Geschwindigkeit würden wir nach der Messung von 100 Autos erwarten? Von 1000 Autos? Von 10.000 Autos? Es ist also die Frage nach dem typischen Rekordwert. Die Lösung lässt sich natürlich auf viele Bereiche übertragen, zum Beispiel Rekordwerte beim Wetter. Angenommen wir beginnen täglich zu messen, wie groß wird die maximale gemessene Temperatur nach zehn Jahren Messung sein? Wie groß nach 100 Jahren?
Die Mathematik dahinter ist anspruchsvoll, deshalb kommt erst das Ergebnis inklusive Beispiele und dann die komplette Herleitung. Basis der Rechnung ist die Annahme, dass die gemessene Variable einer Normalverteilung mit Mittelwert m und Standardabweichung s folgt. Für die Geschwindigkeit in einer 100 Km/h Zone ist grob m = 100 Km/h und s = 7 Km/h. Der Mittelwert gibt an, wo man auf lange Sicht landet, wenn man alle Messwerte summiert und durch die Anzahl Messungen teilt. Die Standardabweichung ist ein Maß für die Streuung. Würden alle Autos exakt 100 Km/h fahren, dann wäre s = 0. Würden alle Autos sehr nah an der 100 Km/h fahren, etwa nur im Bereich 95 bis 105 Km/h, dann wäre s zwar nicht Null, aber recht klein, circa s = 3 Km/h. Realistischer sind Variationen um s = 7 Km/h.
Angenommen man entnimmt einer Normalverteilung mit Mittelwert m und Standardabweichung s durch unverzerrte und unabhängige Messung n Werte. Eine Rechnung zeigt, dass sich der Median des maximalen Messwerts für n gegen unendlich aus folgender Formel ergibt:
xmax = m + 0,59*s*ln(n)
Mit dem natürlichen Logarithmus ln. Der Minimalwert ist:
xmin = m – 0,59*s*ln(n)
Folgen die Geschwindigkeiten einer Normalverteilung mit m = 100 Km/h und s = 7 Km/h, dann würde man nach Messung von n = 100 Autos die Rekordwerte 81 Km/h und 119 Km/h erwarten. Nach n = 1000 Messungen 71 Km/h und 129 Km/h. Nach 10.000 Messungen 62 Km/h bis 138 Km/h. Man erkennt, dass Rekordwerte sich eher langsam verschieben. Der Schritt von 1000 zu 10.000 Messungen, eine Verzehnfachung, bringt das erwartete Maximum nur von 129 Km/h auf 138 Km/h. Das liegt an der Abhängigkeit zum Logarithmus, eine Funktion, die notorisch langsam wächst.
Ein weiteres Beispiel: Laut Statista beträgt die mittlere Größe eines Mannes in D etwa m = 177 cm. Werte für die Standardabweichung sind etwas schwieriger zu finden, aber von dem, was ich gesehen habe, sollte s = 5 cm ziemlich gut hinkommen. Welche maximale Körpergröße erwartet man bei einem Publikum von 1000 Leuten? Und welchen Maximalwert für Deutschland insgesamt, mit 83 Mio Einwohnern? Für 1000 Leuten ergibt sich xmax = 197 cm, hier landet man also noch etwas unter der Zwei-Meter-Grenze. Für Deutschland als Ganzes erhält man xmax = 231 cm, etwas mehr, aber doch noch relativ nah an diesem deutschen Big Chungus (Yannik Könecke, wohnhaft in der Nähe von Hannover, stolze 224 cm).
Auch die Umkehrung ist möglich und bietet einen schnellen und nützlichen Weg, die Standardabweichung aus einer Messreihe zu schätzen. Werden bei n Messungen die Rekordwerte xmax und xmin festgehalten, dann ist das vereinbar mit Annahme, dass die gemessene Variable einer Normalverteilung mit m und s folgt:
m = (xmin+xmax)/2
s = (xmax-m)/(0,59*ln(n))
Der Zusatz n gegen unendlich wurde schon erwähnt. Da sich die Dichtefunktion der Normalverteilung analytisch nicht integrieren lässt, existiert keine analytische Lösung des Problems. Man muss sich mit einer Funktion begnügen, die sich für n gegen unendlich an das Ergebnis des Integral anschmiegt. Eine gute (und mit steigendem n auch immer besser werdende) Näherung erhält man somit über die obigen Formeln erst für n > 20 Messungen. Das dürfte in den meisten Fällen kein Hindernis sein.
Zur Herleitung: Gegeben seien n Zufallsvariablen X1 , X2 , … , XN. Jede Zufallsvariable wird unverzerrt und unabhängig derselben Verteilung entnommen, ausgedrückt durch die kumulierte Verteilungsfunktion F(x). Man könnte auch mit der Dichtefunktion f(x) beginnen, aber F(x) vereinfacht die Argumentation. Die Wahrscheinlichkeit, dass XK einen Wert kleiner als x hat, ist P(XK < x) = F(x). Die Wahrscheinlichkeit, dass jedes XK kleiner als x ist, und somit auch der maximale Wert kleiner als x ist, folgt aus P(xmax < x) = F(x)^n. Diese Formel gehört zum Bereich Order Statistics und lässt sich zum Beispiel auch hier finden. Beim Median gilt stets P(X < x) = 0,5. Der Median des maximalen Werts ist dann:
xmax = F(-1)(0,5^(1/n))
Wobei F(-1) die Umkehrfunktion von F ist. Das gilt für alle Verteilungen. Speziell für die Normalverteilung kann man für alle z-Werte die sehr nützliche Näherung F(z) = 1/(1+exp(-1,7*z)) verwenden, welche für z gegen unendlich gegen die exakte Verteilungsfunktion geht. Die Umkehrfunktion folgt durch Umstellung des Ansatzes y = F(z) nach z. Es ist z = F(-1)(y) = 0,59*ln(y/(1-y)). Es folgt mit y = 0,5^n:
zmax = F(-1)(0,5^(1/n))
zmax = 0,59*ln(1/(2^(1/n)-1))
Im Prinzip könnte man hier aufhören, aber für n gegen unendlich lässt sich diese sperrige Formel noch deutlich vereinfachen. Die Taylor-Reihe für 2^x für x gegen Null ist 1+x*ln(2). Entsprechend gilt für n gegen unendlich 2^(1/n)-1 = (1/n)*ln(2). Eingesetzt in die Formel ergibt sich:
zmax = 0,59*ln(n/ln(2)) = 0,59*(ln(n)-ln(2))
Für n gegen unendlich ist ln(n) >> ln(2), so dass man die ln(2) einfach wegfallen lassen kann. Es folgt noch die Umrechnung des z-Werts in den x-Wert mittels z = (x-m)/s:
zmax = (xmax-m)/s = 0,59*ln(n)
xmax = m + 0,59*s*ln(n)
Es wurde hier die Normalverteilung vorrausgesetzt, aber jede Verteilung mit einem Erwartungswert m kleiner als unendlich und einem beliebigen s geht für große n gegen die Normalverteilung mit Erwartungswert m und Standardabweichung s. Sofern n groß genug ist, wird also auch jede andere Verteilung Rekordwerte nach xmax = m + 0,59*s*ln(n) produzieren. Für die Minimalwerte kann man die Herleitung mit dem Ansatz P(xmin < x) = 1-(1-F(x))^n wiederholen. Bei symmetrischen Verteilungen geht es aber auch einfacher, nämlich über m-xmin = xmax-m (gleiche Abstände zum Mittelwert). Es folgt daraus xmin = 2*m-xmax.
Der Gini-Koeffizient bekommt sehr wenig Liebe. Nur sehr selten berichten Medien darüber, was diese Zahl bedeutet, wie sie sich von Land zu Land unterscheidet und wie sie sich von Jahr zu Jahr ändert. Das ist enttäuschend, denn der Gini-Koeffizient macht einen zentralen Aspekt der Gesellschaft sichtbar: Die Ungleichheit. In der Regel die Ungleichheit im Einkommen, aber der Gini lässt sich auch für Wohlstand und Bildung berechnen.
Wie kann man Ungleichheit messbar machen? Ausgangspunkt ist die Lorentz-Verteilung. Angenommen man kenne das Einkommen jeder einzelnen Person im Land: I1, I2, I3, … , IN (insgesamt N Personen). Durch Addition kommt man zum Gesamteinkommen im Land: I = I1+I2+I3+…+IN. Zur Vereinfachung nehmen wir an, dass die Einkommen schon der Größe nach geordnet sind, also I1 < I2 < I3 < … < IN.
Uns interessiert jetzt, welcher Anteil p des gesamten Einkommens auf die 10 % der Bevölkerung fällt, die das geringste Einkommen haben. 10 % der Bevölkerung sind L = 0,1*N Leute. Wir addieren also das Einkommen der L Leute mit dem geringsten Einkommen, I10% = I1+I2+I3+…+IL, und teilen diesen Wert durch das gesamte Einkommen: p = I10% / I. Damit wissen wir, welcher Anteil p des Gesamteinkommens auf die unteren 10 % fällt. Hätte jede Person im Land dasselbe Einkommen, dann wäre p = 10 %. In der Praxis fällt aber auf die unteren 10 % deutlich weniger als 10 % des Gesamteinkommens.
Die Lorentz-Verteilung gibt an, wieviel Prozent p des Gesamteinkommens auf die unteren x Prozent der Bevölkerung fällt. In guter Näherung folgt die Verteilung in jedem Land der Formel:
p = x^a
Mit dem Parameter a, der als einziger zusätzlicher Input benötigt wird und sich aus einer Datenerhebung im Land ergibt (zur Schätzung später mehr). In Deutschland ist a = 1,9. Auf die unteren 10 % der Bevölkerung fällt der Anteil p = 0,1^1,9 = 0,013 = 1,3 % des Gesamteinkommens. Auf die unteren 20 % fällt p = 0,2^1,9 = 0,047 = 4,7 %. Und so weiter. Noch extremer ist der Unterschied etwa in Zimbabwe, wo a = 3 gilt. Auf die unteren 10 % fällt hier der Anteil p = 0,1^3 = 0,001 = 0,1 % des Gesamteinkommens. Auf die unteren 20 % fällt p = 0,2^3 = 0,008 = 0,8 %. Und so weiter.
Diese Werte geben schon einen guten Einblick in die Ungleichheit in einem Land, aber es wäre nützlich, die Ungleichheit in einer einzigen Zahl zu sammeln. Und diese Zahl dann auch leicht interpretierbar zu machen. Der Gini-Koeffizient schafft all das. Hier ein Graph aus dem Wiki-Eintrag für den Gini-Koeffizienten, den man für nicht-kommerzielle Zwecke verwenden darf:
Wie schon erwähnt ergibt sich für den Fall, dass jede Person im Land dasselbe Einkommen hat, eine Gleichheit von p und x, also p = x. Auf die unteren 10 % fällt 10 % des Gesamteinkommen, auf die unteren 20 % fällt 20 %, etc … Das ist die Gerade im Graphen. Die tatsächliche Verteilung ist durch die Lorentz-Kurve gegeben. Man sieht (durch grobes Ablesen), dass in diesem Beispiel auf die unteren 50 % etwa 20 % des gesamten Einkommens fällt. Es lassen sich hier zwei Flächen abgrenzen. Die Fläche A zwischen Gerade und Lorentz-Verteilung und die Fläche B unter der Lorentz-Verteilung. Die Gesamtfläche ist A+B.
Bei sehr geringer Ungleichheit wird die Lorentz-Verteilung nah an der Geraden liegen und die Fläche A wird klein im Verhältnis zur Gesamtfläche sein. Bei großer Ungleichheit gibt es hingegen viel Abstand zwischen der Geraden p = x und der tatsächlichen Verteilung des Einkommens p = x^a und entsprechend nimmt A einen höheren Anteil an der Gesamtfläche ein. Bei extremer Verteilung des Einkommens, alle Leute außer einer Person haben das Einkommen Null, würde A die gesamte Fläche einnehmen. Es bietet sich also an, die Ungleichheit durch das Verhältnis Fläche A zu Gesamtfläche A+B auszudrücken. Genau so ist der Gini-Koeffizient definiert:
G = Diskrepanzfläche/Gesamtfläche
G = A/(A+B)
Da die Anteile x und p zahlenmäßig jeweils im Bereich 0 bis 1 liegen müssen, ist die Gesamtfläche leicht zu berechnen. Es ist ein Dreieck mit Grundseite 1 und Höhe 1, also A+B = (1/2)*1*1 = 0,5. Für die Fläche A muss man von der Gesamtfläche die Fläche unter der Lorentz-Kurve abziehen:
A = 0,5 – [Integral 0 bis 1] x^a dx
Daraus folgt für den Gini-Koeffizient:
G = (a-1)/(a+1)
Und für den umgekehrten Weg, von Gini zu Lorentz:
a = (1+G)/(1-G)
Für Deutschland mit a = 1,9 erhält man also G = 0,9/2,9 = 0,31, für Zimbabwe mit a = 3 folgt G = 2/4 = 0,5. Die Regel lautet: Je kleiner der Gini-Koeffizient, desto kleiner die Ungleichheit im Land. Der internationale Vergleich zeigt, dass Werte unter 0,3 exzellent sind, Werte unter 0,35 ganz gut, Werte über 0,4 problematisch und Werte über 0,45 kritisch. Auch der Zeitverlauf ist nützlich. In Deutschland gab es schon vor der Pandemie einen Trend zu mehr Ungleichheit, die Pandemie hat das beschleunigt.
Zur besseren Interpretation eines Gini-Wertes empfehle ich die Berechnung des folgenden Verhältnisses. Zuerst berechnet man aus dem gegebenen Gini G den Lorentz-Exponent a, siehe vorherige Formel. Auf die unteren 10 % der Bevölkerung fällt p = 0,1^a des Gesamteinkommens, auf die oberen 10 % fällt der Anteil p = 1-0,9^a (also 100 % des Gesamteinkommens minus das, was auf die unteren 90 % fällt). Das Verhältnis der Anteile von Top 10 % zu Bottom 10 % ist somit:
r = (1-0,9^a)/0,1^a
In Deutschland mit G = 0,32 / a =1,9 fällt auf die Top 10 % der Bevölkerung r = 16 mal mehr am Gesamteinkommen als auf die Bottom 10 %. In Zimbabwe mit G = 0,5 / a = 3 fällt auf die Top 10 % der Bevölkerung sogar r = 271 mal mehr (kein Schreibfehler) als auf die Bottom 10 %. Man erkennt an diesem Verhältnis, wie enorm der Schritt von G = 0,32 zu G = 0,5 wirklich ist. Deshalb lohnt es sich auch, den Gini zur Interpretation in r umzurechnen.
Achtung: Hier tappt man leicht in eine Falle. Das Verhältnis r drückt aus, wie das Verhältnis der Anteile am Gesamteinkommen von Top 10 % zu Bottom 10 % liegt. Das ist nicht identisch zum Verhältnis der mittleren Einkommen von Top 10 % zu Bottom 10 %, also das, was man bekommt, wenn man das mittlere Einkommen in der Gruppe der Top 10 % Verdiener durch das mittlere Einkommen in den Bottom 10 % teilt. Es lässt sich zeigen, dass für das Verhältnis des mittleren Einkommens von Top 10 % zu Bottom 10 % in in guter Näherung gilt:
r’ = 19^(a-1)
In Deutschland gerundet r’ = 14 und in Zimbabwe r’ = 361. Die Herleitung davon führt schlussendlich zu einer weiteren wichtigen Formel, nämlich der Berechnung des Anteils der Bevölkerung, die unterhalb eines bestimmten Einkommens liegt. Die Lorentz-Formel sagt, dass auf die unteren x Prozent der Bevölkerung x^a Prozent des Gesamteinkommens I fällt. Das summierte Einkommen der unteren x Prozent der Bevölkerung ist also I*x^a. Die unteren x Prozent der Bevölkerung sind N*x Personen. Das Einkommen PRO PERSON in den unteren x Prozent ist demnach I*x^a / (N*x) = (I/N)*x^(a-1). Dabei ist I/N = i einfach das mittlere Einkommen über die gesamte Bevölkerung. Das mittlere Einkommen einer Person in den unteren x Prozent lässt sich damit wie folgt schreiben:
q = i*x^(a-1)
Um sinnvolle Vergleiche zwischen verschiedenen Gruppen der Bevölkerung machen zu können, muss man noch einen Schritt weiter gehen. Es soll das mittlere Einkommen einer Person berechnet werden, die zwischen den Perzentilen x bis x+h liegt, mit h einem kleinen Schritt. Die unteren x+h Prozent haben das summierte Einkommen I*(x+h)^a, die unteren x Prozent das summierte Einkommen I*x^a. Die Leute zwischen x und x+h verdienen insgesamt I*((x+h)^a-x^a). In diesem Bereich sind x+h-x = h Prozent aller Leute, also h*N Menschen. Das Einkommen pro Person jener zwischen x und x+h ist also:
m(h) = i*((x+h)^a-x^a)/h
Wer schon viel mit Differentialrechnung zu tun hatte, hat jetzt vielleicht ein Deja-Vu-Moment. Alles hinter dem i ist der Differenzquotient bei Ableitung von x^a. Mit Grenzwert h -> 0 kommt man zum Differentialquotient. Dieser drückt das mittlere Einkommen einer Person BEIM Perzentil x aus.
m = lim(h->0) m(h) = i*a*x^(a-1)
Das mittlere Einkommen einer Person beim Perzentil x = 0,95 im Verhältnis zum mittleren Einkommen einer Person beim Perzentil x = 0,05 ist:
r’ = (i*a*0,95^(a-1))/(i*a*0,05^(a-1)) = 19^(a-1)
Daher kommt die obige Näherung für das Verhältnis des mittleren Einkommens von Top 90 % zu Bottom 10 %. Es lässt sich aber auch mehr damit machen. Eine wichtige Frage ist, welcher Anteil der Bevölkerung unter einer gewissen Einkommensgrenze Ig fällt. Damit könnte man zum Beispiel aus dem Gini (mit Umweg über Lorentz) auch den Anteil der Bevölkerung in Armut berechnen, sofern die Einkommensgrenze für Armut bekannt ist. Das mittlere Einkommen Ig wird beim Perzentil Ig = i*a*xg^(a-1) erreicht. Daraus ergibt sich für den Anteil Leute unter der Einkommensgrenze Ig:
xg = (Ig/(i*a))^(1/(a-1))
Es fehlt jetzt noch ein wichtiger Punkt, nämlich: Wie bekommt man den Gini-Index praktisch aus gegebenen Daten?
In der Regel kennt man eine handvoll Datenpunkte im Stile: Die unteren x1 Prozent haben p1 Prozent des Gesamteinkommens, die unteren x2 haben p2, die unteren x3 haben p3, etc … Eine naheliegende Möglichkeit ist der Fit der Daten an die Kurve p = x^a, wobei sich jener Exponent a ergibt, der die Summe der quadratischen Abstände von Punkte zu Kurve minimiert. Steht nur die lineare Regression zur Verfügung, was in den vielen Statistik-Paketen der Fall ist, so kann man einfach die Daten mit y = ln(x) und q = ln(p) transformieren. Es ist dann: q = a*y. Der Exponent a ergibt sich in diesem Fall also aus der Steigung der q-y-Kurve. G folgt stets aus G = (a-1)/(a+1).
Ein schnellerer Ansatz ist, für jeden Datenpunkt den Exponenten zu berechnen und das geometrische Mittel der Exponenten für a zu verwenden. Aus jedem Paar xk und pk folgt ak = ln(pk)/ln(xk). Das Produkt aller ak ist (ln(p1)/ln(x1))*(ln(p1)/ln(x1))*… Bei insgesamt n Datenpunkte davon noch die n-te Wurzel bzw. das hoch 1/n für das geometrische Mittel:
a = ( (ln(p1)/ln(x1))*(ln(p1)/ln(x1))*… )^(1/n)
Ein Beispiel: In einer Bevölkerung haben die unteren x1 = 10 % den Anteil p1 = 0,8 % des gesamten Einkommens, x2 = 20 % den Anteil p2 = 3 % und x3 = 50 % den Anteil 16 %. Über das geometrische Mittel ergibt sich für den Lorentz-Exponenten:
a = ( ln(0,008)/ln(0,1)*ln(0,03)/ln(0,2)*ln(0,16)/ln(0,5) )^(1/3)
a = (2,1*2,2*2,6)^(1/3) = 2,3
Und für den entsprechenden Gini:
G = (a-1)/(a+1) = 1,3/3,3 = 0,39
Der Gini-Koeffizient macht messbar, was sonst nur schwer in Zahlen zu fassen ist, aber für das Funktionieren einer Gesellschaft sehr wichtig ist: Die Ungleichheit. G > 0,4 ist ein guter Indikator dafür, dass ein großer Teil des Geldes in den Taschen weniger verschwindet und beim Rest der Gesellschaft ein gefährlicher Mangel entsteht. Das ist typisch für Länder mit viel Korruption. G um 0,3 drückt hingegen eine gesunde Ungleichheit aus. Eine Ungleichheit, bei der es sich für das Individuum lohnt, mehr Einsatz zu zeigen um mehr Wohlstand zu erhalten, ohne dass die Gefahr besteht, dass Teile der Gesellschaft in Armut abrutschen. G < 0,2 (nirgends beobachtet, aber theoretisch möglich) würde die Motivation für mehr Einsatz jedoch zerstören. Es gäbe dann soviel Umverteilung, dass das Plus, welches man aus dem Einsatz erhält, den Einsatz nicht Wert wäre. Der Gini-Index kann somit als Aussage über die Umverteilung betrachtet werden. Bei G um 0,3 ist das richtige Maß erreicht, für höhere Werte sollte die Umverteilung angekurbelt, für geringere Werte gebremst werden.
Hier noch der Hinweis, dass der Gini, wenn auch gerne auf das Einkommen angewandt, Ungleichheit für jede beliebige Lorentz-verteilte Variable messen kann. Lorentz-verteilt sind zum Beispiel viele der Variablen, die der 80/20-Regel folgen. Etwa: 20 % der Kunden nehmen 80 % der Zeit des Servicepersonals ein. Die 80/20-Regel ist, bei Annahme von Lorentz-Verteilung, identisch mit der Aussage a = 7,2 bzw. G = 0,76 und es gilt alles, was aus den obigen Formel dafür folgt. Auch die Anwendung auf Bundesebene ist kein Muss. Der Gini kann seperat für Regionen und gar einzelne Firmen berechnet werden. Bei all dem sollte man beachten, dass die Faustregel “G um 0,3 ist ideal” dann keine Gültigkeit mehr hat. Diese Grenze ergibt sich aus Erfahrungswerten bei der Anwendung des Gini auf das Einkommen auf Ebene von Ländern. Andere Variablen und andere Entitäten bringen andere Erfahrungswerte.
In diesem Youtube-Video über Suchtverhalten bei Computerspielen wird erwähnt, dass manche Hersteller bei der Monetisierung ihres Spiels eine “Bad Luck Protection” (Schutz vor schlechtem Glück) bieten. Hinter dieser Anmerkung steckt ein interessantes mathematisches Problem.
Bei vielen Spielen gibt es mittlerweile Microtransactions. Statt etwa lange nach einem bestimmten, wertvollen Gegenstand im Spiel zu suchen, kann man sich gegen echtes Geld eine virtuelle Lootbox kaufen und diese öffnen. Mit einer gewissen Wahrscheinlichkeit w hat man Glück und die Box enthält den Gegenstand. Oder man geht leer aus und muss, sofern man den Gegenstand unbedingt möchte, eine weitere Lootbox kaufen. Im Mittel wird man e = 1/w solcher Boxen kaufen müssen bevor man den Gegenstand erhält. Bei w = 0,2 = 20 % also e = 1/0,2 = 5 Boxen. Das e steht für Erwartungswert. Natürlich könnte es schon beim ersten Mal enthalten sein. Oder erst beim zwanzigsten Mal.
Die “Bad Luck Protection” soll absichern, dass letzteres nicht passieren kann. So könnte der Code zum Beispiel garantieren, dass nach neun erfolglosen Versuchen der zehnte Versuch immer funktioniert. Diese Versicherung ist ein Eingriff in die Verteilung der Wahrscheinlichkeiten und ändert entsprechend den Erwartungswert auf einen neuen Wert, der hier mit e’ bezeichnet wird.
Sei n die Anzahl Versuche bis Erfolg. n = 1 soll heißen, dass es beim ersten Versuch schon geklappt hat, n = 2 Erfolg beim zweiten Versuch, etc … Die Wahrscheinlichkeit des Eintretens des Szenarios “Erfolg nach n Versuchen” sei p(n). Die entsprechende Verteilung dieser Wahrscheinlichkeiten nach Implementierung der Bad Luck Protection sei q(n). Die Bad Luck Protection soll Erfolg nach m Versuchen garantieren. Damit gilt für die Verteilung q(n):
q(n) = p(n) für n < m
q(m) = p(m)+p(m+1)+p(m+2)+…
q(n) = 0 für n > m
Sei w die Wahrscheinlichkeit, dass die Lootbox den Gegenstand enthält. Es ist dann:
p(1) = w
p(2) = w*(1-w)
p(3) = w*(1-w)^2
…
p(n) = w*(1-w)^(n-1)
Für den Erwartungswert folgt tatsächlich e = 1*p(1)+2*p(2)+3*p(3)+… = 1/w. Das lässt sich so zeigen. Mit der Abkürzung x = 1-w um sich das Leben etwas einfacher zu machen und mit Zuhilfenahme der Formel unter “Verwandte Summenformel 1” in diesem Wiki-Eintrag ergibt sich:
e = 1*p(1)+2*p(2)+3*p(3)+… = w*(1*1+2*x+3*x^2+…)
e = (w/x)*(1*x+2*x^2+3*x^3+…) = (w/x)*(x/(1-x)^2)
e = w/(1-x)^2 = w/w^2 = 1/w
Was ist der Erwartungswert nach Implementierung der Bad Luck Protection? Die Berechnung geht nach ähnlichem Prinzip, ist aber ziemlich aufwendig. Der Ansatz ist:
Der Erwartungswert reduziert sich durch die Garantie von Erfolg nach m Versuchen also um den Faktor 1-(1-w)^(m-1). Ein Beispiel: Sei die Wahrscheinlichkeit, dass die Lootbox den Gegenstand enthält, w = 0,1 = 10 %. Im Mittel benötigt ein Spieler e = 1/w = 10 Versuche, um den Gegenstand zu erhalten. Bei Garantie auf Erfolg nach maximal m = 20 Versuchen sinkt dieser Erwartungswert auf e’ = 8,6 Versuche. Selbst wenn man die Bad Luck Protection also recht spät ansetzt (nur sehr ungünstige Ausgänge ausschließt), zeigt sich schon ein nennenswerter Einfluss auf den Erwartungswert. Bei Garantie nach m = 15 Versuchen wäre der Erwartungswert e’ = 7,7 Versuche, bei m = 10 wäre e’ = 6,1 Versuche.
Dass Computerspiele mehr und mehr zu Glücksspiel-Automaten verkommen ist natürlich traurig. Vor allem großen Herstellern wie EA geht es vor allem darum, den Spielern mit solchen Mechaniken soviel Geld wie möglich aus der Tasche zu ziehen. Es kostet den Hersteller nichts, einen wichtigen Gegenstand im Spiel extrem selten zu machen. Dafür muss nur eine Zahl im Code geändert werden. So kann man die Spieler vor die Wahl setzen, endlos in der Spielewelt zu “grinden” oder diese Mühe mit dem Kauf einer Lootbox sofort zu beenden. Leider hat sich dieser manipulative Ansatz als sehr lukrativ erwiesen und wird in der Spieleindustrie mittlerweile breit eingesetzt.
Bei einem eindimensionalen Random Walk bewegt sich ein Punkt entlang einer Achse, das sei hier eine Höhenachse, wobei der Punkt bei jedem Zeitschritt mit einer Wahrscheinlichkeit 50 % eine Einheit nach oben und einer Wahrscheinlichkeit 50 % eine Einheit nach unten geht. Ein Höhen-Zeit-Diagramm würde einen Verlauf zeigen, der einem Börsenkurs ähnlich ist. Also eine Abfolge von Zacken nach oben und unten, mit jeweils zufälliger Länge. Die Berechnung von Random Walks (in drei Dimensionen) ist zum Beispiel in der Mechanik von Gasen von Bedeutung.
Eine interessante Variation, wenn auch ohne naheliegenden physikalischen Bezug, ist der Random Walk mit Boden. Hier geht der Punkt bei jedem Zeitschritt mit der Wahrscheinlichkeit p nach oben und 1-p nach unten, wobei p < 50 % sein soll (Tendenz zu Abstieg). Zusätzlich gilt, dass sobald die Höhe h = 0 erreicht wird, der Punkt mit der Wahrscheinlichkeit p auf die Höhe h = 1 steigt oder mit der Wahrscheinlichkeit 1-p auf der Höhe h = 0 bleibt (kein weiterer Abstieg möglich). Angenommen man lässt diesen Random Walk beginnend ab h = 0 laufen und prüft zu einem späteren Zeitpunkt die Höhe. Wie wahrscheinlich ist es, den Punkt auf Höhe h = 0 zu finden? Auf Höhe h = 1? Auf Höhe h = 2?
Das Problem lässt sich gut lösen, wenn man die Übergänge zwischen den Zuständen genauer betrachtet. Die Wahrscheinlichkeit, auf Höhe h zu sein, sei q(h). Auf diese Höhe kann der Punkt einmal durch Aufstieg aus der Höhe h-1 kommen oder durch Abstieg aus der Höhe h+1. Die Wahrscheinlichkeit, dass der Punkt auf Höhe h-1 ist und dann aufsteigt, ist q(h-1)*p. Die Wahrscheinlichkeit, auf Höhe h+1 zu sein und abzusteigen, ist q(h+1)*(1-p). Es gilt also für alle h außer h = 0:
q(h) = q(h-1)*p + q(h+1)*(1-p)
Die Höhe h = 0 wird nur durch Verbleiben auf h = 0 mit Wahrscheinlichkeit 1-p und Abstieg aus Höhe h = 1 erreicht. Daraus ergibt sich analog:
q(0) = q(0)*(1-p) + q(1)*(1-p)
Das lässt sich iterativ lösen. Alternativ und eleganter kann man den exponentiellen Ansatz q(h) = q(0)*x^h machen und erhält durch Einsetzen in die Gleichung für q(h) eine quadratische Gleichung für x, aus welcher x = p/(1-p) folgt. Die Wahrscheinlichkeit, den Punkt auf Höhe h zu finden, ist also:
q(h) = q(0)*(p/(1-p))^h
Das Problem ist noch nicht gelöst. Die Wahrscheinlichkeit des Aufstiegs p ist als bekannt vorrausgesetzt. Die Höhe h wird jeweils gewählt. Unbekannt ist aber noch die Wahrscheinlichkeit, den Punkt auf der Höhe h = 0 vorzufinden, q(0). Ist dieser Wert einmal bekannt, folgen die Wahrscheinlichkeiten für alle anderen Höhen. q(0) lässt sich durch eine einfache Überlegung ermitteln. Zu jedem Zeitpunkt muss der Punkt auf einer Höhe sein. Die Summe aller Wahrscheinlichkeiten muss also 1 = 100 % sein (Normierung).
[Summe über alle h] q(h) = q(0)*(1+x+x^2+x^3+…) = 1
Damit ist das Problem gelöst. Aus der Wahrscheinlichkeit des Aufstiegs p lässt sich berechnen, mit welcher Wahrscheinlichkeit man den Punkt auf Höhe h = 0 vorfindet (oder etwas schöner gesagt, welchen Anteil der Zeit der Punkt auf der Höhe h = 0 verbringt) und daraus lässt wiederum der entsprechende Wert für jede andere Höhe berechnen. Vor einem Beispiel noch die Herleitung der mittleren Höhe. Da bekannt ist, mit welcher Wahrscheinlichkeit eine bestimmte Höhe eingenommen wird, lässt sich relativ schmerzlos die mittlere Höhe des Punktes berechnen:
m = 0*q(0)+1*q(1)+2*q(2)+3*q(3)+…
m = q(0)*(1*x+2*x^2+3*x^3+…)
Aus der Summenformel für Summen über Terme der Form h*x^h, siehe im verlinkten Wiki-Eintrag im Abschnitt “Verwandte Summenformel 1”, folgt die kompakte Form:
m = q(0)*x/(x-1)^2
Mit x = p/(1-p) und viel Umformung:
m = p/(1-2*p)
Ein Beispiel: Ein Punkt bewegt sich nach den Regeln des Random Walks mit Boden entlang einer Höhenachse, wobei der Punkt bei jedem Zeitschritt mit einer Wahrscheinlichkeit p = 0,4 = 40 % aufsteigt und mit 1-p = 0,6 = 60 % absteigt. Der Punkt wird damit q(0) = (1-2*0,4)/(1-0,4) = 0,33 = 33 % der Zeit auf der Höhe h = 0 verbringen. Die Zeit auf beliebiger Höhe h ist q(h) = 0,33*(0,4/(1-0,4))^n = 0,33*0,67^h. Auf Höhe h = 1 wird er also 22 % der Zeit verbringen, auf h = 2 den Anteil 15 % der Zeit, etc … Die mittlere Höhe des Punktes im Laufe der Bewegung ist m = 0,4/(1-2*0,4) = 2.
Der obige Lösungsansatz ist in derselben Form häufig in der Theorie von Warteschlangen zu finden. Auch dort erfolgen die Übergänge stets in benachbarte Zustände. In den Zustand n Kunden in der Schlange kommt man entweder durch Zugang eines Kunden aus dem Zustand n-1 Kunden oder Abfertigung eines Kunden aus dem Zustand n+1 Kunden, wobei im Gegensatz zum Random Walk hier auch der Verbleib im Zustand n Kunden möglich ist. Der Ansatz für die iterative Ermittlung der Wahrscheinlichkeiten des Auffindens der Schlange im Zustand n Kunden hat die Form:
q(n) = q(n)*pv + q(n-1)*pz + q(n+1)*pa
Wobei die Wahrscheinlichkeiten für Verbleib pv, Zuwachs pz oder Abnahme pa wiederum aus der Ankunftsrate und Abfertigungsrate der Kunden berechnet werden und darüber hinaus auch andere Effekte modellieren können (z.B. Tendenz von Kunden zu Vermeidung langer Schlangen). Nimmt man zu der iterativen Gleichung noch die Normierung [Summe über alle n] q(n) = 1 hinzu, dann lässt sich das Problem in der Regel vollständig lösen.
Ich habe vor kurzem zwei Umfragen im Harvard Dataverse gefunden, in welchen die Big-Five der Teilnehmer gemessen und zusätzlich dazu viele Aspekte der Kindheit erfasst wurden. Einer dieser Aspekte war die emotionale Labilität (Neurotizismus) der Eltern. Das hat erlaubt zu prüfen, ob ein Zusammenhang zwischen dem Neurotizismus der Eltern und ihren Kindern besteht. Die Erwartung ist, dass es einen solchen Zusammenhang gibt, da Neurotizismus, wie auch alle anderen Dimensionen der Big-Five, vererbt werden kann. Siehe hier unter Heritability.
In beiden Umfragen habe ich Neurotizismus in eine Ja/Nein-Variable umcodiert. Jeder Teilnehmer mit einem Neurotizismus-Score 0,75 Standardabweichungen über der Norm wurde als “neurotisch” und alle anderen als “nicht-neurotisch” klassifiziert. Diese Variable wurde dann als Zielvariable für ein allgemeines lineares Modell mit den vier unabhängigen Variablen Alter, Geschlecht, Neurotizismus Mutter und Neurotizismus Vater verwendet. Beim Output wurden die Anteile neurotischer Teilnehmer festgehalten.
Man erkennt, dass in beiden Umfragen der Anteil neurotischer Teilnehmer in der Gruppe mit emotional stabiler Mutter ein gutes Stück geringer war als in der Gruppe mit emotional labiler Mutter. Das gleiche Bild ergibt sich für den Vater. Gepoolt ergibt sich das Ergebnis, dass eine emotional labile Mutter das Risiko für hohen Neurotizismus im späteren Leben des Kindes um 90 % erhöht, mit einem 95 % Konfidenzintervall von 30 % bis 170 %. Die statistische Signifikanz des Ergebnisses ist sehr hoch (p < 0,001). Ein emotional labiler Vater erhöht das Risiko für hohen Neurotizismus um 40 %, mit einem Konfidenzintervall von 10 % bis 80 %. Die Signifikanz ist mäßig, aber noch annehmbar (p < 0,05).
Überraschend finde ich, dass diese vier Variablen recht wenig in der Varianz erklären. Nur 10-15 % wird durch das Modell erklärt. Basierend auf der hohen Tendenz der Vererbung von Neurotizismus, wie sie in Studien ermittelt wurde, hätte man mehr Erklärungskraft erwarten können. Ein Grund ist sicherlich die grobe Unterteilung der Skalen. Man kann davon ausgehen, dass man mit einer feineren Unterteilung noch gut auf 20 % kommen könnte. Aber auch das ist noch überraschend wenig.
Inklusion der Beziehung der Eltern untereinander ändert das Ergebnis etwas, aber nicht fundamental. Es bleibt auch danach noch ein 70 % erhöhtes Risiko für hohen Neurotizismus bei einer labilen Mutter und 20 % bei einem labilen Vater. Ein wenig harmonisches Elternhaus bringt aber zusätzliche Erklärungskraft. Bereinigt nach allem anderen im Modell erhöhen zerstrittene Eltern das Risiko für Neurotizismus beim Kind gepoolt um etwa 35 % (p < 0,05). Insgesamt bleibt die erklärte Varianz aber auch damit noch ziemlich niedrig. Von einem umfassenden Modell ist es weit entfernt.
Eine kürzliche Umfrage mit n = 401 Teilnehmern (US-Amerikaner, mittleres Alter 43 Jahre, Spanne von 21 bis 78 Jahre) gibt einen Einblick auf den Effekt der Pandemie auf einige wichtige Aspekte des Lebens. Generell ergibt sich für jede der abgefragten Kategorien im Mittel eine Verschlechterung.
Gewicht
Für den Großteil der Teilnehmer hat sich das Gewicht nicht oder nur etwas verändert. 58 % geben keine Veränderung an, 17 % ein Plus von 5 kg und 7 % ein Minus von 5 kg. Das macht insgesamt 82 % der Teilnehmer mit nur geringen Veränderungen. Bei den restlichen Teilnehmern berichten 14 % von einem Plus >= 10 kg und 4 % von einem Minus >= 10 kg. Es gibt also eine klare Verzerrung in Richtung Zunahme. Auf jeden Teilnehmer mit starker Abnahme kommen 3,5 Teilnehmer mit starker Zunahme.
Korrelativ zeigt sich Neurotizismus (emotionale Labilität) als Risikofaktor für Zunahme während der Pandemie. Bei jenen mit geringem Score auf der Neurotizismus-Skala ist das Verhältnis 3,1 : 1 für starke Zunahme zu starker Abnahme, bei jenen mit hohem Score sind es hingegen 4,9 : 1. Die Signifikanz des Unterschieds ist p < 0,01.
Psychische Gesundheit
Eine sehr deutliche Verzerrung gibt es auch bei der selbstberichteten Veränderung der psychischen Gesundheit. 48 % berichten keine Veränderung. 10 % und 2 % nennen eine moderate bis deutliche Verbesserung, 33 % und 7 % eine moderate bis deutliche Verschlechterung. Auf jeden Teilnehmer, der eine Verbesserung bei sich festgestellt hat, kommen also 3,3 Teilnehmer, die eine Verschlechterung erlebt haben.
Hier sind Geschlecht und Neurotizismus die größten Risikofaktoren. Bei Männern beträgt das Verhältnis von Verschlechterung zu Verbesserung 2,8 : 1, bei Frauen ist es 4,0 : 1 (p < 0,01). Bei Neurotizismus beträgt das Verhältnis 2,6 : 1 unter jenen mit geringem Score und 3,8 : 1 (p < 0,001) unter jenen mit hohem Score. Die Verschlechterung scheint also vor allem unter jenen, die schon vor der Pandemie emotionale Schwierigkeiten hatten, besonders ausgeprägt.
Finanzen
Bei 50 % der Teilnehmer hat die Pandemie keine Veränderung der finanziellen Situation gebracht. Eine moderate und deutliche Verbesserung haben 14 % und 3 % erlebt, eine moderate und deutliche Verschlechterung 23 % und 9 %. Macht ein Verhältnis 1,9 : 1 für Verschlechterung zu Verbesserung.
Hier scheint vor allem die Bildung einen großen Einfluss zu haben. Bei jenen, deren höchster formaler Abschluss das High School Diplom ist, liegt das Verhältnis bei 2,8 : 1 Verschlechterung zu Verbesserung. Bei Teilnehmern mit einem Master’s oder höher ist es hingegen 0,9 : 1 (p < 0,001). In dieser Gruppe gab es demnach sogar leicht mehr Teilnehmer mit Verbesserung statt Verschlechterung.
Alkohol
59 % der Teilnehmer haben keine Veränderung im Alkoholkonsum bemerkt. Moderat und deutlich weniger haben 12 % und 5 % getrunken. Moderat und deutlich mehr 19 % und 6 %. Auf jeden mit Konsumreduktion kommen also knapp 1,5 Teilnehmer mit einer Konsumsteigerung.
Die Veränderung zeigt eine sehr klare Altersabhängigkeit. In der Gruppe 20-29 Jahre ist das Verhältnis von Steigerung zu Reduktion 3,1 : 1. In der Gruppe der 60+ Jahre liegt es recht exakt bei 1 : 1 (p < 0,001). Ein massiver Unterschied.
Interkorrelationen
Die verschiedenen Veränderungen zeigen auch untereinander Korrelationen. Nennenswert ist vor allem die Korrelation zwischen Veränderung psychischer Gesundheit und Veränderung von Finanzen (r = 0,31 mit p < 0,01). Diese beiden Variablen scheinen besonders häufig Hand in Hand zu gehen, im Guten wie im Schlechten. Auch recht eng ist die Korrelation zwischen Veränderung psychischer Gesundheit und Veränderung des Alkoholkonsums (r = 0,25 mit p < 0,01). Die Korrelation zwischen Finanzen und Alkoholkonsum ist hingegen recht schwach (r = 0,14 mit p < 0,05). Die Veränderung des Gewichts zeigt mit keiner der anderen Variablen eine nennenswerte Assoziation (r < 0,15 für alle möglichen Paare).
Die Auswertung einer Umfrage aus dem Harvard Dataverse mit n = 401 Teilnehmern (US-Amerikaner, mittleres Alter 43 Jahre, Standardabweichung 14 Jahre) zeigt vier signifikante Prädiktoren für den Impfstatus, welche insgesamt etwa 30 % der Varianz* im Impfstatus erklären können. Zu wenig, um von einem vollständigen Bild sprechen zu können, aber durchaus ein guter Teil des Bildes. In Reihenfolge der Effektstärke, größte Effektstärke voran, sind die Prädiktoren:
Einschätzung des Risikos eines tödlichen Ausgangs
Wohnumgebung: Urban vs. Ländlich
Politische Positionierung: Links vs. Rechts
Formale Bildung
Unter anderem wurden die Teilnehmer gefragt, wie hoch sie das Risiko eines tödlichen Ausgangs einschätzen, wenn sich ein ungeimpfter und nie-infizierter 60-Jähriger mit dem Virus ansteckt. Die korrekte Antwort lautet circa 0,75 %. Nur 23 % der Teilnehmer lagen nah am korrekten Wert. 14 % haben das Risiko überschätzt, 63 % haben es unterschätzt. Es zeigt sich ein klarer Zusammenhang zwischen Risikoeinschätzung und Impfstatus. Unter jenen, die das Risiko sehr hoch einschätzen, ist die Wahrscheinlichkeit geimpft zu sein 2,3-Mal [1,6, 3,3] höher wie unter jenen, die das Risiko als sehr gering sehen. Dies gilt, wie bei allem folgenden auch, bereinigt nach allen anderen Variablen im Modell.
Ein großer Einfluss zeigt auch die Wohnumgebung. Leute, die mäßig bis sehr urban wohnen, haben eine 1,6-Mal [1,2, 2,3] höhere Wahrscheinlichkeit geimpft zu sein als jene, die sehr ländlich wohnen. Ich denke nicht, dass Zugang hier der ausschlaggebende Faktor ist. In den USA impfen auch ländliche Ärzte schon seit Frühling. Mentalität scheint eine plausiblere Erklärung.
Ähnlich stark ist der Einfluss der politischen Positionierung. Leute, die angeben stark in Richtung Links / Progressiv / Democrat zu tendieren, haben eine 1,5-Mal [1,2, 1,9] höhere Wahrscheinlichkeit geimpft zu sein als jene, die angeben stark in Richtung Rechts / Konservativ / Republican zu tendieren.
Es lohnt sich anzumerken, dass es sich hier um einen seperaten Effekt handelt. Es ist zwar durchaus so, dass eine recht enge Korrelation zwischen Wohnumgebung und politischer Einstellung besteht (in ländlichen Regionen ist der Anteil jener mit konservativen Einstellungen i.d.R. höher), jedoch gilt der Effekt der Wohnumgebung bereinigt nach politischer Positionierung und der Effekt politischer Positionierung bereinigt nach Wohnumgebung. Anders gesagt: In jeder Gruppe mit fixer politischer Positionierung ist der Anteil Geimpfter in der urbanen Gruppe höher als in der ländlichen Gruppe. Und in jeder Gruppe fixer Wohnumgebung ist der Anteil Geimpfter bei Democrats höher als bei Republicans.
Ein weiterer signifikanter Faktor ist formale Bildung. Unter Teilnehmern, die angeben einen akademischen Abschluss (Bachelor’s oder höher) zu haben, ist die Wahrscheinlichkeit geimpft zu sein 1,4-Mal [1,0, 1,7] höher als unter jenen mit High School Abschluss oder niedriger. Wie man am 95 % Konfidenzintervall erkennen kann, erreicht der Effekt aber nur knapp die Marke der statistischen Signifikanz p < 0,05. Alle anderen genannten Effekte sind hingegen sehr solide signifikant mit p < 0,001.
Wie erwähnt erklären diese vier Faktor etwa 30 % der Varianz* beim Impfstatus. Das deutet darauf hin, dass einige relevante Faktoren im Modell fehlen. Einmal wäre hier das Alter zu nennen. Das Alter wurde zwar erfasst, war aber im Modell kein signifikanter Prädiktor obwohl Impfquoten in der Praxis eine sehr deutliche Abhängigkeit mit dem Alter zeigen. Diese Diskrepanz erklärt sich wohl daraus, dass die meisten Teilnehmer im mittleren Alter lagen und somit nur ein kleiner Teil der Skala abgedeckt wurde. Es gab kaum Teilnehmer Anfang Zwanzig oder im Seniorenalter. Und keine Teenager oder Kinder. Eine weitere Variable, die zusätzliche Varianz erklären könnte, wäre die Einstellung zu alternativ-medizinischen Methoden. Ein ausgeprägter Glaube daran können zu mehr Skepsis gegenüber Impfstoffen, die klar in der Schulmedizin zu verorten sind, führen. Auch fehlt im Modell der Druck durch das soziale Umfeld, in Richtung Impfung oder in umgekehrter Richtung, sowie die Härte staatlicher Maßnahmen.
* Bei Modellen wird im ersten Schritt für jede Gruppe der Mittelwert als Schätzwert für die Zielvariable (hier Impfquote) verwendet. Dabei ergibt sich eine Differenz zwischen Schätzwert und realem Wert, die Varianz. Die Hinzunahme einer Variable bringt den Schätzwert näher an den realen Wert. Es wird somit ein Teil der Varianz erklärt. Würde die Hinzunahme einer Variable immer die Hälfte der Strecke zwischen Mittelwert und realem Wert schließen, so wäre die erklärte Varianz 50 %. Man darf sich erklärte Varianz also durchaus geometrisch denken, als die Abdeckung der Strecke zwischen Mittelwert und realem Wert.
Am Thema Träumen beißt sich die Wissenschaft auch heute noch die Zähne aus. Trotz jahrzehntelanger Forschung weiß man nicht, wieso Menschen träumen und ob Träume einen tieferen Sinn bergen. Es gibt gute Theorien, jedoch keine Klarheit. Sicher ist hingegen, dass sich das Erleben von Träumen von Mensch zu Mensch stark unterscheiden kann. Manche träumen praktisch nie. Andere haben jeden Tag intensive Träume. Welche Faktoren sind mit einem lebhaften Traumleben assoziiert?
Zwei Umfragen geben hier Aufschluss. In beiden wurde eine große Bandbreite von Informationen zu Demographie, Persönlichkeit und Lebensführung erhoben. Daneben konnten die Teilnehmer auch auf einer Likert-Skala ihre Zustimmung zu der Aussage “Ich habe oft lebhafte Träume” geben. Umfrage (1) ist eine Stichprobe von n = 571 Teilnehmern, Umfrage (2) von n = 183 Teilnehmern. Nur jene Faktoren, die in beiden Umfragen eine statistisch signifikante Assoziation mit dem Traumleben zeigen, wurden in die Analyse aufgenommen. Das dürfte das Risiko von Trugschlüssen deutlich senken. Die auf diese Weise identifizierten Faktoren sind:
Stimmungsschwankungen
Big-Five-Merkmal Offenheit
Alkoholkonsum
Für beide Umfragen habe ich ein allgemeines lineares Modell eingegeben mit dem Alter sowie den obigen drei Faktoren als unabhängige Variabeln. Dieser Ansatz garantiert, dass man alle Effekte als bereinigt nach allen anderen Faktoren im Modell interpretieren kann. Desweiteren erfassen allgemeine allgemeine lineare Modelle eventuelle Nichtlinearitäten (von denen es einige gab) deutlich besser als ein einfache lineare Regression.
In der Tabelle sieht man das Ergebnis der Analyse. Die aufgeführte Zahl zeigt jeweils das Verhältnis der Anteile lebhafter Träumer in den Gruppen “Stark Ausgeprägt” und “Schwach Ausgeprägt”. So berichten zum Beispiel in Umfrage (1) 58 % derjenigen, die starke Stimmungsschwankungen angeben, von fast täglichen intensiven Träumen, während dieser Anteil bei jenen, die keine Stimmungsschwankungen angeben, nur 29 % ist. Das macht ein Verhältnis 58/29 = 2,0 (siehe Tabelle). Das 95 % Konfidenzintervall ist auch jeweils aufgeführt. Ist die untere Grenze des Intervalls > 1, so ist die statistische Signifikanz des Zusammenhangs mindestens p < 0,05.
Bereinigt nach allem anderen verdoppeln Stimmungsschwankungen das “Risiko” für intensive Träume in etwa. Die hohe Emotionalität im Wachleben scheint sich recht konsequent in der Traumwelt fortzusetzen. Hier die entsprechenden Graphen aus Umfrage (1) und (2), in dieser Reihenfolge.
Diesselbe Erhöhung des Risikos findet man für das Merkmal Offenheit. Das ist sicherlich wenig überraschend wenn man bedenkt, dass Offenheit eng mit Kreativität und Fantasie verbunden ist. Eine hohe Ausprägung davon scheint die Konstruktion einer reichen Traumwelt zu begünstigen.
Hier noch der dreidimensionale Graph aus Umfrage (1), welcher die Anteile lebhafter Träumer in gleichzeitiger Abhängigkeit von Stimmungschwankungen und Offenheit angibt. Unter jenen, die sowohl wenige Schwankungen in der Stimmung sowie einen geringen Score auf der Offenheit-Skala haben, berichten nur etwa 10-20 % von häufigen lebhaften Träumen. Bei Kombination der beiden Merkmale sind es hingegen 50-80 %. Man erkennt am Graphen auch, dass die Abwesenheit eines der beiden Merkmale ein relativ niedriges Risiko garantiert, egal wie das andere Merkmal ausgeprägt ist. Aus den einzelnen Schwankungen im Graphen sollte man sich nicht zu viel machen. Bei n = 571 Leuten und einer Unterteilung in 4 x 4 Gruppen ist jeder Balken der Mittelwert aus nur etwa 35 Leuten.
Daneben spielt auch der Alkoholkonsum eine Rolle. Bei sehr häufigem Konsum ist das Risiko für lebhafte Träume um etwa 50 % erhöht. Die weiten Unsicherheitsintervalle für die jeweiligen Gruppen mit besonders hohem Konsum ergeben sich aus der geringen Anzahl Teilnehmer, auf die das zutrifft.
Das RKI benutzt eine recht simple Methode zur Berechnung des effektiven R-Werts. Die Summe der Fallzahlen der letzten vier Tage werden durch die Summe der Fallzahlen der vorangehenden vier Tage geteilt. Entwickeln sich die Fallzahlen also gemäß der Reihe 100, 200, 300, 400, 500, 600, 700, 800, so folgt für den effektiven R-Wert:
Es lässt sich daraus eine handliche Näherungsformel für den Zusammenhang zwischen der Verdopplungsdauer T der täglichen Neufälle und dem R-Wert herleiten. Angenommen die Neufälle wachsen exponentiell gemäß F = F0*exp(k*t), wobei F0 der Anfangswert, k die Wachstumsrate und t die Zeit ist. Wie man leicht aus der Gleichung F = 2*F0 = F0*exp(k*t) herleiten kann, gilt zwischen der Verdopplungsdauer und der Wachstumsrate der Zusammenhang k = ln(2)/T. Der R-Wert ist:
Ersetzt man als erste Näherung den Zähler mit 4*exp(k*5,5) und den Nenner entsprechend mit 4*exp(k*1,5) oder nimmt alternativ an, dass sowohl für Zähler und Nenner der Term links jeweils groß gegen alle anderen Terme ist, dann ergibt sich:
Rt = (4*exp(k*5,5))/(4*exp(k*1,5)) = exp(k*4)
Und mit k = ln(2)/T schlussendlich:
Rt = exp(2,77/T)
Eine Verdopplung der täglichen Neufälle alle T = 5 Tage übersetzt sich demnach in e hoch 2,77/5 oder Rt = 1,7. Abweichungen von plus / minus 0,1 sind aufgrund der groben Näherung zu erwarten, aber die Formel bietet einen schnellen und verlässlichen Schätzwert. Umgekehrt lässt sich aus der Formel natürlich auch die aktuelle Verdopplungsdauer ohne viel Mühe abschätzen:
T = 2,77/ln(Rt)
Das alles gilt natürlich nur, sofern exponentielles Wachstum, und somit Wachstum mit gleichbleibender Verdopplungsdauer, besteht. Bei stetigem linearem Wachstum, und das eher am Rande, konvergiert der R-Wert von einem anfänglichen Wert über 1 auf lange Sicht immer gegen Rt = 1. Aus F = F0 + m*t folgt:
Möchte man wissen, ob ein Impfstoff hilft oder nicht, dann ist der Königsweg ein kontrolliertes Experiment. Jeder Teilnehmer wird per Zufallsprinzip entweder der Behandlungsgruppe oder der Kontrollgruppe zugewiesen. Die Teilnehmer in der Behandlungsgruppe erhalten den Impfstoff, die Teilnehmer der Kontrollgruppe ein Placebo (z.B. Kochsalzlösung). Am Ende steht immer der Vergleich zwischen beiden Gruppen. Der Unterschied der Gruppen wird berechnet und die statistische Signifikanz geprüft. Damit ist die Frage, ob der Impfstoff hilft oder nicht, beantwortet.
Die Größe Wirksamkeit drückt den Unterschied zwischen der Behandlungs- und Kontrollgruppe elegant in einer einzigen Zahl aus. Es ist schlicht die prozentuale Differenz der Raten zwischen den Gruppen. Angenommen Infektionen treten mit der Rate b Infektion pro 100 Teilnehmer in der Behandlungsgruppe und der Rate k Infektionen pro 100 Teilnehmer in der Kontrollgruppe auf. Dann ist die Wirksamkeit der Intervention bezüglich Infektionen:
w = 100 * (k-b)/k
Bei gleicher Rate von Infektionen (b = k) ergibt sich eine Wirksamkeit w = 0 %. Der Impfstoff hat keinen messbaren Unterschied gebracht. Ist die beobachtete Rate in der Behandlungsgruppe nur halb so groß wie in der Kontrollgruppe (b = 0,5*k), so folgt w = 50 %. Gibt es gar keine Infektionen in der Behandlungsgruppe (b = 0), dann erhält man die Wirksamkeit w = 100 %. Soweit problemlos.
Probleme können aber entstehen, wenn die Ermittlung der Wirksamkeit auf Daten beruht, welche nicht dem oben beschrieben Schema eines randomisierten kontrollierten Experimentes (RCT) folgen. Bei großer Stichprobe garantiert die erwähnte zufällige Verteilung der Teilnehmer auf die beiden Gruppen, dass keine signifikanten Unterschiede bezüglich Risikofaktoren bestehen. Der Anteil Männer ist in beiden Gruppen ähnlich, das mittlere Alter ist ähnlich, Anzahl und Art der Vorerkankungen sind ähnlich, etc … Auch bei Risikofaktoren, die man noch gar nicht kennt, wird kein signifikanter Unterschied bestehen. Nur so kann man sicherstellen, dass am Ende ein unverzerrter Schätzwert der Wirksamkeit steht.
Bei Real-World-Daten zu Impfstoffen sind unterschiedliche Alter in den Gruppen Quelle für viele mögliche Verzerrungen. Zum einen zeigen Studien, dass junge Leute häufiger sozialisieren als ältere Leute. Da jeder Sozialkontakt eine Chance zur Infektion bringt, würde man alleine basierend auf diesem Effekt einen Unterschied in den Gruppen sehen. Bei mehr jungen Leute in der Behandlungsgruppe würde die berechnete Wirksamkeit unter der unverzerrten Wirksamkeit landen und der Impfstoff schlechter aussehen, als er tatsächlich ist. Bei mehr jungen Leuten in der Kontrollgruppe, das ist bei Real-World-Daten zu Coronavirus-Impfstoffen in der Regel der Fall, liegt dann die berechnete Wirksamkeit hingegen über dem unverzerrten Wert.
Bei der Wirksamkeit zu schwerem Verlauf oder Hospitalisierung findet man eine eine Verzerrung in die umgekehrte Richtung. Da ältere Leute im Mittel eine höhere Chance auf einen schweren Verlauf haben, weist eine ältere Behandlungsgruppe (bei Real-World-Daten in der Regel der Fall) überproportional viele schwere Verläufe auf, was die Wirksamkeit unter den unverzerrten Wert drückt. Der Impfstoff scheint also weniger effektiv, als er tatsächlich ist. Eine ältere Kontrollgruppe führt hingegen zu einer Überschätzung der Wirksamkeit des Impfstoffs gegen schweren Verlauf.
Eine deutliche Verzerrung kann auch Genesung bringen. Da Genesung einen Schutz vor Infektion und schwerem Verlauf bietet, wird ein hoher Anteil Genesener in einer Gruppe die entsprechenden Raten drücken. Hier ist die Verzerrung nicht symmetrisch. Bei einem hohen Anteil Genesener in der Kontrollgruppe (Ungeimpfte), wird es dort deutlich weniger Infektionen oder schwere Verläufe geben als bei kompletter Abwesenheit von vorherigen Genesungen. Die berechnete Wirksamkeit landet unter dem unverzerrten Wert und der Erfolg des Impfstoffes wird unterschätzt.
Mehr Genesungen in der Behandlungsgruppe (Geimpfte) dürften hingegen keine so starke Verzerrung bringen. Dies liegt daran, dass der Schutz von Geimpft+Genesen nur etwas höher als der Schutz reiner Genesung ist. Da jeder in dieser Gruppe geimpft wird, ist der Schutz somit nur marginal höher als ohne vorherige Genesungen und die Raten werden entsprechend nur marginal gedrückt. Es wird dann eine Wirksamkeit berechnet, die leicht über dem unverzerrten Wert liegt.
In der Summe betrachtet bringt also jeder Anteil Genesungen eine Verzerrung in Richtung Unterschätzung der Wirksamkeit. Die Verzerrung ist umso größer, je größer der Anteil Genesener ist. Im Gegensatz zu den anderen Variablen, die schon benannt wurden, ist hier also nicht die bloße Gleichverteilung anzustreben, sondern durch vorherige Antikörpertests ein Anteil Null.
Auch Erwartungen können die Wirksamkeit beeinflussen. In kontrollierten Experiment weiß idealerweise kein Teilnehmer, ob er zur Behandlungs- oder Kontrollgruppe gehört. Im echten Leben weiß man hingegen, ob man geimpft ist oder nicht und vermutet entsprechend einen Schutz oder nicht. Die Erwartung eines Schutzes lässt die Vorsicht in den Hintergrund treten und die Bereitschaft zur Sozialisierung steigt. Dadurch sinkt die ermittelte Wirksamkeit gegen Infektionen unter den unverzerrten Wert, welchen man durch ein kontrolliertes Experiment ermittelt hätte. Die Wirksamkeit wird somit unterschätzt. Diesselbe Verzerrung ergibt sich auch, wenn durch staatliche Maßnahmen Geimpfte weniger stark eingeschränkt werden als Ungeimpfte und dadurch mehr sozialisieren.
Eine weitere Quelle für Verzerrungen ist die Abdeckung durch Tests. Bei einem kontrollierten Experiment wird jeder Teilnehmer regelmäßig getestet. Die Testraten in beiden Gruppen sind gleich. Das ist bei Real-World-Daten oft nicht gegeben. Geimpfte unterliegen weniger strengen Testpflichten als Ungeimpfte. Somit entgehen bei Geimpften anteilig mehr Infektionen der Erfassung als bei Ungeimpften. Das gilt vor allem für asymptomatische Infektionen. Asymptomatische Geimpfte kommen der Infektion seltener auf die Spur, da durch die Abwesenheit von Symptomen kein Grund vorliegt, einen Test durchzuführen. Asymptomatische Ungeimpfte würden die Infektion durch die regelmäßigen Tests hingegen eher bemerken. Diese Verzerrung, welche die Wirksamkeit besser aussehen lässt, als sie tatsächlich ist, wird noch dadurch verstärkt, dass der Anteil asymptomatischer Infektionen bei Geimpften zudem höher ist. Dieser Anteil wird also bei Geimpften also nicht nur schlechter erfasst, sondern nimmt in dieser Gruppe gleichzeitig einen größeren Raum ein.
Man sieht, dass die Quellen für Verzerrungen endlos sind. Und wie wichtig kontrollierte Experimente sind. Nur bei diesen wird der unverzerrte Wert gemessen. Bei Real-World-Daten werden häufig Bereinigungen vorgenommen, um der realen Wirksamkeit näher zu kommen, doch dies gerät schnell an Grenzen. Während Bereinigungen nach Alter noch recht einfach sind, ist der Anteil Genesener in den Gruppen oft nicht bekannt. Dazu müsste man bei jedem Teilnehmer einen Antikörpertest durchführen. Bei Stichproben, welche nicht selten in die Millionen reichen, keine einfache Sache. Wie stark sich Erwartungen von Schutz und unterschiedliche Regeln auf die Wirksamkeit auswirken, kann bestenfalls grob geschätzt werden. Ebenso die Dunkelziffer bei asymptomatischen Infektionen. Sorgfältig bereinigte Real-World-Daten haben durchaus Aussagekraft und geben eine gute Vorstellung davon, wo die Wirksamkeit in etwa liegt, aber auch Bereinigung kann sie nicht auf eine Stufe mit den Ergebnissen kontrollierter Experimente bringen.
Basierend auf einer Umfrage mit n = 183 Teilnehmern (mittleres Alter 42 Jahre) lassen sich drei Aspekte identifizieren, die mit dem Konsum harter Drogen assoziiert sind. In der Umfrage wurde neben gängigen demographischen Daten, der Big-Five-Persönlichkeit und Erfahrungen der Kindheit auch die Erfahrung der Teilnehmer mit harten Drogen erfasst. Gefragt wurde, ob die Teilnehmer jemals Stimulanzien, Psychedelika oder Benzos konsumiert haben. Beispiele für diese Drogenklassen wurden jeweils in Klammern angeführt. Die Teilnehmer hatten für jede der drei Fragen die drei Antwortoptionen “Nein”, “Ja, einmal” und “Ja, mehrmals”. Die Antworten wurden umcodiert auf die Werte 0, 1 und 2 und für jeden Teilnehmer die Summe der drei Fragen gebildet. Diese Skala reichte am Ende also vom Wert 0 (bei jeder Frage Nein) bis 6 (bei jeder Frage Ja, mehrmals). Die Interkorrelation der Antworten auf die drei Fragen war hoch genug um die Zusammenfassung zu einer Skala zu rechtfertigen.
Ein allgemeines lineares Modell führt zu folgendem Ergebnis:
Eine deutliche Assoziation zeigt sich mit dem Big-Five-Merkmal Neurotizismus. Hierbei handelt es sich um einen Merkmalkomplex, der etwa die Tendenz zu depressiver Verstimmung und emotionaler Instabilität umfasst und über den Verlauf des Lebens recht stabil bleibt. Leute mit hohen Werten auf der Neurotizismus-Skala berichten (bereinigt nach allen anderen Variablen im Modell, inklusive Alter) im Mittel von mehr Erfahrung mit harten Drogen. Vor dem Hintergrund, dass Drogen eine kurzzeitige Abhilfe bei solchen emotionalen Zuständen bringen kann, sicherlich keine Überraschung. Man kann hier eine Selbstmedikation in akuten Phasen vermuten.
Interessant ist die Assoziation mit Machiavellismus. Machiavellismus ist eines der drei Merkmale der sogenannten dunklen Triade und erfasst die Bereitschaft einer Person, andere Menschen zu täuschen um einen egoistischen Vorteil zu erlangen. Leute, bei denen diese Bereitschaft stärker ausgeprägt ist, berichten von mehr Erfahrungen mit harten Drogen. Das ist nicht einfach zu interpretieren da alleine aufgrund der Illegalität der Drogen eine gewisse Notwendigkeit zur Täuschung anderer gegeben ist. Ist es schlicht das, was die Assoziation erzeugt? Ich vermute nein. Auch bei legalen Drogen zeigt sich im Datensatz eine Assoziation mit Machiavellismus, jedoch in schwächerer Form. Die Illegalität dürfte also nur einen Teil der Assoziation erklären.
Eine weitere signifikante Assoziation findet sich bei den Erfahrungen in der Kindheit. Menschen, die als Kinder die Eltern als zerstritten und in Feindschaft zueinander erlebt haben, zeigen auch bereinigt nach allem anderen Variablen im Modell eine erhöhte Tendenz zu harten Drogen. Der Konsum könnte in diesem Fall eine Flucht vor diesen unangenehmen Erfahrungen sein. Diese Erklärung ist nur Spekulation, aber sicher ist, dass im Bezug auf harte Drogen ein solches Elternhaus eine Spur hinterlässt.
Eine schwache Assoziation an der Grenze zur Signifikanz gibt es auch mit dem Big-Five-Merkmal Offenheit. Dieser Komplex umfasst Dinge wie etwa Kreativität, Fantasie, Neugier und alles ähnliche. Menschen mit hohem Score diesbezüglich berichten von mehr Erfahrung mit harten Drogen. Trotz der knappen Signifikanz würde ich hier von einem echten Effekt ausgehen da es akademische Studien gibt, die zumindest für Psychedelika diesen Zusammenhang auch feststellen. Siehe etwa hier und hier.
Das höchste Risiko für den Konsum harter Drogen haben demnach emotional instabile Menschen aus zerstrittenem Elternhaus, mit einer Begünstigung des Risikos bei hoher Bereitschaft zu Täuschung anderer und hoher Offenheit. Ein vergleichsweise geringes Risiko besteht entsprechend bei emotional stabilen Menschen aus intaktem Elternhaus. Wie erwähnt ist die Interkorrelation der Antworten für die verschiedenen Drogenklassen sehr hoch. Bei Leuten, die schon Erfahrungen mit Stimulanzien gemacht haben, ist die Wahrscheinlichkeit ziemlich hoch, dass sie auch bei anderen Drogenklassen schon zugegriffen haben. Die Mechanismen, die zum Konsum von Stimulanzien führen, sind im Großen und Ganzen dieselben, die zum Konsum von Psychedelika und Benzos führen.
Die Erfahrungen mit Opiaten, welche auch abgefragt wurden, zeigen hingegen einen andere Risikofaktoren und wurden aus diesem Grund auch nicht in die Skala aufgenommen. Ich vermute dieser Unterschied liegt daran, dass Opiate im Gegensatz zu den anderen drei Drogenklassen auch bei rein medizinischen Problemen (starke Schmerzen nach einer Operation etwa) verschrieben werden.
Ein allgemeines lineares Modell wurde gewählt, weil es nichtlineare Zusammenhänge deutlich besser erfassen kann als ein simples Regressionsmodell ohne vorherige Transformation der Variablen. Jedoch wurden die unabhängigen Variablen für das allgemeine lineare Modell in Kategorien unterteilt, wodurch Information verloren geht. Insgesamt erklärt das Modell knapp 40 % der Varianz in den Erfahrungen mit harten Drogen, was einer beachtlichen Erklärungskraft entspricht. Zu Schwarz-Weiß-Denken sollte es nicht verleiten. Es gibt auch viele stabile Menschen aus harmonischem Elternhaus, die Erfahrungen mit harten Drogen machen. Man sollte jede Variable immer nur als Risikofaktor interpretieren.
Der Datensatz, auf dem diese Analyse basiert, ist nicht sonderlich groß (n = 183), zur Erfassung der stärksten Effekte reicht die Stichprobe aber aus. Das Verhältnis der Geschlechter ist in der Umfrage ausgeglichen (49 % Männer und 51 % Frauen), das mittlere Alter beträgt 42 Jahre, reichend von 19 Jahren bis 73 Jahren. Personen mit hohen Bildungsgrad sind in der Umfrage im Vergleich zur allgemeinen Bevölkerung deutlich überrepräsentiert. Jeder Teilnehmer hat den Wohnsitz in den USA.
Die Tendenz zu paranoidem Denken wurde über vier Items gemessen, welche dann zu einer Skala zusammengefasst wurde. Die Interkorrelation der Items war sehr hoch, was die Zusammenfassung zu einer Skala rechtfertigt. Diese vier Items sind (Übersetzung von mir):
Manchmal lese ich versteckte beleidigende oder bedrohliche Bedeutungen in harmlose Anmerkungen
Ich zögere mich anderen zu öffnen weil ich befürchte dass diese Informationen in bösartiger Weise gegen mich verwendet werden könnten
Ich hege tiefe Zweifel über die Loyalität und Vertrauenswürdigkeit von Freunden, Familie und Kollegen
Ich vermute dass andere mich ausbeuten, betrügen oder schädigen
Insgesamt finden sich sechs Prädiktoren, welche die Varianz in der Skala zu R² = 58 % erklären. Das ist ein exzellentes Ergebnis für ein Regressionsmodell. Wie immer bei Regression ist die Effektstärke einer Variable bereinigt nach allen anderen Variablen im Modell gegeben.
Der signifikanteste Prädiktor ist Neurotizismus (emotionale Instabilität). Menschen, die einen hohen bis sehr hohen Wert auf der Neurotizismus-Skala erreichen, liegen auf der Paranoia-Skala circa 0,8 SD (Standardabweichungen) über jenen mit höchster emotionaler Stabilität.
Neurotizismus alleine reicht aber nicht, um paranoides Denken zu erklären. Neurotizismus ist sozusagen notwendig, aber nicht hinreichend. Eine hohe Tendenz zu paranoidem Denken ergibt sich vor allem bei der Kombination aus hohem Neurotizismus und Aberglauben (gemessen an Zustimmung zu Existenz von Geistern, Existenz von Wahrsagern sowie Glaube an astrologischen Sternzeichen). Auch hier beträgt der bereinigte Unterschied der Gruppen etwa 0,8 SD.
Überraschend stark ist auch der Einfluss einer strikte Erziehung. Menschen, die von strikter Erziehung berichten, erzielen deutlich höhere Werte auf der Paranoia-Skala als jene mit laisser-faire Erziehung. Mit einem Unterschied von 0,6 SD noch ein ziemlich ordentlicher Effekt.
Recht unerwartet war folgender Zusammenhang: Jene, die angeben unter einem chronischen kröperlichen Problem zu leiden (wie etwa chronische Schmerzen), zeigen im Mittel auch erhöhte Werte auf der Paranoia-Skala. Die Effektstärke ist hier 0,5 SD. Könnte das ein Effekt von dauerhaftem Stress sein?
Das Alter zeigt bereinigt nach allem anderem ebenso noch einen signifikanten Einfluss. Paranoides Denken ist jenseits der 30 schon seltener zu finden als in den 20ern, und jenseits der 40 sogar noch seltener als in den 30ern. Die Abnahme mit dem Alter ist ohne Bereinigung sogar noch deutlicher da Neurotizismus selbst im Mittel recht stark mit dem Alter abnimmt.
Nicht signifikant in einer ANOVA (aber noch signifikant im Trend) ist der Einfluss von sozialer Unterstützung durch Freunde und Familie. Hoher sozialer Support scheint das Risiko für paranoides Denken etwas zu senken, jedoch nur mit einer Effektstärke um 0,2-0,3 SD. Ob sich dieser Effekt reproduzieren ließe ist fragwürdig.
Aus dem Modell lässt sich eine höhere Prävalenz von paranoidem Denken bei Frauen vermuten, was eine Analyse der deskriptiven Statistiken getrennt nach Geschlecht bestätigt. 6,5 % der Frauen stimmen jeder der Aussagen zu, während dies bei Männern nur 3,3 % sind. Also eine etwa doppelt so hohe Prävalenz bei besonders ausgeprägtem paranoiden Denken mit einer Signifikanz p < 0,01. Das liegt schlicht daran, dass Frauen im Mittel einen höheren Wert auf der Neurotizismus-Skala erreichen und gleichzeitig im Mittel auch abergläubischer sind. Beides sind oft reproduzierte Ergebnisse.
Basierend auf diesen Ergebnissen kann man paranoides Denken also in erster Näherung als eine Kombination von emotionaler Instabilität und Aberglaube verstehen, mit strikter Erziehung und körperlichen Problemen (Stress im Allgemeinen?) als zusätzliche Triebkräfte sowie einem typischen Abklingen mit dem Alter. Wie immer der Disclaimer, dass Umfragen niemals Ursache und Wirkung feststellen können, das geht nur mit randomisierten kontrollierten Experimenten. Es handelt sich bei allem hier festgestellten ausschließlich um Assoziationen.
Ich habe vor kurzem alle Datensätze gesammelt, die ich zum Thema subjektivem Zeitempfinden finden konnte, um zu prüfen, ob es Zusammenhänge gibt, die über unabhängige Umfragen beständig sind. Hypothesentests bieten zwar einen einen guten Schutz davor, rein zufällige Zusammenhänge in der Stichprobe fälschlicherweise als signifikant einzustufen, aber Reproduktion ist immer noch der Königsweg um Trugschlüsse zu vermeiden. Wenn ein Zusammenhang tatsächlich existiert, dann muss sich dieser auch reproduzieren lassen.
Methode
Ich habe über das Harvard Dataverse sechs Datensätze gefunden, in denen die Teilnehmer Zustimmung zu Aussagen geben konnten, die ein beschleunigtes Zeitempfinden messen. Etwa Aussagen wie “I feel that time just flies by” oder “I’m shocked at how quickly time has passed since last Christmas”. Zustimmung konnte stets über eine Likert-Skala mit vier, fünf oder sechs Abstufungen gegeben werden, von “strongly disagree” bis “strongly agree”.
In manchen Umfragen wurden die jeweiligen Variablen, ob nun subjektives Zeitempfinden, Routine oder etwas anderes, über Zustimmung zu einer einzelnen Aussage gemessen, in anderen Umfragen über Zustimmung zu mehreren Aussagen mit anschließender Zusammenfassung zu einer Skala. Letzteres ist natürlich immer zu bevorzugen.
In jedem Datensatz habe ich eine einfache lineare Regression gemacht mit dem subjektiven Zeitempfinden als Zielvariable und den folgenden Variablen (falls vorhanden) als unabhängige Variablen: Alter, Anzahl Kinder sowie Werte auf den Skalen zu Routine, Beschäftigkeit, Tagträumerei / Innenfokus. Festgehalten wurde jeweils der standardisierte Regressionskoeffizient ß, die erklärte Varianz R² und ein Score, der reflektiert, wie gut die Residuen einer Normalverteilung folgen.
Resultate
Ein wenig überraschendes Resultat: Die Zustimmung zu Aussagen, die beschleunigtes Zeitempfinden messen, ist im Mittel umso größer, je älter ein Teilnehmer ist. Der Zusammenhang ist ziemlich beständig über verschiedene Umfragen, aber mit ß = 0,11 nicht sonderlich groß (dieser Wert gibt immer die Effektstärke bereinigt nach allen anderen Variablen im Modell an). Das deutet darauf hin, dass das biologische Alter, wenn auch relevant, weniger bestimmend auf das Zeitempfinden ist als die Lebensführung.
Einen stärkeren Einfluss hat die Beschäftigkeit, gemessen über Aussagen wie “Ich habe soviel zu tun dass ich kaum dazu komme, mich einfach mal zu entspannen” oder “Ich habe soviele Aufgaben zu erledigen, dass ich oft gar nicht mehr hinterherkomme”. Über vier Umfragen war höhere Beschäftigkeit klar mit mehr Zustimmung zu einem beschleunigten Zeitempfinden assoziiert. Um die Effektstärke etwas greifbarer zu machen: ß = 0,19 bedeutet grob, dass unter jenen, die von wenig Beschäftigkeit berichten (Cut-Off bei z <= -2/3), ein Anteil 18 % ein sehr deutlich beschleunigtes Zeitempfinden (z >= 2/3) hat, während es unter jenen, mit hoher Beschäftigkeit, ein Anteil 34 % ist. Beschäftigkeit bringt also fast eine Verdopplung des “Risikos”.
Auch viel Routine im Leben ist unabhängig davon ziemlich stabil mit einem stärker beschleunigten Zeitempfinden assoziiert. Leute die berichten, dass sie im Alltag die Dinge immer zu gleichen Zeiten erledigen, immer zu gleichen Zeiten aufstehen und schlafen gehen, abends immer diesselben Dinge tun, etc … zeigen vermehrt das Gefühl, dass ihnen die Zeit durch die Hände rinnt. Mit denselben Cut-Off-Werten lässt sich ß = 0,15 wie folgt übersetzen: In der Gruppe “wenig Routine” berichten (bereinigt nach allen anderen Variablen) 20 % von einem deutlich beschleunigtem Zeitempfinden, in der Gruppe “viel Routine” sind es 32 %.
Diese beiden Aspekte dürften erklären, wieso ein beschleunigtes Zeitempfinden in der Praxis viel stärker mit dem biologischen Alter assoziiert wird als es in den Regression der Fall ist. Leute tendieren im Laufe des Arbeitslebens zu mehr Beschäftigkeit und mehr Routine, was sich dann zu dem reinen Effekt des biologischen Alters addiert.
Ein anderer stabiler Effekt findet sich in einer ganz anderen Richtung: Innenfokus. Leute die berichten, viel in ihrem Kopf zu leben, etwa durch Tagträumerei, durch ständige Reflektion der eigenen Perspektiven und Meinungen oder durch ständige Analyze des eigenen Verhaltens, zeigen mehr Zustimmung zum beschleunigten Zeitempfinden. Der Effekt ist in etwa so stark wie jener von hoher Routine. Daneben gibt es noch eine stabile, aber sehr schwache positive Assoziation mit der Anzahl Kinder.
Technisches
Die genannten Variablen können etwa 12 % der Varianz im subjektiven Zeitempfinden erklären. Also auch wenn die Assoziationen allesamt relevant sind und eine hohe statistische Signifikanz aufweisen (p < 0,001), bleibt der größte Teil der Varianz unerklärt. Es muss noch andere Aspekte geben, die einen deutlichen Einfluss auf das subjektive Zeitempfinden haben, aber in den Umfragen nicht gemessen wurden. Und vielleicht auch gar nicht über Umfragen gemessen werden können.
Die Residuen (Vorhersagefehler) waren in einem Fall sehr gut normalverteilt, in vier Fällen mäßig normalverteilt und in zwei Fällen unzureichend normalverteilt. Das ist kein sonderlich gutes Resultat für ein Regressionsmodell, jedoch ist die erklärte Varianz so gering, dass die Verteilung der Vorhersagefehler mehr die Verteilung der Zielvariable reflektiert als die Güte des Modells. Vor dem Hintergrund darf man es wohl als akzeptabel werten.
Warnung & Viel Spekulation
Man sollte sich hüten vor kausalen Schlussfolgerungen. Alle Effekte sind bloße Assoziationen, Aussagen über Ursache und Wirkung sind nicht möglich. Nur weil etwa Innenfokus mit einem beschleunigten Zeitempfinden assoziiert ist, bedeutet das nicht, dass ein Abtrainieren davon eine Änderung bringen wird. Der Zusammenhang könnte auf zufällige Weise über eine verborgene, nicht gemessene Variable entstehen.
Um das mit einem blöden Beispiel zu verdeutlichen: Eine höhere Temperatur bringt mehr Eisverkauf und mehr Frauen in Bikinis. Es besteht also eine klare Assoziation zwischen Eisverkauf und Frauen in Bikinis. Bei einem Mangel an Frauen in Bikinis wird man dem Problem aber nicht mit Werbekampagnen für Eis begegnen können. Dieser könnte zwar den Eisverkauf ankurbeln, aber solange sich an der Temperatur nichts ändert, bleibt der Bikini-Mangel trotz aller Mühen erhalten. Gerade in der Psychologie ist es schwierig bis unmöglich, die tatsächlichen kausalen Zusammenhänge zu finden. Nur kontrollierte Experimente können das und diese sind sehr teuer bzw. ethisch oft gar nicht möglich.
Ein bisschen Spekulation kann man trotzdem wagen. Wenn in der Luft- oder Raumfahrt mehrere Systeme gleichzeitig versagen, gilt die erste Frage der Kommunalität. Was ist den Systemen gemeinsam? Ähnlich kann man fragen: Was ist Beschäftigkeit, Routine und Innenfokus gemeinsam? Gibt es eine Gemeinsamkeit, die auf einen Streich die Assoziation mit dem Zeitempfinden erkläret?
Eine naheliegende Idee sind automatisierte Prozesse. All diese Dinge macht man für gewöhnlich “auf Autopilot”. Trinkt man schon seit Jahren zur Mittagspause Kaffee und geht danach noch eine Runde spazieren, tendiert man wohl dazu, diese Automation ohne besondere Gründe nicht zu hinterfragen oder zu unterbrechen. Nicht selten werden Handlungen zu Routine, weil sie das Wohlsein fördern (ob sofort in dem Moment oder in der Zukunft) und sich auch gut in den Alltag integrieren lassen. Ein ständiges Hinterfragen und Unterbrechen wäre dann sogar kontraproduktiv. Es besteht ein guter Anreiz, die Automation beizubehalten.
Auch bei hoher Beschäftigkeit ist bewusstes Unterbrechen der Automation selten von Vorteil. Man möchte den Berg an Aufgaben so schnell wie möglich und idealerweise ohne übermäßige Strapazen der Kraft abarbeiten. Beides wird durch eine gut geübte Automation gefördert. Mit Autopilot durch und dann die wohlverdiente Entspannung genießen scheint ein vernünftiger Ansatz.
Bei dem Innenfokus und der Tagträumerei kann man auch einen hohen Grad an Automation unterstellen. Lässt man den Gedanken freien Lauf, so hangeln diese sich für gewöhnlich von engster Assoziation zu engster Assoziation: Auto – Maschine – Arbeit – Wochenende – Wandern – etc … Es gibt sehr wenig bewusste Steuerung in einem solchen Narrativ. Eine bewusste Steuerung wäre etwa das Unterbrechen dieser Assoziationskette und der Wechsel zu einem wenig naheliegenden Thema. Was hier und da sicherlich geschieht, aber beim gewohnten “vor sich hinhirnen” vermutlich die Ausnahme bleibt.
Man kann also argumentieren, dass all diesen Einflüssen auf das subjektive Zeitempfinden der hohe Grad an Automation gemeinsam ist. Und jedes Zulassen von Automation eine Art “Zeitlücke” in der inneren Uhr hinterlässt, welche sich in der Summe und bei retrospektiver Wertung in einem Gefühl eines beschleunigten Zeitflusses niederschlägt. Diese Erklärung wäre im Einklang mit allen oben festgestellten empirischen Ergebnissen, ist aber nur pure Spekulation.
Die Perspektive “Zulassung eines automatisierten Prozesses” finde ich, das eher am Rande, viel greifbarer als die Perspektive “Abwesenheit des bewussten Erlebens”. Zwar bedeutet beides wohl etwas ähnliches, oder läuft zumindest beides auf ein ähnliches Resultat hinaus, aber da sich Bewusstein kaum bis gar nicht definieren lässt und automatisierte Prozesse hingegen ziemlich gut, ist das Argumentieren mit der ersten Perspektive deutlich angenehmer.
Es bietet sich natürlich an diesem Punkt auch an, die Brücke zu Mindfulness zu schlagen, da diese auf gewisse Weise ein Gegenteil zum oben beschriebenen Innenfokus und automatisierten Leben darstellt. Ist der Erklärungsansatz mit automatisierten Prozessen korrekt, so sollte man eine negative Assoziation zwischen Mindfulness und beschleunigtem Zeitempfinden finden können. Andere mögliche Tests könnten über den Konsum von Drogen laufen. Eine Zigarette an einem stressigen Tag kann eine bewusste Unterbrechung des automatisierten Abarbeitens bieten. Der Konsum von Psychedelika kann eine deutliche Unterbrechung der Routine und einen intensiveren Außenfokus bringen. Auch eine Assoziation mit manchen Psychopathologien müsste zu finden sein, etwa bei psychischen Krankheiten, die dem Betroffenen die Aufrechterhaltung von Routinen und Beruf kaum möglich machen.
Um gleich mal mit der Tür ins Haus zu fallen: Frauen sind deutlich abergläubischer als Männer. Dieses Ergebnis zeigt sich in sehr beständiger Weise über vier unabhängige Umfragen mit jeweils n = 174, n = 183, n = 195 und n = 236 Teilnehmern. Die Teilnehmer wurden gebeten, ihre Zustimmung zu einigen Aussagen kundzutun. Je nach Umfrage konnten sie die Zustimmung entweder mittels der Wahl einer von vier Optionen geben (Strongly Disagree, Disagree, Agree, Strongly Agree) oder einer von sechs Optionen (Strongly Disagree, Disagree, Slightly Disagree, Slightly Agree, Agree, Strongly Agree). Die Aussagen, welche sich auf Aberglaube beziehen, waren:
Es gibt Menschen, die mit Toten sprechen können (Mediums)
Es gibt Menschen, die die Zukunft sehen können (Psychics)
Das Sternzeichen (Zodiac Sign) sagt viel über einen Menschen aus
Ich glaube an Reinkarnation
Bei jeder der Umfragen sowie bei jeder der Fragen ist die Zustimmung zu diesen Aussagen unter Frauen ein gutes Stück höher als unter Männern. Wertet man Agree und Strongly Agree als Zustimmung, so ist der Anteil abergläubischer Menschen unter Frauen grob dreimal höher als unter Männern. Hier die jeweilige prozentuale Zustimmung sowie das arithmetische Mittel:
(1) n = 174
(2) n = 183
(3) n = 195
(4) n = 236
AVERAGE n = 788
Women Mediums
11,7 %
7,1 %
11,0 %
17,4 %
11,8 %
Men Mediums
4,9 %
2,2 %
1,8 %
6,1 %
3,8 %
Women Psychics
7,3 %
6,2 %
9,8 %
16,5 %
10,0 %
Men Psychics
6,1 %
3,3 %
2,7 %
4,3 %
4,1 %
Women Zodiac
9,5 %
8,3 %
–
11,6 %
9,8 %
Men Zodiac
3,7 %
4,4 %
–
3,5 %
3,9 %
Women Reincarnation
–
–
–
19,0 %
19,0 %
Men Reincarnation
–
–
–
5,2 %
5,2 %
Und das Verhältnis der Prozente sowie das geometrische Mittel:
(1) n = 174
(2) n = 183
(3) n = 195
(4) n = 236
AVERAGE n = 788
OR Mediums
2,4
3,2
6,1
2,8
3,4
OR Psychics
1,2
1,9
3,6
3,8
2,4
OR Zodiac
2,6
1,9
–
3,3
2,5
OR Reincarnation
–
–
–
3,6
3,6
Gepoolt ist die Signifikanz der Unterschiede der Mittelwerte stets p < 0,001
Beim Thema Sternzeichen dürften die Resultate für viele keine besondere Überraschung sein. Eine höhere Tendenz zum Glauben daran haben wohl einige schon im Alltag bei Frauen beobachtet. Interessant ist aber, dass sich diese Tendenz in ähnlicher oder sogar stärkerer Weise auch bei allen anderen weit verbreiteten Aberglauben zeigt.
Eine Analyse der Korrelationen bestätigt den Zusammenhang mit dem Geschlecht und bringt noch einige andere relevante Variablen zum Vorschein. Aberglaube ist in dieser Analyse eine Skala, welche sich durch die Summe der Antworten auf die obengenannten Fragen bildet. Das ist generell verlässlicher als eine Aufspaltung in Prozente. Letzteres hilft zwar die Ergebnisse zu veranschaulichen, aber bei der Trennung in Zustimmung Ja/Nein geht notwendigerweise viel Information verloren. Die Analyse der Korrelationen behält hingegen die Grauzonen teilweiser Zustimmung.
(1) n = 174
(2) n = 183
(3) n = 195
(4) n = 236
Gender
-0,22
-0,09
-0,32
-0,34
Age
-0,09
-0,08
0,04
-0,05
Extro
0,11
0,18
-0,01
0,10
Agree
0,08
-0,14
0,10
0,22
Open
0,11
0,02
0,05
0,08
Neuro
0,07
0,26
0,18
0,06
Paranoid
–
0,52
–
–
Religious
0,27
0,31
0,31
0,46
Dasselbe nach Bereinigung nach Geschlecht:
(1) n = 174
(2) n = 183
(3) n = 195
(4) n = 236
Gender
0,00
0,00
0,00
0,00
Age
-0,14
-0,10
0,01
-0,07
Extro
0,18
0,19
0,03
0,12
Agree
0,05
-0,15
0,06
0,18
Open
0,14
0,03
0,10
0,05
Neuro
-0,02
0,27
0,11
0,00
Paranoid
–
0,52
–
–
Religious
0,24
0,29
0,34
0,47
Den stärksten Zusammenhang zeigt Aberglaube, sowohl vor als auch nach Bereinigung, mit Religiosität. Menschen, die an Gott glauben bzw. sich als religiös beschreiben, zeigen im Mittel eine höhere Zustimmung zu abergläubischen Aussagen als jene, die das nicht tun. Eine genauere Analyse deutet aber auf einen nichtlinearen Zusammenhang hin. Die obige Tendenz gilt nur im Bereich keiner bis moderat starker Religiosität. Bei hoher Religiosität scheint die Zustimmung zu Aberglauben wieder abzusinken.
(1) n = 174
(2) n = 183
(3) n = 195
(4) n = 236
Nur in Umfrage (3) fehlt die Umkehrung in Richtung weniger Aberglaube bei sehr hoher Religiosität. Eventuell gab es hier schlicht nicht genügend hoch-religiöse Personen in der Umfrage, um den Effekt zu sehen (sofern er real ist).
Nach Bereinigung nach Geschlecht und Religiosität gibt es in der Tabelle keinen nennenswerten Korrelationen mehr. Zwar bleiben einige Korrelationen beständig in eine Richtung und haben gepoolt auch einen hohe statistische Signifikanz, die Effektstärke ist aber so niedrig, dass der Zusammenhang keine praktische Relevanz hat. Höchstens für theoretische Überlegungen könnten diese mageren Zusammenhänge von Interesse sein:
(1) n = 174
(2) n = 183
(3) n = 195
(4) n = 236
Gender
0,00
0,00
0,00
0,00
Age
-0,13
-0,02
-0,02
-0,14
Extro
0,11
0,02
0,00
0,02
Agree
0,00
-0,10
-0,01
0,10
Consc
-0,08
-0,14
-0,11
-0,10
Open
0,09
0,07
0,09
0,10
Neuro
0,04
0,25
0,14
0,11
Paranoid
–
0,38
–
–
Religious
0,00
0,00
0,00
0,00
Ein starker Effekt bleibt jedoch noch, leider wurde die entsprechende Skala nur in einer der vier Umfragen abgefragt. Eine Reproduktion gibt es davon also nicht. Aber zumindest gemäß Umfrage (2) existiert eine starke positive Assoziation zwischen der Zustimmung zu abergläubischen Aussagen und der Zustimmung zu Aussagen, die paranoide Gedankenmuster erfassen. Die in der Umfrage verwendeten Aussagen waren (meine Übersetzung):
Manchmal lese ich versteckte beleidigende oder bedrohliche Bedeutungen in harmlose Anmerkungen
Ich zögere mich anderen zu öffnen weil ich befürchte dass diese Informationen in bösartiger Weise gegen mich verwendet werden könnten
Ich hege tiefe Zweifel über die Loyalität und Vertrauenswürdigkeit von Freunden, Familie und Kollegen
Ich vermute dass andere mich ausbeuten, betrügen oder schädigen
Wie bei allem, was nicht aus kontrollierten Experimenten kommt, gilt hier: Nichts davon kann eine Aussage über Ursache und Wirkung machen. Es kann sein, dass Aberglaube Paranoia verursacht. Oder Paranoia Aberglaube verursacht. Oder dass es eine nicht gemessene Sache gibt, dass beides verursacht und gar kein kausaler Zusammenhang zwischen Aberglaube und Paranoia besteht. Ähnliches gilt auch für den Zusammenhang mit dem Geschlecht und Religiosität. Dass die Resultate nur auf Sampling Bias basieren ist hingegen extrem unwahrscheinlich, da diese (bis auf Paranoia) in unabhängigen Umfragen beständig reproduziert wurden. Die Assoziationen dürften real sein.
Die empirische Forschung der letzten Jahrzehnte hat gezeigt, dass Agreeableness ein zentraler und stabiler Teil der Persönlichkeit ist. Es handelt sich bei Agreeableness um einen Komplex verschiedener Merkmale, die allesamt eine hohe Korrelation miteinander aufweisen und bei einer Faktorenanalyse auf einen gemeinsamen Faktor fallen. Oder anders ausgedrückt: Diesselbe latente Variable messen. Im Deutschen verwendet man oft den Begriff Sozialverträglichkeit, aber auch die Begriffe Herzlichkeit oder soziale Wärme dürften den Komplex recht treffend umschreiben. Zu dem Komplex gehören Merkmale wie Empathie, Hilfsbereitschaft, Rücksicht, Kooperation. Einmal nach dem Jugendalter ausgeprägt, bleiben diese Merkmale in der Regel über die Lebenszeit einer Person (oder zumindest über einige Jahrzehnte) erhalten. Die Merkmale sind sehr schwer zu verlernen. Oder zu erlernen, denn diese Stabilität gilt natürlich auch für die Ausprägung von Agreeableness in die andere Richtung, oft genannt Antagonismus. Das sind Menschen, die häufig sozial anecken: Mangelnde Empathie, Egoismus, Rücksichtslosigkeit, Wettbewerbsdenken.
Ich habe auf dem Harvard Dataverse einen Datensatz entdeckt, der demographische Aspekte, Erfahrungen der Kindheit und Big-Five-Persönlichkeitsprofile von n = 2457 Menschen enthält. Die Geschlechter sind ausgeglichen, mit 51 % Frauen und 49 % Männer (eine Option für Geschlechter dazwischen gab es leider nicht). Das mittlere Alter ist 39 Jahre mit einer Standardabweichung 13 Jahren, von einem minimalen Alter 14 bis maximalen Alter 78. Von den Teilnehmern sind 35 % Single.
Mich hat interessiert, ob es eine Assoziation zwischen Erfahrungen in der Kindheit und Antagonismus gibt. Kann man Faktoren finden, die mit einem erhöhten Risiko für die Entwicklung einer antagonistischen Persönlichkeit assoziiert sind? Generell sollte man bei einer Analyse immer die komplette Skala nutzen, da jede Umcodierung in Gruppen Informationsverluste bringt. Aber mit einer sauberen Codierung gestaltet sich die Präsentation und Interpretation deutlich angenehmer. Deshalb habe ich den Datensatz wie folgt umcodiert: Jeder Teilnehmer, der auf der Agreeableness-Skala einen Wert eine halbe Standardabweichung unter der Norm erzielt hat, wurde als antagonistisch klassifiziert und jeder andere als nicht-antagonistisch. Die anderen Skalen wurden an den Standardabweichungen -1, 0 und +1 geschnitten, gemäß einer Unterteilung sehr niedrig, niedrig, hoch, sehr hoch.
Eine deutliche Assoziation findet man mit der Beziehung mit den Eltern im Kindesalter. Menschen, die als Kind eine schlechte Beziehung mit der Mutter hatten, zeigen ein 59 % höheres Risiko für Antagonismus. So kommt man zu diesem Wert: Unter jenen, die eine sehr schlechte Beziehung zur Mutter berichten, sind 43 % als antagonistisch klassifiziert. Unter jenen, mit sehr guter Beziehung, hingegen nur 27 %. Macht ein OR = 43/27 = 1,59 und somit ein 59 % erhöhtes Risiko. Die Risikoerhöhung wird hier also immer im Vergleich zu der Gruppe am anderen Ende der Skala ausgedrückt. Dieser Unterschied in den Antagonismus-Anteilen sowie alle folgenden Unterschiede lassen sich mit einer sehr hohen statistischen Signifikanz p < 0,001 feststellen. Auch bei Menschen, die im Kindesalter eine schlechte Beziehung mit dem Vater hatten, ist das Risiko für Antagonismus erhöht, hier sogar um 83 %.
Da der Datensatz sehr umfangreich ist, lässt sich auch die Kombination der Faktoren mit relativ geringer statistischer Streuung darstellen. Bei Menschen, die in der Kindheit mit beiden Elternteilen eine schlechte Beziehung hatten, sind 47 % als antagonistisch klassifiziert. Bei jenen, mit einer guten Beziehung zu beiden Elternteilen, nur 17 %. Macht eine Risikoerhöhung von 176 % oder etwas mehr als eine 2,5-fache Erhöhung.
Die Frage zur kausalen Verbindung bleibt, wie immer bei Umfragen, unbeantwortet. Werden Menschen antagonistisch, weil sie im Kindesalter eine schlechte Beziehung mit den Eltern hatten? Oder hatten sie eine schlechtere Beziehung zu den Eltern, weil sie schon als Kinder sehr antagonistisch und somit schwierig im Umgang waren? Da Antagonismus, wie jeder andere Big-Five-Komplex auch, eine deutliche genetische Komponente hat, ist die zweite Frage gar nicht so abwegig wie sie zuerst scheint. Oder hat die Beziehung zu den Eltern im Kindesalter und späterer Antagonismus gar keine kausale Verbindung, sondern ist nur zufällig verbunden über dritte Variablen? Auch das ist gut möglich.
Die Beziehung zwischen den Eltern scheint für späteren Antagonismus auch relevant zu sein. Bei Teilnehmern, die als Kind die Eltern oft in Feindschaft oder gar Streit erlebt haben, ist das Risiko für Antagonismus 50 % erhöht.
Und hohe Werte auf Skalen, die Vernachlässigung durch die Eltern messen, sind ebenso mit höherem Antagonismus assoziiert. Vernachlässigung durch die Eltern ist mit einem 56 % höheren Risiko assoziiert.
Die Striktheit der Erziehung scheint hingegen keinen Einfluss zu haben. Unter denen, die von einer sehr strikten Erziehung berichten, finden sich innerhalb der statistischen Unsicherheit genauso viele antagonistische Teilnehmer wie unter jenen mit einer sehr liberalen Erziehung.
Mit dem Datensatz lässt sich auch eines der klassischen Ergebnisse der psychologischen Forschung reproduzieren, nämlich den Unterschied der Geschlechter entlang der Dimension Agreeableness-Antagonismus. Männer sind im Mittel antagonistischer, die Erhöhung des Risikos beträgt hier 50 %. Das gilt explizit auch nach Bereinigung nach Erfahrungen der Kindheit. Es ist ein waschechter Geschlechtereffekt (das ist eine Seltenheit) und nicht etwa ein Effekt, der sich durch eine unterschiedliche Behandlung in der Kindheit ergibt.
Ein anderer Effekt, der sich mit dem Datensatz reproduzieren lässt (siehe Tabelle aus dieser Studie), ist der Zusammenhang zwischen Agreeableness und Neurotizismus*, auch genannt emotionale Labilität. Unter emotional labilen Menschen ist der Anteil antagonistischer Menschen größer. Im Datensatz findet sich eine 48 % Erhöhung des Risikos für Antagonismus.
Interessant an der Tabelle aus der Studie, hier als eine Anmerkung am Rande, ist der Unterschied bei Selbst- und Fremdwertung. Bei Fremdwertung ergibt sich ein stärkerer Zusammenhang (r = 0,54) zwischen Antagonismus und Labilität als bei Selbstwertung (r = 0,36). Von außen sieht emotionale Labilität antagonistischer aus als von innen. Die Wahrheit liegt wohl dazwischen. Von außen kann man das Verhalten einer Person relativ objektiv betrachten, hat aber kaum bis keinen Zugang zu den Gründen und Gedanken dahinter. Von innen kennt man die Gründe und Gedanken intim, aber hat oft einen verklärten Blick auf das eigene Verhalten und auf die Konsequenzen für andere.
Eine letzte Feststellung zum Thema Antagonismus: Bereinigt nach Alter und Geschlecht, und das ist bei dieser Variable nötig da sich die Alterskurven für das Single-Sein bei Männern und Frauen deutlich unterscheiden (Witweneffekt), bringt ein hoher Antagonismus ein erhöhtes Risiko für ein Dasein als Single. Sicherlich nicht überraschend, ein hoher Antagonismus dürfte die Gestaltung eines gemeinsamen Lebens wohl nicht vereinfachen.
Das ist mein Lieblingsresultat aus Umfragen. Es ist lustig und die wenigsten können sich hier rausnehmen, ich wohl inklusive. Man kann Leuten die einfache Frage stellen, wie sie sich im Bezug auf intellektuelle / kognitive Fähigkeiten beurteilen: Unter dem Durchschnitt, im Durchschnitt oder über dem Durchschnitt. In einer perfekten Welt, in der jeder eine objektive Einstufung vornehmen kann und auch vornimmt, sollte man eine Gleichverteilung der Antworten erwarten. Für jeden, der sich unter dem Durchschnitt sieht, gibt es einen, der sich darüber sieht. So funktioniert Durchschnitt. Richtig? Die Realität ist amüsant anders:
8 % sehen sich unter dem Durchschnitt und stolze 64 % darüber. Auf jeden, der seine intellektuellen Fertigkeiten unter dem Durschnitt sieht, kommen also r = 8 Leute, die sich darüber sehen. Wir sind alle überdurchschnittlich!
Es ist interessant, dieses Ergebnis weiter runterzubrechen. Welche Gruppen haben eine besonders hohe Überzeugung von intellektueller Überlegenheit? Allem voran: Es gibt einen Unterschied bei den Geschlechtern. Bei Frauen kommen r = 6 gefühlt Überdurchschnittliche auf eine Unterdurchschnittliche, bei den Männern sind es mehr als doppelt soviele, stolze r = 13 Überdurchschnittliche pro Unterdurchschnittlichem.
Spannend ist auch der Zusammenhang mit der Wertung des eigenen Aussehens. Bei Teilnehmern, die ihr Aussehen negativ werten, gibt es nur r = 2 Überdurchschnittliche pro Unterdurchschnittlichem. Immer noch eine solide Mehrheit, aber nicht mehr ganz so abstrus wie bei der Allgemeinheit. Hingegen ist die Lage bei Teilnehmern, die sich als sehr gut-aussehend beschreiben, umso absurder. Das Verhältnis ist r = unendlich. Fast alle sehen sich als intellektuell überlegen, nur eine handvoll im Durchschnitt und kein einziger unter dem Durchschnitt. Ein gutes Aussehen bringt wohl einen meisterhaften Intellekt.
Vor diesem Hintergrund ist die Assoziation mit Narzissmus wohl nicht mehr überraschend. Die Verhältnisse liegen gleich wie bei der Beurteilung des Aussehens. Bei jenen, die einen geringen Score auf der 5-Item Narzissmus-Skala erzielt haben, gibt es r = 2 Überdurchschnittliche pro Unterdurchschnittlichem. Bei jenen, mit sehr hoher Neigung zu Narzissmus, gilt wieder r = unendlich. Fast alle sehen sich als intellektuell überdurchschnittlich, eine handvoll im Durchschnitt und kein einziger darunter. Es gibt hier zwei Möglichkeit der Erklärung: Bildung oder Einbildung. In den Daten gibt es nichts, was einen Beweis erbringen kann. Aber ich habe eine Vermutung im Bauch.
Auch wenn diese Verzerrung der Realität bei Männern und Menschen mit Tendenz zu Narzissmus am stärksten ausgeprägt ist, sollte man nicht vergessen, dass diese Verzerrung bei jeder Gruppe besteht. Zu denken, man sei intellektuell über dem Durchschnitt, scheint der “Default Mode” zu sein und eine Einstufung darunter die Ausnahme. Ich habe keine Kompetenzen in Psychologie und will entsprechend auch gar nicht versuchen, das zu erklären. Aber es ist definitiv Futter für die Gedanken.
Das wichtigste Kriterium, welches ein Merkmal erfüllen muss, um mit gutem Gewissen als Merkmal der Persönlichkeit gelten zu können, ist Stabilität. Nur wenn ein Merkmal bei Menschen über Jahre oder besser Jahrzehnte praktisch unverändert bleibt, taugt es zur Beschreibung der Persönlichkeit. Die empirische Forschung hat über die letzten Jahrzehnte diese stabilen Merkmale herausgearbeitet und gemäß der Interkorrelationen in fünf Komplexe gruppiert: Extroversion, Sozialverträglichkeit, Gewissenhaftigkeit, Offenheit und emotionale Stabilität. Bei jedem der Komplexe und seinen Merkmalen gilt in guter Näherung: Sie bilden sich früh aus und zeigen danach keine besonderen Veränderungen mehr. Wer heute empathisch ist, dieses Merkmal gehört zum Komplex Sozialverträglichkeit, wird es wohl auch in 20 Jahren sein. Und wer es heute nicht ist, der wird es auch in 20 Jahren nicht sein. Empathie ist nicht etwas, das man im Erwachsenenalter einfach lernen oder verlernen kann. Sie ist ein stabiler Teil der Persönlichkeit.
Man beachte aber die Formulierung: “In guter Näherung”. Keine Stabilität ist perfekt. Auch bei Erwachsenen bleibt noch etwas Spielraum bei der Formbarkeit. Wie groß dieser Spielraum ist, lässt sich relativ leicht ermitteln: Man testet eine Stichprobe an Leuten, testet die gleichen Leute X Jahre später und vergleicht dann. Eine Studie, die genau das tut, ist diese. Die abgebildete Tabelle zeigt die Korrelation zwischen den Big-Five-Merkmalen nach einem Zeitraum von neun Jahren. Zum Beispiel ergibt sich zwischen dem Neurotizismus-Wert im Alter von 33 Jahren und dem im Alter von 42 Jahren ein Korrelationkoeffizient von 0,76. Wie kann man diesen Wert interpretieren?
Um den Wert etwas greifbarer zu machen, habe ich in SPSS ein kleines Experiment gemacht. Angefangen mit einer Variablen, die eine Fantasieverteilung von einhundert Neurotizismus-Werten besitzt, habe ich diese Variable mehrfach kopiert und bei jeder Kopie einen gewissen Teil der einhundert “Leuten” mit zufälligen Schwankungen von plus/minus einer Standardabweichung versehen. Logischerweise gilt: Je mehr “Leuten” man eine solche zufällige Schwankung zusetzt, desto kleiner wird der Korrelationskoeffizient r. Ganz ohne zufällige Zusätze ist die neue Variable nur eine identische Kopie der alten Variable und man bekommt r = 1 (perfekte Korrelation). Mischt man 48 der 100 “Leuten” eine solche Schwankung hinzu, sinkt r auf 0,76. Den Korrelationskoeffizienten r = 0,76 kann man also auch so verstehen, dass man eine Bewegung (ob nun hoch oder runter) von im Mittel 0,48 Standardabweichungen pro Person von einer Variablen zur anderen Variablen hat.
Das ist ein schicker Weg die Korrelationen der Studien greifbarer zu machen. Bei Sozialverträglichkeit und Gewissenhaftigkeit bekommt man einen Korrelationskoeffizienten um 0,65. Über einen 9-Jahres-Zeitraum bewegen sich Leute somit im Mittel um grob 0,9 Standardabweichungen in die eine oder andere Richtung über die Skala. Das ist nicht zu vernachlässigen. Eine Personen, die ziemlich unordentlich und unzuverlässig ist, etwa eine Standardabweichung unter der Norm, kann durchaus nach einem solchen Zeitraum in der Norm landen. Eine Standardabweichung über der Norm wird wohl nicht drin sein, dafür müsste man weitere neun Jahre anhängen, aber die Entwicklung zur Norm wäre drin.
Als noch beständiger zeigt sich emotionale Stabilität. Hier ist, wie erwähnt, die Größe der typischen Auf- oder Abbewegung etwa 0,5 Standardabweichungen pro Person über neun Jahre. Recht instabile Menschen eine Standardabweichung unter der Norm könnten somit über einen Zeitraum von 18 Jahre durchaus zur Norm kommen. Bei extremer Instabilität eher 25 bis 35 Jahre. Das ist schon zäher und von sehr instabil zu sehr stabil wird über eine Lebenszeit wohl fast niemand kommen, aber ein Spielraum ist gegeben.
Noch zäher sind die Merkmale Extroversion und Offenheit. Hier findet die Studie einen Korrelationskoeffizienten von 0,8 und die typische Bewegung über neun Jahre liegt somit 0,35 Standardabweichungen. Für den Weg von einer Standardabweichung unter der Norm bis zur Norm muss man schon 27 Jahre rechnen. Von extremer Ausprägung zur Norm wird eine Lebensdauer nicht mehr reichen.
Man sollte sehr genau über diese Ergebnisse nachdenken. Die Stabilität der Big-Five-Merkmale ist ohne Zweifel eines wichtigsten (und auch am besten gesicherten) Resultate der psychologischen Forschung der letzten Jahrzehnte. Es zeigt die enorme Prägung der Genetik und frühen Lebenserfahrungen auf das Erwachsenenleben. Wie man ist, ist zu einem sehr großen Teil durch Dinge bestimmt, die nichts mit den eigenen Entscheidungen und eigenem Einsatz zu tun haben.
Menschen führen sehr gerne ihre Erfolge auf ihre Entscheidungen und ihren Einsatz zurück. Das liegt nahe und verleiht positive Gefühle. Ich weiß viel, weil ich viel gelernt habe. Ich bin kein Junkie auf der Straße, weil ich es besser gemacht habe. Diese Perspektive, wenn auch nicht grundfalsch, lässt die empirischen Realitäten zu kurz kommen. Es fehlt hier ein zentraler Zusatz. Ich weiß viel, weil ich viel gelernt habe. Und ich habe viel gelernt, weil ich eine hierfür eine förderliche Genetik und Kindheit besitze. Ich musste nie den jahrzehntelangen Kampf mit Mühen und Ängsten führen, mit denen sich jene konfrontiert sehen, die eine gegensätzliche Prägung besitzen. Die diesen Kampf wegen der hohen Stabilität dieser Merkmale auch nicht so einfach gewinnen können. Es ist ein ständiger “Uphill Battle”, gegen die eigene Natur. Ich bin kein Junkie auf der Straße, weil ich es besser gemacht habe. Ich habe es besser gemacht, weil ich dank meiner Genetik und Kindheit nie in einen akuten Zustand emotionaler Instabilität geraten bin, in denen Drogen oder Selbstmord die einzigen Auswege waren. Psychiatrische Kliniken kenne ich nur von außen. Ich hatte das Glück, diesen jahrzehntelangen Kampf nicht führen zu müssen.
Ich denke Bescheidenheit ist der beste Begriff, um eine rationale Reaktion auf die Resultate zu den Big Five beschreiben. Es ist ein großes Glück in das Erwachsenenleben mit hoher Empathie, hoher Verlässlichkeit, hoher Offenheit oder hoher emotionaler Stabilität zu starten. Ein Grund für Dankbarkeit, nicht Stolz. Und ein jahrzehntelanger Kampf, das Leben nach der Schule mit niedriger Empathie, niedriger Verlässlichkeit, niedriger Offenheit oder niedriger emotionale Stabilität zu beginnen. Fortschritte messen sich hier in Jahrzehnten, nicht in Jahren oder Monaten. Ein guter Grund für Rücksichtnahme auf jene, die diesen Kampf führen müssen, und ein solides Argument gegen Überheblichkeit.
Eine weitere Schlussfolgerung daraus ist, dass Versuche, einen Menschen zu ändern, zum Scheitern verurteilt sind. Und Beteuerungen der Menschen, von nun an anders zu sein, wenig Glauben geschenkt werden sollten. Die Stabilität der Big Five Merkmale untersagt solch schnelle Änderungen. Zehn Jahre Einsatz sollte man bei jedem dieser Merkmale als Minimum nehmen, eine deutliche Änderung hervorzubringen. Es bleibt nur einen Menschen entweder so zu akzeptieren, wie er ist, Schattenseiten inklusive, oder, wenn man mit diesen Schattenseiten nicht umgehen kann oder will, konsequent Distanz zu suchen.
Die Stabilität der Big Five Merkmale erklärt auch zum Teil die Stabilität von Partnerschaften und Freundschaften. Es gibt eine sehr hohe Korrelation zwischen der Ausprägung eines Big Five Merkmals und dem Mögen von Leuten mit ähnlich ausgeprägtem Big Five Merkmal. So besteht etwa zwischen Extroversion und dem Mögen extrovertierter Leute eine Korrelation r = 0,53. Zwischen Offenheit und dem Mögen offener Leute r = 0,48. Menschen mögen ähnliche Menschen, wohl weil man dann ähnliche Lebenserfahrungen macht, ähnliche Dinge unternimmt und sich über ähnliche Dinge Gedanken macht. Die Stabilität der Big Five impliziert konstante Ähnlichkeit, was wiederum stabile Partnerschaft und Freundschaften begünstigt. Zwei Menschen, die sich über ihre hohe Offenheit verbunden haben, können das auch beim Wiedertreffen 10 Jahre später machen.
Die Faktoren, die das Einkommen am stärksten beeinflussen, und das mit großem Abstand, sind das Alter und die formale Bildung. Das ist klar und bedarf wohl keiner weiteren Erklärung. Interessant ist vor allem der Blick darüber hinaus. Einmal bereinigt nach Alter und Bildung, bleiben dann noch weitere Faktoren, die einen signifikanten Einfluss auf das Einkommen zeigen? Die Antwort lautet Ja. Die folgenden Ergebnisse kommen aus einer ziemlich umfangreichen Umfrage mit n = 1887 Teilnehmern, den Datensatz habe ich vom Harvard Dataverse bezogen. Im ersten Schritt habe ich das Einkommen (jeweils mittels eines kubischen Polynoms) nach Alter und Bildung bereinigt. Die Variable, die sich daraus ergeben hat, habe ich dann als Zielvariable für die weitere Regression genommen. Als unabhängige Variablen haben eine große Bandbreite an abgefragten Aspekten aus Demographie, Kindheit, Lebensführung und Big-Five-Persönlichkeit gedient.
Nach Bereinigung können die folgenden Faktoren noch zusätzliche Varianz erklären:
Die Dimension “Extroversion”
Die Dimension “Gewissenhaftigkeit”
Der Wohlstand der Eltern
Die Dimension “Offenheit”
Umgebung im Kindesalter (urban versus ländlich)
Menschen, die in der Dimension Introversion-Extroversion klar im Bereich Extroversion liegen, berichten im Mittel ein höheres Einkommen als es auf Basis ihres Alters und ihrer formalen Bildung zu erwarten wäre. Bei Introversion ist es umgekehrt, diese ist mit einem Einkommen unter dem Erwartungswert assoziiert. Die statistische Signifikanz ist mit p < 0,001 sehr hoch, die Effektstärke beträgt etwa 0,5 Standardabweichungen. Es scheint aber auch ein Sättigungseffekt erkennbar zu sein. Zusätzliche Extroversion bringt nur bis Extroversion etwas über dem Durchschnitt ein Mehr an Einkommen. Extroversion darüber hinaus übersetzt sich nicht in höheres Einkommen. Bei der Erklärung des Effekts lohnt es sich wohl sich in den Sinn zu rufen, dass zentrale Komponenten von Extroversion soziale Dominanz und ein selbstbewusstes Auftreten in sozialen Situationen sind. Es ist leicht einzusehen, dass diese Qualitäten bei Beförderungen in höhere Positionen förderlich sein können. Ich will aber keine Küchenpsychologie machen. Sicher ist nur die hohe Signifikanz des Effekts, der Erklärungsansatz ist bloße Spekulation.
Dass Gewissenhaftigkeit, mit den zentralen Komponenten Verlässlichkeit und Ordentlichkeit, mit einem Einkommen über dem Erwartungswert assoziiert ist, dürfte wohl keine große Überraschung sein. Die Wirtschaft lebt davon, dass Leute zum vereinbarten Zeitpunkt am richtigen Ort sind und die vorliegenden Aufgaben gewissenhaft erledigen. Von Angestellten, die Gewissenhaftigkeit im Blut haben, träumt wohl jeder Arbeitgeber. Und schaudern eher vor Leuten wie mir, die sich oft nicht sicher sind, ob jetzt gerade Oktober ist. Die Signifikanz des Trends ist auch hier p < 0,001 und die Effektstärke etwa 0,4 SD.
Ein wohlhabendes Elternhaus zeigt auch bereinigt nach Alter und Bildungsgrad noch einen Effekt auf das Einkommen. Das könnte zum Beispiel ein Ausdruck von Vitamin B sein. Es schadet sicherlich nicht, wenn der Vater mit dem CEO entspannte Segeltrips unternommen hat. Auch zusätzliche Förderung, etwa durch private Lehrer, könnte Teil dieses Effekts sein. Der formale Bildungsgrad ist zwar berücksichtigt, jedoch nicht die Note, mit welcher diese erreicht wurde. Aus eigener, langer Erfahrung als Nachhilfelehrer kann ich bestätigen, dass eine 4 oft noch zur 2 gewandelt werden kann, natürlich inklusive einem Mehr an Verständnis der Materie, sofern die Eltern das notwendige Geld haben. Wie dem auch sei, die Signifikanz des Trends ist mit p < 0,001 sehr hoch und die Effektstärke ebenfalls grob 0,4 SD.
Für die Existenz des folgenden Effekts würde ich meine Hand nicht ins Feuer legen. Die Signifikanz des Trends ist mit p < 0,01 zwar ganz gut, aber die Signifikanz der Unterschiede der Gruppen ist p > 0,05. Ein grenzwertiger Fall. Es könnte sein, dass eine hohe Offenheit, die oft mit einer kritischeren Hinterfragung der Dinge und weniger blinder Konformität einhergeht, sich negativ auf das Einkommen auswirkt, mit einer Effektstärke um die 0,2 SD.
Ähnlich grenzwertig, mit einer Signifikanz des Trends p < 0,05 und keiner Signifikanz der Unterschiede, ist die Umgebung im Kindesalter. Menschen, die in städtischer Umgebung aufgewachsen sind, scheinen mit dem Einkommen etwas über ihrem Erwartungswert aus Alter und Bildung zu liegen und Menschen aus ländlicher Umgebung etwas darunter. Auch hier ist die Effektstärke circa 0,2 SD.
Die obigen Unterschiede lassen sich auch grob in Dollar-Werten ausdrücken. Die Standardabweichung beim Einkommen im Sample beträgt 1,3 Kategorien und die Differenz von einer zur nächsten Kategorie ist $ 25.000 pro Jahr. Ein Unterschied von einer Standardabweichung im Einkommen übersetzt sich somit etwa in einen Unterschied von knapp $ 20.000 pro Jahr oder $ 1600 pro Monat. Zwischen hoher und niedriger Extroversion liegen somit bereinigt nach Alter und Bildung $ 800 im Monat, zwischen den Skalenrändern von Gewissenhaftigkeit und Wohlstand der Eltern $ 650. Ein knackiger Unterschied.
Am Ende der Hinweis, dass der Einfluss von Persönlichkeit auf das Einkommen generell größer ist als hier festgestellt, da die Persönlichkeit auch zu einem guten Teil den Bildungsgrad beeinflusst. So ist etwa hohe Gewissenhaftigkeit und niedriger Neurotizismus recht eng mit einem höheren formalen Bildungsgrad assoziiert. Das oben festgestellte Plus hoher Gewissenhaftigkeit ist also ein Plus auf das Plus, das schon durch die förderliche Wirkung auf den Bildungsgrad besteht. Das gleiche gilt, wie erwähnt, auch für den Wohlstand der Eltern. Kinder wohlhabender Eltern erreichen im Mittel einen höheren Bildungsgrad, aber selbst danach bereinigt bleibt ein Plus für das spätere Einkommen.
Ich habe vor kurzem neun Umfragen aus dem Harvard Dataverse abgegrast, insgesamt n = 1989 Teilnehmer, um jene Denk- und Verhaltensmuster zu finden, die am konsequentesten mit emotionaler Instabilität (Neurotizismus) assoziiert sind. Es ist erstaunlich, wie bei den Umfragen unabhängig voneinander immer diesselben üblichen Verdächtigen zum Vorschein kommen und wie eng die jeweiligen Assoziationen sind. Die Unterschiede lassen sich auch sehr schlüssig in vier Kategorien unterteilen. Die Stärke der Assoziationen ist stets mit dem standardisierten Regressionskoeffizienten ß angegeben (Regression mit Neurotizismus als Zielvariable) und die Signifikanz mit * für p < 0,05, ** für p < 0,01 und *** für p < 0,001.
Innenfokus
Der Blick emotional instabiler Menschen ist klar nach innen gerichtet, der Blick emotional stabiler Menschen nach außen. Das lässt sich an verschiedenen Skalen erkennen. Eine der Umfragen hat den Innenfokus direkt mittels einer Skala abgefragt, mit dem Ergebnis ß = 0,31***. Tagträumerei, ein guter Indikator für den Innenfokus, war sogar über drei Umfragen eng mit Neurotizismus assoziiert: ß = 0,48***, ß = 0,41*** und ß = 0,26***. Man erkennt den starken Innenfokus auch an der negativen Korrelation mit Mindfulness-Skalen. Hier ergeben sich in zwei Umfragen die Koeffizienten ß = -0,15* und ß = -0,58***.
Übermäßige Selbstkritik
Emotional instabile Menschen sind extrem selbstkritisch, emotional stabile Menschen kaum selbstkritisch. Über drei Umfragen ist Selbstkritik sehr klar mit Neurotizismus assoziiert: ß = 0,47***, ß = 0,42*** und ß = 0,55***. Man sieht es auch am Above-Average-Effekt. Emotional instabile Menschen sehen sich, egal ob man nach sozialen Skills, Fahrskills oder Leseverständnis frägt, konsequent unter dem Durchschnitt, emotional stabile Menschen sehen sich konsequent über dem Durschnitt. Die Stärke der Assoziation des Above-Average-Bias mit Neurotizismus ist ß = -0,35***.
Problemvermeidung
Über drei Umfragen hinweg ergibt sich auch eine sehr enge Assoziation zwischen Problemvermeidung und emotionaler Instabilität: ß = 0,47***, ß = 0,55*** und ß = 0,45***. Die Gewohnheit der Problemvermeidung scheint eine zentrale Komponente emotionaler Instabilität zu sein. Dieser Punkt ist wohl ein fließender Übergang zur letzten Todsünde.
Lebensführung
Emotional instabile Menschen bewegen sich nicht ausreichend, essen schlecht und pflegen wenig Routinen. Die Assoziation von Neurotizismus und Bewegung bzw. sportlicher Aktivität ist über sechs Umfragen konsequent zu erkennen: ß = -0,29***, ß = -0,13*, ß = -0,19**, ß = -0,20**, ß = -0,34*** und ß = -0,18***. Die Assoziation mit schlechten Gewohnheiten bei Ernährung über drei Umfragen zu sehen: ß = -0,41***, ß = -0,25*** und ß = -0,16**. Und die Assoziation von Neurotizismus mit mangelnder Routine über drei Umfragen (in einer Umfrage jedoch nicht): ß = -0,12*, ß = -0,41***, ß = 0,02 und ß = -0,36***. Hand in Hand mit diesem Punkt geht wohl auch die negative Assoziation mit aufgeräumten Zimmern: ß = -0,35***.
Wie man aus diese Assoziationen interpretiert und was man daraus macht, sei jedem selbst überlassen. Klar ist nur wie eng und konsequent die jeweiligen Assoziationen sind. Ich benutze den Begriff Assoziationen hier bewusst weil keine Ursache-Wirkung impliziert sein soll. Nur kontrollierte Experimente können Ursache-Wirkung identifizieren. Das ist vor allem wichtig im Hinblick auf Versuche der Umkehrung der Assoziationen. Nur weil Neurotizismus mit Tagträumerei assoziiert ist, heißt das nicht, dass ein nun antrainierter Verzicht auf Tagträumerei eine Besserung bringen muss. Es kann sein, aber es muss nicht. Die Ursache für die Assoziation könnte ganz woanders liegen und die Tagträumerei nur ein Indikator für diese verborgene Ursache. Daher sollte man im Hinblick auf Ursache-Wirkung nur kontrollierten Experimenten trauen. Bei sportlicher Aktivität existieren diese zum Beispiel. Die Umkehrung funktioniert tatsächlich, mehr Bewegung über einige Monate hinweg bringt geringere Scores bei Neurotizismus.
Die Ergebnisse lassen auch vermuten, dass rein behaviorale Ansätze wohl zum Scheitern verurteilt sind. Mehr Bewegung, besser essen und mehr Routinen ist ohne Inklusion der genannten Denkmuster wie ein Pflaster auf eine ausufernde Infektion. Kein vernünftiger Mensch möchte auf das Pflaster verzichten, es kann in den akutesten Zeiten deutliche Linderung bringen, aber damit ist die Grenze des Machbaren bei rein behavioralen Ansätzen auch leider schon erreicht.
Für mich war auch interessant zu sehen, dass die kognitive Verzerrung nicht immer bei den emotional instabilen Menschen liegen muss. Die wenigsten Menschen sind bei einer großen Bandbreiten an zentralen Fähigkeiten konsequent über dem Durchschnitt. Sich konsequent über dem Durchschnitt zu sehen ist eine Verzerrung der Realität. Aber eine, die scheinbar den Leidensdruck sehr effektiv lindern kann. Strenger Realismus kann ernüchternd und schmerzhaft sein. Der Königsweg wäre wohl, seinen Wert und seine Perspektive generell von diesem Vergleich mit den Fähigkeiten anderer Menschen zu entkoppeln.
Es gibt viele Artikel und Studien, die sich mit Vorurteilen gegen Menschen anderer Ethnien, anderer sexueller Orientierung, anderen Geschlechts und anderen Alters beschäftigen. Vorurteile gegen reiche Menschen werden, obwohl diese recht weit verbreitet sind, eher selten untersucht, was wohl auch daran liegt, dass man reiche Menschen kaum zu den vulnerablen Gruppen zählen kann. Mithilfe einer Umfrage auf dem Subreddit r/SampleSize, auf die n = 271 geantwortet haben, wollte ich trotzdem mal schauen, wie weit solche Vorurteile verbreitet sind und wer diese tendenziell glaubt.
Da es keine validierte Skala gibt, habe ich einfach vier gängige Vorurteile über reiche Menschen abgefragt und das Ergebnis zu einer Skala zusammen gefasst. Die Teilnehmer konnten mittels einer 4-Punkte Likert-Skala ihre Zustimmung zu den folgenden vier Aussagen mitteilen: “Reiche Menschen interessieren sich nicht für das Wohl anderer”, “Reiche Menschen sind korrupt”, “Reiche Menschen nutzen andere aus” und “Reiche Menschen sind gierig”. Die Korrelation unter den vier Variablen ist hoch genug um die Zusammenfassung zu einer gemeinsamen Skala zu rechtfertigen. Das erkennt man auch Kronbach’s Alpha, einem Ausdruck der mittleren Korrelation der Variablen untereinander, oft verwendet als Gütemaß für Skalen. Der Wert Alpha = 0,88 ist ausreichend und zufriedenstellend.
Zur einfacheren Präsentation habe ich die Skalenwerte umcodiert, so dass jedem, der einen Score von einer Standardabweichung oder mehr über der Norm erzielt hat, der Wert Eins zugeordnet wurde, und allen anderen der Wert Null. So lassen sich die Ergebnisse als Prozente ausdrücken (“Anteil Reichphobe”). Ich werde diesen Begriff weiterverwenden, auch wenn er ziemlich sperrig und seltsam klingt. Als Reichphober zählt also jeder Teilnehmer, der einen besonders hohen Score auf der obigen Skala erreicht hat, mit dem etwas willkürlichen (aber vernünftigen) Cut-Off bei einer Standardabweichung über der Norm.
Am naheliegendsten ist zu schauen, wie sich Vorurteile gegen reiche Menschen in Gruppen unterschiedlicher finanzieller Situation verhalten. Die Ergebnisse sind wenig überraschend. Bei jenen mit Einkommen ein gutes Stück unter dem Median findet man 16 % Reichphobe, bei einem Einkommen weit über dem Median nur 6 %. Der Unterschied ist aber nur sehr knapp signifikant mit p < 0,05.
Der Unterschied ist größer wenn man statt des Einkommens das Ersparte anschaut. Unter Teilnehmern, die angeben nur sehr wenig Erspartes zu besitzen, kann man 21 % zu den Reichphoben zählen. Bei jenen, mit viel Erspartem, nur 7 %. Die Signifikanz des Unterschieds ist p < 0,01. Das kann man schon als handfestes Resultat werten. Aber der Unterschied wird noch deutlicher beim Blick auf Schuldenprobleme.
27 % jener, die angeben große Schuldenprobleme zu haben, zeigen starke Vorurteile gegen reiche Menschen. Unter jenen, ohne solche Probleme, sind es hingegen nur 8 %. Die Signifikanz ist mit p < 0,001 sehr hoch. Dass sich ein solcher Unterschied aus reinem Zufall ergibt, ist extrem unwahrscheinlich. Was Indikatoren der finanziellen Situation angeht, scheinen Schulden also die stärkste treibende Kraft für Vorurteile gegen reiche Menschen zu sein. Es ist gut möglich, dass die Schuldenprobleme hier sogar die einzige treibende Kraft sind und die Ergebnisse zu Einkommen und Erspartem nur korrelativ sind. Eine lineare Regression legt das zumindest nahe.
Möchte man den erzielten Wert auf der Skala mittels linearer Regression auf Basis der Variablen Einkommen, Erspartem und Schuldenprobleme (und nur dieser drei Variablen) vorhersagen, so zeigt sich, dass die alleinige Verwendung der Variablen Schuldenprobleme praktisch alle damit erklärbare Varianz abdeckt. Die Hinzunahme von Einkommen und Erspartem führt zu keiner Verbesserung der Vorhersage.
Der Anteil Reichphober scheint auch altersabhängig zu sein. Vorurteile gegen reiche Menschen sind in jungen Jahren (< 30 Jahre) mit 7 % Prävalenz relativ selten. Im mittleren Alter steigt der Anteil aber stark an, auf ein Maximum von 22 % in den Alter um 45 Jahre herum. Die Differenz der Anteile bei jungem Alter versus mittlerem Alter ist signifikant mit p < 0,05. Im hohen Alter scheinen Vorurteile gegen reiche Menschen wieder seltener zu werden, aber das festgestellt ohne statistische Signifikanz.
Was die Persönlichkeit gemessen an dem Big-Five-Modell betrifft, zeigt nur die Dimension Extroversion einen signifikanten Unterschied. 26 % der introvertierten Teilnehmer haben deutliche Vorurteile gegen reiche Menschen, jedoch nur 9 % der extrovertierten Teilnehmer. Es ist p < 0,01, auch hier ist also ein Unterschied basierend auf reinem Zufall sehr unwahrscheinlich.
Nullresultate sind aber manchmal auch ganz interessant. In der Regel zeigen Menschen, die einen hohen Score bei der Big-Five-Dimension Agreeableness (Herzlichkeit, Empathie, Kooperation) erzielen, weniger Vorurteile gegen andere Menschen. Bei Vorurteilen gegen reiche Menschen findet man einen solchen Unterschied aber nicht. Der Anteil jener, die starke Vorurteile zeigen, ist bei Leuten mit geringer Agreeableness genauso hoch wie bei Leuten mit hoher Agreeableness. Das ist ein unerwartetes und ziemlich kurioses Resultat.
Aspekte der Erziehung scheinen auch einen Einfluss auf Reichphobie zu haben. Menschen, die berichten von strikten Eltern erzogen worden zu sein, tendieren zu mehr Vorurteilen gegen Reiche. Die entsprechenden Anteile sind hier 25 % versus 9 % mit einer Signifikanz p < 0,01. Die Striktheit der Eltern wurde hier über eine nicht-validierte Skala mit vier Variablen gemessen (Cronbach’s Alpha = 0,85).
Menschen, die von Eltern erzogen wurden, welche psychische Probleme haben, haben eventuell auch ein höheres Risiko, im späteren Leben Vorurteile gegen reiche Menschen zu entwickeln. Der Unterschied ist aber mit 21 % versus 10 % und p < 0,05 nur knapp signifikant. Meine Hand ins Feuer legen würde ich für diesen Zusammenhang nicht, aber der Vollständigkeit halber sei er hier angemerkt.
Das Regressionsmodell fortgespinnt mit Alter und Persönlichkeit bestätigt die Signifikanz der Variable Schuldenprobleme in der Regression (und die Insignifikanz von Einkommen und Erspartem) und zeigt, dass die Hinzunahme von Alter und Extroversion die Vorhersage signifikant verbessert. Andere Dimensionen der Persönlichkeit bringen hingegen keinen Zugewinn.
Eine Hinzunahme der Variablen der Erziehung und schlussendlich Elimination aller Variablen, deren Vorhandensein im Modell keine zusätzliche Varianz erklärt, führt zu dem folgenden optimalen Regressionsmodell. Um Reichphobie mittels Aspekten finanzieller Situation, Demographie und Persönlichkeit vorherzusagen, kann man sich also auf die Verwendung von Schuldenproblemen, Alter, Extroversion und Striktheit der Erziehung beschränken. Was davon kausal ist und was nicht bzw. ob von diesen Variablen überhaupt eine kausal für Vorurteile gegen reiche Menschen ist, lässt sich aber nicht klären. Das geht generell nur mit RCTs, von denen es zu Reichphobie natürlich keine gibt.
Die Analyse konnte einige “Risikofaktoren von Reichphobie” ermitteln, aber mit dem Modell bleibt leider viel mehr offen als erklärt wird. Der adjusted R² beträgt mickrige 11 %. Das Modell erklärt somit nur grob 15 % der Varianz, die sich unter Berücksichtung von Messunsicherheiten maximal erklären ließe. Gefunden wurden leider nur Nebeneffekte. Die bestimmenden Faktoren bleiben im Dunkeln. Was unerwartet ist, da die Bandbreite der gemessenen Variablen ziemlich groß ist. Es ist sehr selten in den Kategorien Demographie, Persönlichkeit und Kindheit keinen einzigen Haupteffekt zu finden.
In einer Umfrage, die ich im Harvard Dataverse gefunden habe, wurde den n = 174 Teilnehmern neben den übliche Fragen zu Demographie und Persönlichkeit auch die Frage gestellt, ob sie regelmäßig mit ihnen nahestehenden Menschen über ihre eigenen Probleme und Erfahrungen reden. Mich hat interessiert, welche Menschen sich typischerweise anderen mitteilen und ob diese Gewohnheit einen positiven psychologischen Effekt zeigt.
Über den gesamten Datensatz geben 27 % an, sich nie oder praktisch nie anderen mitzuteilen, 36 % der Teilnehmer machen es zumindest manchmal und 37 % machen es regelmäßig. Die Wahrscheinlichkeit, dass ein Teilnehmer mit anderen über seine eigenen Probleme redet, hängt dabei von drei Variablen ab: Extroversion, Beziehungsstatus und Agreeableness.
Unter introvertierten Menschen teilen sich nur 18 % regelmäßig anderen mit, während dies bei extrovertierten Menschen 66 % sind (p < 0,001). Einen deutlichen Unterschied findet man auch bei Singles. Von diesen reden nur 23 % oft mit anderen über ihre Problemen, bei Leuten in einer Beziehung sind es hingegen 44 % (p < 0,01). Ebenso signifikant ist die Differenz bei Agreeableness, was in der Fachwelt in der Regel mit dem Begriff Sozialverträglichkeit übersetzt wird, ich aber stattdessen auch gerne das Wort Herzlichkeit verwende. Wie dem auch sei: Bei Menschen mit niedrigem Score auf der Agreeableness-Skala teilen sich 27 % regelmäßig anderen mit, bei hoher Agreeableness steigt dies auf 40 % (p < 0,05). Weitere statistisch signifikante Unterschiede gibt der Datensatz zu dieser Frage nicht her.
Noch interessanter als die Frage, wer sich oft anderen mitteilt, ist die Frage, ob es sich positiv auf das Leben auswirkt. Die Antwort ist: Ja. Sehr klar sieht man das zum Beispiel bei den vorliegenden Fragen zu dem, was ich jetzt salopp “emotionalen Nachhang” nenne. Von denen, die sich anderen nicht mitteilen, leiden 43 % unter ständiger Reue über verpasste Chancen. Dasselbe berichten nur 15 % jener, die sich oft mitteilen (p < 0,01). Ähnlich verhält es sich bei Schamgefühlen. Hier findet man die entsprechenden Anteile 38 % und 11 % (p < 0,001). Und geplagt von Schuldgefühlen sehen sich 36 % derjenigen, die Probleme und Erfahrungen für sich behalten. Aber nur 9 % derjenigen, die sich mitteilen (p < 0,001).
Vor diesem Hintergrund ist es nicht überraschend, dass Leute, die es sich zur Gewohnheit gemacht haben über ihre Probleme zu reden, ihre Vergangenheit generell positiver bewerten und auch generell zufriedener mit ihrem Leben sind. Bei jenen, die sich anderen nicht öffnen, bewerten nur 17 % ihre Vergangenheit als positiv gegenüber 57 % im anderen Lager (p < 0,001). Bei der allgemeinen Zufriedenheit mit dem Leben erhält man die Anteile 32 % versus 69 % (p < 0,001).
Knapp signifikant mit p < 0,05 sind auch die Unterschiede bei den Scores auf den Skalen für Optimismus und Mindfulness. Optimisten, gemessen an einem z-Score > 0 auf der entsprechenden Skala, sind etwas seltener zu finden in der Gruppe der wenig mitteilungsbereiten Menschen (45 % versus 68 %). Dasselbe gilt für den Anteil der Teilnehmer mit einem z-Score > 0 auf der Mindfulness-Skala (34 % versus 57 %).
Ich vermute all diese Resultate werden niemanden aus den Socken hauen, gilt es doch als Allgemeinwissen. Aber es ist immer schön, wenn sich Erfahrungssätze mit harten Daten stützen lassen. Nicht selten versagen gängige Weisheiten, die viele als Selbstverständlich betrachtet, den empirischen Härtetest. Es ist auch interessant mal vor sich zu sehen, wie groß der Unterschied wirklich sein kann. Nur über das Wieso können diese Zahlen leider keine Auskunft geben und ich habe auch nicht die Kompetenz, dazu mehr sagen zu können.
Eine Anmerkung will ich aber noch anbringen: Geschlechter-Unterschiede im Mitteilen hat der Datensatz keine offenbart. Männer teilen sich, entgegen der Vorstellung vieler, genauso häufig anderen mit wie Frauen. Sie tun aber es aber wohl heimlicher und mit mehr Vorsicht, da es in manchen Kreisen immer noch als unmännlich gilt, über seine Erfahrungen und Probleme zu sprechen. Von solchen unhaltbaren Vorstellungen sollte man(n) sich aber nicht beirren lassen, denn die psychologischen Vorzüge des Mitteilens sind recht klar.
Ein Datensatz, den ich auf dem Harvard Dataverse gefunden haben, zeigt sehr schön, wie sich die Persönlichkeit auf die politische Positionierung einer Person auswirkt. Das Ergebnis bestätigt im Großen und Ganzen das, was andere Publikationen zu diesem Thema typischerweise finden. Die n = 214 Teilnehmer konnten neben der üblichen Barrage an Fragen zu Demographie und Big Five auch ihre Einstellung zu vier zentralen Themen der amerikanischen Politik kundtun: Abtreibung, Klimawandel, LGBT und Abschiebung illegaler Einwanderer.
Es zeigt sich eine sehr enge Korrelation der Antworten auf diese vier Fragen, wie man an der untenstehenden Tabelle erkennen kann. Wer etwa möchte, dass Abtreibungen zur illegalen Tat erklärt werden, der möchte auch mit hoher Wahrscheinlichkeit auf Maßnahmen gegen den Klimawandel und Ausweitung der LGBT-Rechte verzichten sowie illegale Einwanderer konsequent abschieben. Die engen Korrelationen rechtfertigen die Zusammenfassung der vier Fragen zu einer Skala, welche die Lage eines Teilnehmers entlang der Dimension Links-Rechts erfassen soll.
Wenig überraschend zeigt das Alter einen klaren Einfluss auf die politische Position. Bei der Gruppe junger Leute 20-29 sind linke Einstellungen gehäuft zu finden, nach dem Alter 40 findet man beim Vergleich verschiedener Altersgruppen jedoch keine signifikanten Unterschiede mehr. Um zu vermeiden, dass bei der weiteren Analyse Effekte gefunden werden, die sich indirekt über das Alter erklären (und nicht etwa über jene Variable, auf welcher dann der Fokus liegt), habe ich die Skala mittels der Funktion aus dem Graphen bereinigt.
Eine Regression mit den fünf Dimensionen der Persönlichkeit gemäß dem Big-Five Modell, seit einigen Jahrzehnten das Standardmodell der Persönlichkeit in der Psychologie, zeigt zwei signifikante Prädiktoren für rechte Einstellungen: Agreeableness (Herzlichkeit) und Openness (Offenheit). Typischerweise gehen rechte Einstellungen mit geringeren Scores auf den Skalen für Herzlichkeit und Offenheit einher. Der Effekt ist mit standardisierten Koeffizienten ß = -0,21 und ß = -0,30 auch recht deutlich und die statistische Signifikanz mit p < 0,01 und p < 0,001 sehr hoch.
Jedoch erfasst die Persönlichkeit nur einen relativ geringen Teil der Varianz in der Skala für politische Einstellung. Der adjusted R² liegt bei 0,14, womit die Persönlichkeit etwa 20 % der Varianz erklärt. Die Persönlichkeit hat einen Einfluss, ist jedoch weit davon entfernt, alles-bestimmend zu sein. Es muss noch andere Faktoren geben, welche die politische Einstellung steuern.
Eine Regression mit Faktoren über die Persönlichkeit hinaus nennt einige dieser Faktoren. Ähnlich stark wie der Einfluss von Herzlichkeit ist der Einfluss von Wohnumgebung. Bei Menschen, die in einer urbanen Umgebung heimisch sind, sind rechte Einstellung seltener. Es ist hier also ein Stadt-Land-Gefälle bemerkbar. Zusätzliche Erklärungskraft bringt der Beziehungsstatus. Menschen in einer Beziehung sind im Mittel etwas rechter als Singles. Auch signifikant ist der Erziehungsstil der Eltern. Wer eine striktere Erziehung erfahren hat, entwickelt im späteren Leben mit einer erhöhten Wahrscheinlichkeit rechte Einstellungen. Wobei man hier schon an die Grenzen der Signifikanz gerät. Der Effekt ist mit ß = 0,15 nicht sonderlich stark.
Die Aufnahme dieser zusätzlichen Variablen erhöht den adjusted R² auf 0,22. Die fünf genannten Prädiktoren können somit etwa 30 % der Varianz erklären. Sofern man sich auf Faktoren beschränkt, die kausal für politische Einstellung sein könnten, lässt sich aus dem Datensatz auch keine weitere Erklärungskraft herausholen.
Es seit noch angemerkt, dass nicht in allen Fällen ein linearer Zusammenhang besteht. Während der Zusammenhang zwischen Offenheit und politischer Position in guter Näherung linear ist, sieht man bei Herzlichkeit eher eine Plateau-Form. Herzlichkeit scheint nur dann merklich auf die politische Position zu wirken, wenn diese in extremer Form ausgeprägt ist, also bei besonders geringer oder besonders hoher Empathie. Variationen bei Herzlichkeit im Normbereich zeigen keinen Einfluss.
Beim Erziehungsstil findet sich ein Zusammenhang in Form eines Sättigungseffekts. Es gibt im Mittel keinen Unterschied zwischen jenen Teilnehmern mit moderat-strenger und übermäßig-strenger Erziehung. Jedoch einen umso deutlicheren Unterschied beim Vergleich dieser beiden Gruppen mit jenen Teilnehmern, die in einem “Laissez Faire”-Haushalt aufgewachsen sind.
Den Zusammenhang mit Offenheit erkennt man, das noch am Rande, auch gut an den berichteten Interessen. Rechte Einstellungen schlagen durchweg bei allen Interessen, die typischerweise mit erhöhter Offenheit assoziiert sind, negativ an: Lesen als Hobby, Tanzen, Musizieren, Museumsbesuche sowie Yoga und Meditation. Der stärkste Effekt zeigt sich hier beim Lesen. Auch hier jedoch wieder die Anmerkung, dass es sich mehr um eine leichte Tendenz handelt als alles andere.
Ich habe vor kurzem die Subreddits r/opiates und r/heroin gezielt nach Strängen abgesucht, in welchen Heroinsüchtige über die Wege der Geldbeschaffung reden. Insgesamt habe ich relevante Beiträge von n = 152 Usern gefunden. Die Auswertung der Beiträge gibt einen interessanten Einblick in das Leben von Menschen, bei denen sich jeder Tag um die Beschaffung von Geld und Drogen dreht.
Ganz wichtig: Ich möchte hier keinen Anspruch auf Vollständigkeit oder Genauigkeit stellen. Um eine Verzerrung so gut es geht zu vermeiden, habe ich jeden Beitrag, der relevant ist, in die Analyse aufgenommen. Da die Sammlung der Daten aber über ein Online-Forum lief, muss man von einer bestehenden Verzerrung ausgehen. Die Stimmen der Heroinsüchtigen, die das Forum nicht nutzen oder keinen Zugang zum Internet haben, konnten nicht berücksichtigt werden. Die Berücksichtigung dieser könnte alle genannten Prozentzahlen deutlich verschieben, ob nun nach oben oder nach unten. Insofern sollte man die folgende Sammlung eher als einen groben Einblick sehen. Auf Wertungen will ich auch absehen.
Gewöhnliche Jobs
83 User (54 % / 1 von 2) bekommen ihr Geld über einen gewöhnlichen Job. Von diesen 83 Usern berichten 55/83 User (66 %) von einer Festanstellung in Teil- oder Vollzeit. Die Bandbreite der genannten Berufe ist sehr groß, es scheint keinen typischen Job zu geben. Erwähnt wurde die Anstellung im Einzelhandel, in der Gastronomie, im Büro und sogar die Tätigkeit als Anwalt. Die verbliebenen 28/83 User (34 %) gehen hingegen Gig-Jobs nach. Sie haben keine Festanstellung, schauen aber wöchentlich in die Kleinanzeigen um geeignete Arbeiten zu finden. Das sind kurzfristige Jobs wie etwa Fahrdienste, Hilfe bei Transport oder Gärtnerarbeit.
Diebstahl / Boosting
37 User (24 % / 1 von 4) geben an, durch Diebstahl an das notwendige Geld zu kommen. Mit Abstand am Beliebtesten ist dabei der Diebstahl im Einzelhandel, das machen 28/37 (76 %) dieser User. 4/37 (11 %) stehlen von Freunden und Familie. 3/37 (8 %) schlagen die Scheiben von Autos ein und entnehmen Wertgegenstände. Und weitere 2/37 (5 %) stehlen von ihrem Arbeitsplatz.
Sexuelle Dienstleistungen
24 User (16 % / 1 von 6) verdienen sich Geld mit sexuellen Dienstleistungen. Das gilt sowohl für männliche als auch weibliche Abhängige. 13/24 (54 %) dieser User bieten sich dabei für Geschlechtsverkehr an. Weibliche Abhängige in der Regel bei Männern aller Schichten, männliche Abhängige in der Regel bei Homosexuellen. 5/24 (21 %) bieten sexuelle Dienstleistungen vor der Webcam, 3/24 (13 %) verkaufen im Internet ihre Unterwäsche, 2/24 (8 %) machen reine Escort-Dienste und 1/24 (2 %) bieten Dienste als Domina.
Panhandling
13 User (9 % / 1 von 12) betreibt Panhandling. Das kann bedeuten, ganz klassisch an der Straßenseite zu betteln oder etwa Leute nach Erzählung einer erfundenen Geschichte um Geld zu bitten. So stellen sich einige z.B. vor eine Tankstelle und erzählen Passanten, dass ihr Auto kaputt gegangen ist und sie dringend Geld für ein Busticket benötigen. Oder sie Geld für Babynahrung benötigen.
Middle Man
12 User (8 % / 1 von 13) geben an, regelmäßig als Middle Man zu fungieren. Sie holen Drogen an einem bestimmten Ort ab und bringen diese zu einer Person an einem anderen Ort. Für das rechtliche Risiko, welches sie dabei eingehen, werden sie mit einem kleinen Betrag entlohnt. Viele der User, die dies betreiben, merken an, dass diese Methode neben gewöhnlicher Arbeit die angenehmste Methode ist, um schnell an Geld zu kommen. Nicht die lukrativste, aber die angenehmste.
Drogenhandel
10 User (7 % / 1 von 15) verkaufen selbst Drogen, um ihren Konsum zu finanzieren. Die meisten verkaufen dabei entweder Cannabis oder die Medikamente, welche ihnen vom Arzt verschrieben wurden. So verkauft etwa ein User, bei welchem ADS diagnostiziert und Ritalin verschrieben wurde, dieses Medikament an College-Studenten, um sich von dem Erlös Heroin zu kaufen.
Reselling / Flipping
8 User (5 % / 1 von 20) nutzen die legale Methode des Resellings. Wenn sie sehen, dass ein Produkt im Laden im Angebot ist und sich dieses Produkt zu einem höheren Preis online verkaufen lässt, erwerben sie das Produkt in großer Menge im Laden und verkaufen es mit Profit auf Amazon weiter.
Eigentum verkaufen
8 User (5 % / 1 von 20) geben an, persönliche Dinge zu verkaufen, sobald das Geld knapp wird. Dabei scheint nichts sicher zu sein: Kleidung, Möbel, die geliebte Gitarre, den Heim-PC und gar das Auto.
Blutspenden
4 User (3 % / 1 von 40) bezeichnen das Blutspenden als einen Hustle, den sie häufig betreiben. Für die Blutspende erhalten sie einen kleinen Betrag, mit welchem sie dann Drogen erwerben. Gemäß eines Users lassen sich damit überraschend hohe Summen erzielen, wenn man jede Gelegenheit nutzt.
Raubüberfälle
4 User (2 % / 1 von 40) geben an, über Raubüberfälle an Geld zu kommen. Ein User berichtet z.B. davon, einen naiven College-Studenten, der vom Geld der Eltern Cannabis gekauft und an der Uni verkauft hat, bei einem Deal mit einer Waffe überfallen zu haben.
Betrug
3 User (2 % / 1 von 50) verdienen Geld mit Betrügereien. Mehrfach genannt wurde dabei der Verkauf gefälschter Produkte wie Uhren und Schmuck.
Bezahlte Umfagen
3 User (2 % / 1 von 50) nutzen Online-Plattformen, auf welchen sie Geld für das Beantworten von Umfragen erhalten. Ein Beispiel hierfür ist die Plattform MTurk
Hinweis zum Schluss: Wieso addieren sich die fettmarkierten Prozente nicht auf 100 Prozent? Das liegt daran, dass viele User gleich mehrere Methoden nutzen. Etwa sexuelle Dienste anbieten und Eigentum verkaufen. Oder einem gewöhnlichen Job nachgehen und trotzdem stehlen, wenn es eng wird. Für jeden User wurden stets alle Methoden der Geldbeschaffung notiert, die dieser verfolgt.
Zum Anteil Männer und Frauen unter den n = 152 Usern lässt sich keine konkrete Zahl nennen. Eine Angabe des biologischen Geschlechts gab es nur in Einzelfällen. Jedoch konnten die User weibliche und männliche Avatare für ihr Profil wählen. Nach diesen dürfte der Großteil dieser User (etwa 80 %) männlich sein. Es dürfte sich bei fast allen Usern auch um US-Amerikaner handeln, da bei Nennung eines Ortes oder einer Region, diese in jedem Fall in den USA lag und die Subforen auch bekannt dafür sind, hauptsächlich von US-Amerikanern genutzt zu werden.
Ich habe vor kurzem mithilfe eines tollen Datensatzes vom Harvard Dataverse die Risikofaktoren für Alpträume herausgearbeitet. Alles Folgende basiert auf Antworten, die n = 571 Amerikaner, mittleres 36 Jahre (von 14 bis 84 Jahre), 44 % Frauen, auf einem Fragebogen notiert haben.
Einflüsse aus Kindheit & Jugend
Einige Variablen frühkindlicher Erfahrung zeigen eine Assoziation mit der Häufigkeit von Alpträumen im Erwachsenenleben. Unter jenen Teilnehmer, die sehr streng erzogen wurden, berichten 39 ± 14 % von regelmäßigen Alpträumen, während es bei Teilnehmern ohne strenge Erziehung nur 10 ± 3 % sind. Das Ergebnis ist signifikant mit einem Niveau p < 0,001.
Auch die Beziehung der Eltern untereinander scheint eine Rolle zu spielen. Bei Teilnehmern, die als Kinder oft die Eltern beim Streiten erleben mussten, berichten 31 ± 10 % von häufigen Alpträumen. Unter jenen mit harmonischem Elternhaus sind es hingegen nur 11 ± 5 %. Die Signifikanz ist p < 0,001.
Ein weiterer wichtiger Faktor ist Parentifikation. Bei Menschen, die im Kindesalter in die Pflicht genommen wurden, ein Elternteil emotional zu stützen (Vertauschung Eltern-Kind-Rolle), geben 44 ± 16 % häufige Alpträume an. Bei jenen ohne einen solchen Hintergrund sind es 14 ± 4 %. Auch hier ist p < 0,001.
Als problematisch zeigt sich auch Drogenkonsum im Jugendalter. Unter Leuten, die im Jugendalter sehr viel Alkohol getrunken haben, berichten 46 ± 20 % von regelmäßigen Alpträumen. Bei Leuten, die in der Jugend trocken oder praktisch trocken geblieben sind, sind es nur 14 ± 3 %. Hier ist p < 0,01.
Cannabiskonsum im Jugendalter zeigt sogar eine noch stärkere Assoziation. 69 ± 26 % jener, die als Teenager viel gekifft haben, berichten im Erwachsenenalter von häufigen Alpträumen. Dem steht der Anteil 15 ± 3 % gegenüber, ein Unterschied mit einer Signifikanz von p < 0,001.
Konsum
Auch aktueller Konsum kann das Risiko für Alpträume erhöhen. Bei Leuten, die aktuell viel Alkohol konsumieren, leiden 41 ± 18 % unter regelmäßigen Alpträumen. Bei Nicht- oder Wenig-Trinkern sind es hingegen 15 ± 4 %. Hier gilt p < 0,01.
Dasselbe gilt für aktuellen Cannabis-Konsum. 46 ± 20 % der regelmäßigen Konsumenten und 14 ± 3 % der Nicht-Konsumenten berichten von häufigen Alpträumen. Es ist p < 0,01.
Bei Koffein zeigt sich eine leichte Erhöhung des Risikos, jedoch ist diese nicht statistisch signifikant. Unter Koffein-Liebhabern berichten 24 ± 8 % von regelmäßigen Alpträumen, bei entkoffeinierten Menschen sind es nur 16 ± 6 %. Es ist p = 0,11.
Häufiger Konsum zuckerhaltiger Getränke verfehlt ebenso knapp die Schwelle der Signifikanz. 28 ± 14 % der regelmäßigen Konsumenten zuckerhaltiger Getränke berichten von häufigen Alpträumen, dem stehen 15 ± 5 % bei jenen, die Zuckergetränke meiden, gegenüber. Hier gilt p = 0,08.
Lebensumstände
Umbrüche im Leben scheinen gemäß der Umfrage ein deutlicher Trigger für Alpträume zu sein. Abgefragt wurden vier gängige Umbrüche: Jobwechsel, Wohnortwechsel, Änderungen in der Freizeit und Änderungen im Freundeskreis. Jede dieser Variablen zeigt einzeln eine signifikante Erhöhung des Risikos für Alpträume. Zum Zwecke der Analyse in eine einzige Variable gepoolt, berichten unter jenen, die einen hohen Score erreichen, 44 ± 18 % von häufigen Alpträumen, während es bei jenen Leuten, bei denen keiner dieser Umbrüche kürzlich stattgefunden hat, nur 12 ± 4 % sind. Die Signifikanz ist p < 0,001.
Eine Gefahr kann auch zu wenig freie Zeit darstellen. 36 ± 14 % jener Teilnehmer, die angeben kaum freie Zeit zur Verfügung zu haben, erleben regelmäßig Alpträume. Demgegenüber stehen 13 ± 7 % bei jenen, die einen besseren Ausgleich von Arbeits- und Freizeit gefunden haben. Es gilt p < 0,01.
Finanzielle Probleme können sich auch in Alpträume niederschlagen. Unter Menschen, die damit kämpfen ihre Rechnungen zu zahlen, haben 30 ± 11 % häufige Alpträume. Bei jenen ohne einen solchen Druck sind es 12 ± 5 %. Ein Unterschied mit einer Signifikanz von p < 0,01.
Interessanterweise scheint auch das Wohnviertel eine Rolle zu spielen. In der Umfrage konnten die Teilnehmer angeben, ob sie ihr Wohnviertel als eine “Bad Neighborhood” einstufen würden. Jene Teilnehmer, die das tun, haben zu 70 ± 30 % Alpträume. Bei Verneinung sind es nur 17 ± 4 %. Sehr klar signifikant mit p < 0,001.
Weniger Lebensumstand und mehr Lebensführung, soll die folgende Variable trotzdem hier angebracht werden. Das Ergebnis ist wenig überraschend. 28 ± 10 % der Leute, die oft Horrorfilme schauen, haben regelmäßig Alpträume, gegenüber 12 ± 3 % bei jenen, die das nicht tun. Hier ist p < 0,01.
Thermoregulation
Das folgende Ergebnis ist schon deutlich überraschender. Von den Menschen, die angeben oft übermäßig kalte Hände und Füße zu bekommen, haben 30 ± 11 % häufige Alpträume. Bei guter Thermoregulation sind es nur 10 ± 4 %. Es gilt p < 0,001.
Noch klarer ist der Unterschied bei übermäßig heißen Händen und Füßen. Bei jenen, bei denen das häufig passiert, haben 68 ± 20 % regelmäßige Alpträume, gegenüber 16 ± 4 % beim Rest. Auch das gilt mit sehr hoher Signifikanz p < 0,001.
Psychische Probleme & Störungen
Gemessen am Verhältnis der Gruppen ist der größte Risikofaktor für Alpträume die Neigung zur Borderline-Persönlichkeit. 60 ± 12 % der Menschen, die einen sehr hohen Score auf der Borderline-Skala erzielt haben, leiden unter regelmäßigen Alpträumen. Bei Menschen mit geringem Score auf der Skala sind es nur 4 ± 4 %. Es gilt p < 0,001.
Menschen mit starker Tendenz zu Narzissmus zeigen ebenso ein erhöhtes Risiko. Hier steht ein Anteil 36 ± 11 % mit regelmäßigen Alpträumen bei Teilnehmern mit hohem Score auf der Narzissmus-Skala einem Anteil 14 ± 7 % bei Teilnehmern mit niedrigem Score gegenüber. Es ist p < 0,01.
Hand in Hand damit geht das Ergebnis, dass auch ein Mangel an Empathie ein Mehr an Alpträumen bringen kann. Bei den Teilnehmern, mit sehr geringem Score auf der Empathie-Skala, berichten 46 ± 14 % von häufigen Alpträumen. Bei sehr empathischen Teilnehmern sind es 13 ± 5 %. Es gilt p < 0,001.
Etwas mehr in Richtung psychischer Probleme statt psychischer Störung ist das Ergebnis zu Selbstbewusstsein. Ein angeknackstes Selbstbewusstsein macht sich wohl auch Nachts bemerkbar. 34 ± 10 % der Teilnehmer, die sich selbst ein geringes Selbstbewusstsein attestieren, leiden unter häufigen Alpträumen. Unter jenen mit gutem Selbstbewusstsein sind es nur 11 ± 6 %. Der Unterschied ist klar signifikant mit p < 0,001.
Von den vielen Assoziationen in Richtung psychischer Probleme, die im Datensatz zu finden sind, sei noch eine aufgrund des hohen Korrelationskoeffizienten hervorgehoben: Neid. Bei Teilnehmern, die angeben oft von Neidgefühlen geplagt zu sein, haben 55 ± 18 % häufige Alpträume. Unter jenen Teilnehmer, bei denen diese Gefühle nur selten auftreten, sind es 11 ± 5 %. Auch hier ist p < 0,001.
Alter
Abschließend noch eine sehr gute Nachricht: Aus Alpträumen reift man i.d.R. heraus. Je älter eine Person, desto geringer das Risiko für Alpträume. Unter den Teilnehmern in ihren 20ern, werden 27 ± 7 % von regelmäßigen Alpträumen heimgesucht. Bei Teilnehmern ü60 sind es nur noch 8 ± 4 %. Es gilt p < 0,001. Die Abnahme des Risikos verläuft sogar kontinuierlich, jedes Jahrzehnt bringt merkliche eine Besserung.
Kleingedrucktes
Es gilt wie immer der Leitsatz: Ursache und Wirkung lässt sich in der Wissenschaft grundsätzlich nur mit kontrollierten Experimenten identifizieren. Alles andere sind bloße Assoziationen. So habe ich zum Beispiel im Datensatz gesehen, dass Menschen mit Tattoos ein leicht erhöhtes Risiko für Alpträume haben. Man darf wohl davon ausgehen, dass dieser Zusammenhang bloß korrelativ ist. So könnten in dem Sample Menschen mit Tattoos im Mittel jünger sein als jene ohne Tattoos und sich das erhöhte Risiko auf diesem Umweg erklären. Eine Ursache-Wirkung muss nicht bestehen bzw. wird sogar mit sehr hoher Wahrscheinlichkeit in vielen der oben angeführten Assoziationen nicht bestehen. Es ist prinzipiell unmöglich Ursache-Wirkung aus Fragebögen abzuleiten.
Diese Feststellung ist auch wichtig im Bezug auf Heilung. Wer den obigen Text gelesen hat und unter Alpträumen leidet, wird geneigt sein, die ein oder andere Assoziation umkehren zu wollen. Wenn Cannabis-Konsum mit erhöhtem Alptraum-Risiko assoziiert ist, dann dürfte die Senkung des Konsums eine Besserung bringen. Oder etwa nicht? Es spricht nichts dagegen, es zu versuchen. Möglich ist es. Aber es gibt auch keine Garantie, dass eine Umkehrung funktioniert da nicht unbedingt eine Ursache-Wirkung zugrunde liegt. Mein Lieblingsbeispiel hierzu ist Eisverkauf.
Je höher die Temperatur, desto mehr Eis wird verkauft. Das ist eine klare Assoziation. Man könnte auch tatsächlich den Verkauf ankurbeln, indem man eine Maschine entwickelt, welche die Temperatur künstlich anhebt. Man könnte aber natürlich nicht durch eine Beschleunigung des Verkaufs, etwa durch Werbung oder Preissenkung, die Temperatur ankurbeln. Ähnlich verhält es sich wohl mit der Umkehrung einiger der obigen Assoziationen, nur ist es schwieriger zu sehen, da die Zusammenhänge komplexer und abstrakter sind. Ein Selbstexperiment könnte am Ende auf den Versuch hinauslaufen, die Temperatur mit dem Eisverkauf anzukurbeln. Der Gang zum Therapeuten oder Psychiater, welcher über Ursache und Wirkung aufgeklärt ist, ist einem Selbstexperiment sicherlich vorzuziehen.
Einer der wichtigsten Parameter zur Beurteilung von Regressionsmodellen ist der Adjusted R². Er sagt, wieviel der Varianz in der abhängigen Variable y durch die linearen Terme der unabhängigen Variablen x1, x2, x3, etc … erklärt werden kann. Hier soll ohne Verlust der Allgemeinheit nur eine unabhängige Variable x betrachtet werden. Bei einem perfekten mathematischen Zusammenhang wie zum Beispiel y = 0.5*x ergibt sich stets R² = 1 = 100 %. Der Wert von y lässt sich vollständig durch den gegebenen Wert von x erklären. Entsprechend würde man bei R² = 25 % sagen, dass die Variable x wohl 25 % der Varianz in der Variable y erklärt. Und somit 75 % der Varianz von y unerklärt bleibt. Zumindest ist das die gängige Perspektive. Jedoch ist dieser Ansatz nicht ganz ohne Probleme.
Hier ein kleines Experiment. Ich habe in SPSS Werte für x von -2 bis 2 erzeugen lassen, in feinen Stufen, und y aus y = 0.5*x berechnen lassen. Eine lineare Regression zeigt R² = 100 %. Dann habe ich neue Variable x1 berechnet, die sich aus x plus einem Zufallswert von -0,25 bis 0,25 zusammensetzt. Dasselbe für eine neue Variable y1, also y1 = y + Zufallswert. Die Zufallswerte sollen hier Messunsicherheiten simulieren, dazu gleich mehr. Eine Regression mit x1 als unabhängiger und y1 als abhängiger Variable liefert typischerweise R² = 95 %. Trotz des perfekten mathematischen Zusammenhangs zwischen x und y, von dem immer noch ausgegangen wird, führen Messunsicherheiten also dazu, dass ein R² von 100 % nicht mehr erreicht werden kann. Man erreicht unter Annahme eines uniformen Fehlers von -0,25 bis 0,25 nur noch maximal R² = 95 %. Unter Annahmen eines uniformen Fehlers -0,5 bis 0,5 sinkt das sogar auf einen maximal möglichen R²-Wert von 78 %.
Woher können diese Unsicherheiten kommen? Als Beispiel nehme ich eine 4-Punkte Likert-Skala. Die Punkte entsprechen oft den Standardabweichungen z = -1,5, -0,5, +0,5, +1,5. Es besteht durch die grobe Unterteilung einmal ein Repräsentationsfehler. Ist die gemessene Variable kontinuierlich, so kann ein Teilnehmer bei +0,7 liegen, muss sich aber mit der Wahl von +0,5 zufrieden geben. Solch ein Fehler kann maximal 0,5 Standardabweichungen ausmachen (Ränder ignoriert), mit einem Mittel von 0,25. Dazu kommen noch mögliche Einschätzungsfehler. Statt den realen Wert +0,7 auf den nächsten Skalenwert +0,5 zu runden, könnte die Wahl des Teilnehmers auf +1,5 fallen. Maximal dürfte dieser Fehler im Bereich 1,0 Standardabweichungen liegen, mit einem Mittel entsprechend der Fehlerrate p. Alleine an dieser knappen Übersicht sieht man, dass Fehler 0,25+p = 0,3 bis 0,6 Standardabweichungen bei einer 4-Punkte-Skala durchaus typisch sein könnten.
Das alles hat Konsequenzen für die Interpretation des R²-Werts. Nimmt man an, dass R² aufgrund der Unsicherheit maximal 80 % betragen kann, dann muss die Interpretation “R² = 25 % heißt 25 % erklärt und 75 % nicht erklärt” scheitern. Für eine realistischere Einschätzung sollte der ermittelte R² immer auf den maximal möglichen R² bezogen werden. Ein R² = 25 % bei einem maximal möglichen R² = 80 % (erreichbar nur mit perfektem mathematischen Zusammenhang) übersetzt sich demnach in den folgenden Best Guess: Die unabhängige Variable x erklärt 25/80 = 32 % in der Varianz der abhängigen Variable y und es bleibt der Anteil 55/80 = 68 % der Varianz unerklärt. Das Modell erklärt also mehr, als es eine naive Interpretation vermuten lässt.
Der große Unterschied zum naiven Ansatz ist, dass hier der Benchmark zu einem realistischeren Vergleichswert verschoben wird. Weg vom Benchmark des perfekten Zusammenhangs unter perfekten Bedingungen (keine Unsicherheiten) hin zum Benchmark des perfekten Zusammenhangs unter Berücksichtigung der unvermeidbaren Unsicherheiten bei der Messung. Der perfekte Zusammenhang bleibt der ultimative Vergleichswert. Aber es wird berücksichtigt, dass auch der perfekte Zusammenhang gegeben den Unsicherheiten Einbußen im R²-Wert erfahren würde.
Es gibt viele Merkmale der Persönlichkeit, die sich schön einer der fünf Dimensionen des Big-Five-Modells zuordnen lassen. Impulsivität hingegen passt in keine dieser fünf Schubladen und hinterlässt zu allem Übel auch noch viel Erklärungsbedarf nach Verknüpfung mit den Dimensionen. Basierend auf einem Datensatz mit n = 410 Personen besteht der engste Zusammenhang mit der Dimension Gewissenhaftigkeit. Personen mit sehr geringem Score auf der Skala für Gewissenhaftigkeit liegen im Mittel eine halbe Standardabweichung über der Norm für Impulsivität, Personen mit hohem Score hingegen knapp eine halbe Standardabweichung unter der Norm. Das macht eine Effektstärke von etwa Cohen’s d = 1,0 mit hoher Signifikanz p < 0,001.
Nach Bereinigung der Variable Impulsivität nach Gewissenhaftigkeit mittels eines Polynoms dritten Grades (siehe r = 0,000 bei der Spalte ZConsc) ergeben sich die folgenden Korrelationen. Es bleibt ein statistisch signifikanter Zusammenhang mit der Dimension Extraversion.
Tatsächlich kann Extraversion noch ein gutes Stück der verbliebenen Varianz erklären. Introvertierte Menschen liegen etwa 0,4 Standardabweichungen unter der Norm für Impulsivität, während extrovertierte Menschen 0,3 Standardabweichungen darüber zu finden sind. Hier ist Cohen’s d = 0,7 und die Signifikanz bleibt sehr hoch.
Die schon bereinigte Variable wird nochmals mit einem Polynom dritten Grades bereinigt, diesmal nach Extraversion, und es ergeben sich diese Korrelationen. Es lässt sich noch mehr rausholen.
Teilnehmer mit niedrigem Score auf der Neurotizismus-Skala liegen bis 0,2 Standardabweichungen unter der Impulsivitäts-Norm, während jene mit hohem Score circa 0,4 darüber liegen. Man darf hier wohl eine Effektstärke im Bereich Cohen’s d = 0,5 vermuten, auch mit hoher Signifikanz.
Nach nochmaliger Bereinigung bleiben keine signifikanten Zusammenhänge in der Tabelle der Korrelationen übrig. Mehr lässt sich durch die vorhanden Variablen leider nicht erklären. Ein lineares Regressionsmodell mit den Big-Five, allen demographischen Faktoren sowie allen Variablen der Kindheit als unabhängige Variablen bestätigt die obige Analyse:
Alle drei Dimensionen des Big-Five-Modells, Gewissenhaftigkeit, Extraversion und Neurotizismus, sind signifikante Prädiktoren mit p < 0,001, wobei Gewissenhaftigkeit den stärksten Zusammenhang mit dem standardisierten Regressionskoeffizienten ß = -0,36 zeigt (eine Standardabweichung über der Norm bei Gewissenhaftigkeit bedeutet 0,36 Standardabweichungen unter der Norm bei Impulsivität). Gefolgt von Extraversion mit ß = 0,26 (eine Standardabweichung über der Norm bei Extraversion bedeutet 0,26 Standardabweichungen über der Norm bei Impulsivität). Und schlussendlich Neurotizismus mit ß = 0,18 (eine Standardabweichung über der Norm bei Neurotizismus bedeutet 0,18 Standardabweichungen über der Norm bei Impulsivität).
Nichtlineare Zusammenhänge, welche in den Graphen gut zu erkennen waren, erfasst das lineare Modell leider nicht, was sich auch im R² niederschlägt. Gemäß dem adjusted R² erklären die Variablen Gewissenhaftigkeit, Extraversion und Neurotizismus 19 % der Varianz in der Variable Impulsivität. Es gibt zwei gute Gründe anzunehmen, dass diese drei Dimensionen aber einen höheren Teil des Merkmals Impulsivität erklären: a) Nicht-lineare Effekte und b) gewöhnliche statistische Schwankungen.
Unter Berücksichtigung nicht-linearer Zusammenhänge ließe sich R² wohl gut auf 25-30 % steigern (Achtung: Bauchgefühl). Hinzu kommt, dass selbst wenn in der Realität ein perfekter Zusammenhang bestünde, ein R² 100 % aufgrund statistischer Schwankungen nie erreicht werden könnte. Man würde wohl bei 80-90 % an die Grenze des Feststellbaren stoßen. Basierend darauf, vermute ich dass die drei Dimensionen Gewissenhaftigkeit, Extraversion und Neurotizismus das Merkmal Impulsivität zu 30-40 % bestimmen. Eine gute Erklärungskraft, aber es bleibt definitiv eine unerklärbare Lücke.
Interessant ist auch ein knapper Blick auf die Finanzen. Teilnehmer mit hoher Impulsivität berichten im Mittel dasselbe Einkommen wie wenig-impulsive Teilnehmer. Die hohe Impulsivität scheint sich also nicht merklich auf das Einkommen niederzuschlagen.
Umso auffälliger ist aber die Assoziation mit anderen Aspekten der finanziellen Situation. Trotz des gleichen Einkommens berichten impulsive Teilnehmer vermehrt von bestehenden Geldproblemen (struggling to pay rent, healthcare, mortgage) und haben weniger Erspartes (savings).
Interessant auch, und das eher am Rande, ist ein Blick auf die philosophische Ausrichtung. Menschen mit Hang zu starker Impulsivität scheinen ein Herz für existential nihilism zu haben, also der Überzeugung, dass das Leben keinen intrinsischen Wert und keine intrinsische Bedeutung besitzt.
Ich hatte hier schon eine Analyse basierend auf den Daten von “Pharmacokinetics and Pharmacodynamics of Lysergic Acid Diethylamide in Healthy Subjects” notiert, jedoch beschränkt auf die 24 Teilnehmer, welche 100 Mikrogramm LSD (mittelstarke Dosis) bei dem Versuch bekommen haben. Ich wollte das etwas ausweiten durch Einbeziehung jener 16 Teilnehmer, die 200 Mikrogramm (starke Dosis) erhalten haben. Es finden sich viele deutliche und statistische signifikante Unterschiede.
Zu jedem Wert ist im Folgenden stets der Mittelwert und das 95 % Konfidenzintervall angegeben, die Signifikanz der Unterschiede wird jeweils über das Programm SPSS mit einem T-Test geprüft. Erstmal das TLDR:
Bei höherer Dosis …
… ergibt sich ein stärkerer Effekt
… kommt die Wirkung schneller
… hält die Wirkung länger an
… ist das Risiko eines schlechten Trips erhöht
Hier im Detail:
Wenig überraschend führt eine höhere Dosis zu einem stärkeren subjektiven Effekt der Droge gemessen an dem Score auf dem verwendeten Fragebogen. Bei 100 mcg betrug der mittlere Effekt 83 [76-90] %, bei 200 mcg 94 [90-98] %. Die Differenz ist signifikant mit p < 0,05.
Bei einer höheren Dosis tritt die Wirkung schneller ein. Hier gemessen am Peak Onset, die Zeit nach der Einnahme, ab der erstmals 50 % des maximal erreichten Effekts erreicht wird. Bei 100 mcg beginnt der Peak 1,3 [1,1-1,5] h nach Einnahme, bei 200 mcg sind es hingegen 0,7 [0,5-0,9] h nach Einnahme. Die Signifikanz ist p < 0,01.
Der Peak hält bei höherer Dosis auch länger an. Bei 100 mcg fällt der subjektive Effekt nach erstmaligem Überschreiten dieser Grenze “50 % des maximalen Effekts” nach 5,2 [4,6-5,8] h wieder unter diese Grenze zurück. Bei 200 mcg dauert das 7,7 [6,1-9,3] h. Hier beträgt die Signifikanz sogar p < 0,001.
Die gesamte Dauer des Trips, gemessen an Zeit von Einnahme bis Absinken des Effekts auf 10 %, unterscheidet sich ebenso recht deutlich. Bei 100 mcg dauert der Trip 8,8 [8,0-9,6] h, während es bei 200 mcg stolze 12,2 [10,2-14,2] h sind. Die Signifikanz ist hier ebenfalls p < 0,001.
Eine höhere Dosis bringt auch ein erhöhtes Risiko für einen schlechten Trip. Im Mittel beträgt der Score für negative Effekte bei 100 mcg 13 [6-20] % und bei 200 mcg 38 [22-54] %. Es gilt p < 0,01.
Gemessen am Kriterium “Negativer Effekt >= 50 % mindestens einmal während des Trips” hatten von den Teilnehmern mit 100 mcg der Anteil 8 [0-20] % einen schlechten Trip. Bei den Teilnehmern mit 200 mcg sind es 50 [24-76] %. Hier ist auch p < 0,01.
Nicht statistisch signifikant, aber suggestiv ist auch der Unterschied bei Panik-Trips. Bei den Teilnehmern mit 100 mcg empfand kein Teilnehmer Panik während des Trips, bei 200 mcg waren es 13 [0-31] %. Mit p = 0,08 wird die Grenze für statistische Signifikanz aber knapp verfehlt.
Abschließende Anmerkung: Wie auch bei der Dosis 100 mcg findet sich bei 200 mcg ein Zusammenhang zwischen dem Peak Onset und der Wirkung. Je schneller die Wirkung kommt, etwa weil das LSD vom Körper schneller verstoffwechselt wird, desto intensiver der Peak und desto länger hält der Peak auch an. Bei einem schnellen Onset < 1 h hält der Peak bei 200 mcg im Mittel 8,1 h an, während er bei der gleichen Dosis aber einem langsamen Onset > 1 h nur 5,8 h anhält.
Die folgende Analyse basiert auf den Daten der Studie “Pharmacokinetics and Pharmacodynamics of Lysergic Acid Diethylamide in Healthy Subjects”, welche man ab Seite 79 in der Dissertation von Patrick Dolder finden kann. In dieser Studie wurden 24 gesunden Versuchsteilnehmern 100 Mikrogramm LSD (eine mittelstarke Dosis) verabreicht und über den Trip hinweg physiologische und psychologische Daten gesammelt. Zur Erfassung der psychologischen Wirkung wurde ein validierter Fragebogen, welcher alle typischen Effekte von LSD enthält, zusammen mit einer visuellen Skala verwendet.
Die Studie bietet innerhalb des selbst gesetzten Rahmens eine fundierte Analyse, jedoch lässt sich auch darüber hinaus noch viel aus den Daten rausholen. Die folgende Analyse ist also eine Ergänzung und bringt auch einen interessanten Effekt hervor, der in der Studie nicht festgestellt wurde. Erstmal die deskriptive Statistik. Zu jedem Teilnehmer wurden die folgenden drei Parameter notiert:
Maximale Effektstärke – Maximal berichtete Punktzahl auf der Skala
Peak Onset – Zeit nach Einnahme, ab der ein Teilnehmer erstmals die Hälfte seines maximalen Effekts erreicht
Peak Dauer – Zeit von Peak Onset bis zu späterem Absinken des Effekts auf die Hälfte des maximalen Effekts
Effektverlust – Zeit nach Einnahme, ab der der Effekt auf < 10 % sinkt
Der Peak Onset liegt im Mittel bei 1,3 h mit einer Standardabweichung 0,6 h. Der Peak beginnt also typischerweise 0,5 bis 2 h nach Einnahme, eine recht große Streuung. Der nun erreichte Peak dauert dann im Mittel 5,1 h mit einer Standardabweichung von 1,5 h. Auch hier gibt es eine hohe Streuung mit typischen Werten von 3,5 bis 6,5 h. Dies ist die Dauer ab dem Peak Onset, nicht ab Einnahme. Von Einnahme bis Ende des Peaks sind es im Mittel 1,3+5,1 = 6,4 h, typischerweise zwischen 0,5+3,5 = 4 h und 2+6,5 = 8,5 h. Die Zeit von Einnahme bis zu praktisch kompletten Verlust des Effekts beträgt im Mittel 8,8 h mit einer Standardabweichung 1,9 h. Also grob von 7 bis 11 h.
Die Daten, und das wurde in der Studie nicht vermerkt, zeigen einen interessanten Zusammenhang zwischen der Geschwindigkeit des Onsets und der Wirkung. Bei einem schnellen Onset des Peaks ergibt sich ein stärkerer maximaler Effekt und ein längerer Peak. Zum Nachweis habe ich die Teilnehmer in zwei Gruppen unterteilt und einen T-Test durchgeführt. Die beiden Gruppen sind hier: Schneller Onset (Onset < 1,5 h, n = 11) und Langsamer Onset (Onset >= 1,5 h, n = 13).
In der Gruppe der Teilnehmer mit schnellem Onset betrug die maximale Effektstärke im Mittel 94 % mit einem 95 % Konfidenzintervall von 90 bis 97 %. Bei langsamem Onset waren es nur 78 % mit einem 95 % KI von 62 bis 83 %. Der Unterschied ist statistisch signifikant mit p < 0,01.
In der Gruppe der Teilnehmer mit schnellem Onset dauerte der Peak im Mittel 6,4 h mit einem 95 % KI von 5,7 bis 7,0 h. Bei langsamem Onset sind es nur 4,1 h mit einem 95 % KI von 3,7 bis 4,6 h. Der Unterschied ist statistisch signifikant mit p < 0,001.
Auch dauerte der gesamte Trip bei schnellem Onset länger, jedoch ist der Unterschied hier nicht signifikant. 9,4 h von 8,1 bis 10,8 h in der Gruppe mit schnellem Onset und 8,2 h von 7,4 bis 9,1 h bei langsamem Onset. Der entsprechende p-Wert ist p = 0,14.
Wieso kommt bei manchen Leuten der Peak schneller als bei anderen? Eine korrekte Antwort ist die verwendete Methode des Konsums (schnellere sublinguale Aufnahme versus langsamere oral Aufnahme), jedoch ist diese Antwort hier nicht zielführend da alle Teilnehmer der Studie diesselbe Konsummethode verwendet haben. Eine weitere generell richtige, aber hier nicht relevante Antwort ist die Reinheit der verwendeten Blotter. Nur weil 100 mcg drauf steht, muss nicht 100 mcg drin sein.
Eine weitere mögliche Antwort, diese ist hier zentral, ist die Geschwindigkeit der Verstoffwechselung. Wird das LSD schnell verstoffwechselt, dann tritt der Peak schneller auf. Das ist naheliegend, aber ich wollte es trotzdem prüfen. Ich habe zu jedem Teilnehmer noch die Zeit nach Einnahme notiert, bei welcher die Konzentration von LSD im Blut maximal war, und eine lineare Regression durchgeführt.
Es gibt einen sehr deutlichen Zusammenhang in oben angeführter Weise mit einem standardisierten Regressionskoeffizienten ß = 0,50 und p < 0,001. Die Geschwindigkeit der Verstoffwechselung erklärt etwa R² = 25 % in der Varianz des Peak Onsets. Die Verstoffwechselung ist also tatsächlich eine wichtige Komponente, erklärt aber nur einen Teil der Unterschiede zwischen den Teilnehmern. Es muss neben der Konsummethode, Reinheit und Verstoffwechselung noch andere wichtige Faktoren für den Peak Onset geben, die Daten geben dazu leider nichts her.
Für manche Zwecke ist eine Verschlüsselung von Nachrichten ratsam oder gar erforderlich. Eine gute, einfache und oft verwendete Methode der Verschlüsselung ist PGP. Hier ein Guide wie man diese nutzt, unterteilt in die Abschnitte: Einrichtung, Nachricht senden und Nachricht empfangen.
Einrichtung
Ich empfehle die Verwendung des Programms gpg4usb. Nach dem Download und dem ersten Start wählt man zunächst die Sprache aus:
Und erzeugt einen neuen Schlüssel:
Man wählt dazu einen Namen, eine E-Mail-Adresse sowie ein Passwort. Dieses sollte man sich gut merken. Das Passwort wird immer bei der Entschlüsselung von Nachrichten abgefragt. Auf OK klicken und der Schlüssel wird erzeugt.
Die Einrichtung ist damit schon abgeschlossen.
Nachricht senden
Um eine Nachricht an eine Person schicken zu können, benötigt man dessen Public Key (öffentlicher Schlüssel). Dieser sieht in etwa so aus:
Ich musste es hier in zwei Bilder unterteilen, aber es ist einfach ein langer, kontinuierlicher Text beginnend mit —–BEGIN PGP PUBLIC KEY BLOCK—– und endend mit —–END PGP PUBLICK KEY BLOCK—–. Man kopiert den kompletten Text, inklusive den Zeilen mit BEGIN und END.
Danach ins Programm wechseln, zu der Option “Schlüssel” gehen, “Importiere Schlüssel aus” und auf “Zwischenablage” klicken.
Man bekommt ein Fenster zur Bestätigung:
Mit Klick auf OK wird dieser Public Key dem Programm hinzugefügt. Diese Person ist nun in der “Kontaktliste”.
Den Import des Schlüssels muss man für jede Person nur einmal machen. Hat man die Person schon von früherer Kommunikation in der Liste, reicht es mit dem Folgenden fortzufahren. Man tippt seine Nachricht ein und wählt den Kontakt aus:
Danach auf Verschlüsseln klicken:
Ist man bei dieser Person schon in der Kontaktliste, dann reicht das so. Einfach die Nachricht rauskopieren und verschicken.
Bei der ersten Nachricht an eine Person sollte man aber noch seinen eigenen Public Key anhängen. Die Person könnte zwar unsere Nachricht lesen, könnte aber ohne Kenntnis unseren Public Keys nicht verschlüsselt antworten. Also sich selbst markieren, rechter Mausklick und auf “Hänge die ausgewählten Schlüssel an” klicken.
Nachricht empfangen
Irgendwann wird man eine Antwort erhalten. Diese sieht in etwa so aus:
Zur Entschlüsselung kopiert man den Text ins Programm, wählt sich selbst aus und klickt auf “Entschlüsseln”
Nun muss man das bei der Einrichtung gewählte Passwort eintippen:
Nach Klick auf OK ist die Nachricht entschlüsselt
Das klingt am Anfang alles etwas kompliziert, aber nach ein paar Nachrichten hat man den Dreh ziemlich schnell raus. Wie der Name schon impliziert, kann man das Programm auch bequem von einem USB-Stick aus starten. So bleiben keine Rückstände auf dem PC.
Seit knapp einem Monat vertreiben verschiedene Online-Händler die Substanz 1v-LSD in D. Die Substanz ist neu und derzeit nicht reguliert. Es wird vermutet, dass diese sich nach Einnahme zu LSD-25 verstoffwechselt, ähnlich wie es bei dem Vorgänger 1cp-LSD der Fall war. Einen Nachweis aus dem Labor gibt es dafür jedoch noch nicht. Ich habe aus Neugier erste User-Erfahrungen mit Valerie von dem Forum Eve&Rave und dem Subreddit zu 1v-LSD gesammelt. Insgesamt konnte ich 22 Erfahrungsberichte finden.
Das Große und Ganze: Visuals werden als gleichwertig zu (+) oder gar stärker als bei (++) LSD-25 berichtet. 2 von 13 Usern (15 %) berichten von einer ungewöhnlich langen Dauer des Rausches, ansonsten gibt es bei der Dauer keine Auffälligkeiten. Von gefährlichen Nebenwirkungen berichtet kein User, auch nicht bei sehr hohen Dosen. Das ist sehr beruhigend. Jedoch beschreiben 4 von 22 Usern (18 %) starke Übelkeit. Da man davon ausgehen kann, dass 1v-LSD sich mit Vomex verträgt (so der Fall bei LSD-25 und 1cp-LSD), sollte dies kein besonderes Problem darstellen.
Zur Dosis wird von Herstellern die folgende Äquivalenz angegeben: 150 mcg Valerie = 125 mcg 1cp-LSD = 100 mcg LSD-25. Shoutout an den einen Kerl, der sich gleich 600 mcg einer komplett unbekannten Substanz gibt. Damn Bro.
Nicht jede Impfung resultiert in einer ausreichenden Immunantwort. Bei manchen Menschen enthält das Blut nach abgeschlossener Impfung keine nachweisbaren Antikörper oder Antikörper in unzureichender Konzentration (hier definiert als FRNT50 < 50). Neutralisationstest zeigen dabei eine deutliche Abhängigkeit vom Alter. Hier ein Überblick über fünf Studien. Angegeben ist stets der Anteil Probanten, bei denen die Immunantwort nicht nachweisbar oder schwach war sowie das entsprechende 95 % Konfidenzintervall. Die spezifischen Anteile hängen natürlich immer davon ab, welcher Impfstoff verwendet wurde und gegen welche Variante das Blut getestet wurde, jedoch zeigt sich in jeder der fünf Studien ein erhöhtes Risiko für einen unzureichenden Impfschutz im hohen Alter.
Die Wahrscheinlichkeit eines unzureichenden Impfschutzes dürfte in der Altersgruppe 60-80 demnach etwa 2,5-Mal so hoch sein wie in der Altersgruppe <60 und in der Altersgruppe >80 sogar 5,2-Mal so hoch. Beide Ergebnisse sind statistisch signifikant mit p < 0,001. Das Ergebnis deckt sich mit Studien zu Impfstoffen gegen die Grippe, auch dort gibt es im hohen Alter oft eine unzureichende Immunantwort. Und es verdeutlicht die Notwendigkeit von zeitigen Boostern für Menschen 60 Jahre oder älter. Erste Studien zur dritten Dosis haben schon gezeigt, dass das Risiko eines unzureichenden Impfschutzes 28 Tage nach dritter Dosis deutlich kleiner ist als 28 Tage nach zweiter Dosis.
Es ist kein Naturgesetz, dass eine vollständige Impfung gegen Covid nur zwei Dosen enthalten soll. Es gibt Krankheiten, gegen welche die Impfung erst nach vier oder fünf Dosen als abgeschlossen gilt. Das Schema der zwei Dosen gegen Covid war vor allem eine Folge des Zeitdrucks. Die Zeit, ein Schema über zwei Dosen hinaus zu testen, war schlicht nicht gegeben. Es ist aber auch kein Naturgesetz, dass jede Altersgruppe einen Booster braucht bzw. davon überhaupt profitieren würde. Ob das so ist wird sich über die nächsten Monate zeigen.
In der Studie “Age-dependent immune response to the Biontech/Pfizer BNT162b2 COVID-19 vaccination” (Müller et al 2021) wird untersucht, ob die Teilnehmer nach einer vollständigen Impfung mit Biontech auch tatsächlich Antikörper im Blut tragen, die das Sars-Cov-2-Virus neutralisieren können. Interessant ist hier vor allem der Vergleich der Immunantwort bei verschiedenen Altersgruppen. Die Studie stellt fest, dass in der Gruppe junger Menschen (60 Jahre oder jünger) nur 7 von 91 Leuten oder knapp 7,7 % einen unzureichenden Impfschutz* mit auf den Weg bekommen. In der Gruppe älterer Menschen (80 Jahre oder älter) sind es hingegen 51 von 85 Menschen oder 60,0 %.
Unzureichender Impfschutz
Größe der Stichprobe
Junge Menschen
7
91
Ältere Menschen
51
85
Zum Risk Ratio RR kommt man, indem man diese Prozentzahlen in intuitiver Weise weiter verarbeitet. Das Risiko junger Menschen, einen unzureichenden Schutz zu entwickeln, beträgt gemäß der obigen Studie 7,7 %. Das Risiko älterer Menschen beträgt 60 %. Das Risiko ist bei älteren Menschen also 60/7,7 = 7,8-Mal höher. Das Risk Ratio ist somit schlicht RR = 7,8. Es ist eine Kennzahl, die sehr einfach zu interpretieren ist. Sie drückt aus, um welchen Faktor das Risiko beim Vergleich zweier Gruppen erhöht bzw reduziert ist. Immer wenn man RR sieht, sollte man sich denken: “Das Risiko in Gruppe A ist RR-Mal so hoch wie in Gruppe B”. Statt Risiko darf man auch die Begriffe Wahrscheinlichkeit oder Prävalenz verwenden.
Das Odds Ratio ist im Vergleich dazu recht sperrig. Das liegt wohl daran, dass das Konzept von Odds (Chancen) im Alltag und der Schule viel seltener verwendet wird als das Konzept Wahrscheinlichkeit. Hier ein alternativer Weg das obige Ergebnis zu formulieren: Bei jungen Menschen gab es 7, die eine unzureichende Immunantwort hatten, und 84, die eine ausreichende Immunantwort hatten. Die Odds für eine unzureichende Immunantwort sind 7/84 = 0,083. Bei älteren Menschen gab es 51 mit unzureichender Immunantwort und 34 mit ausreichender Immunantwort. Die Odds sind hier 51/34 = 1,5. Das Odds Ratio ist entsprechend OR = 1.5/0.083 = 18,1.
Unzureichender Impfschutz
Ausreichender Impfschutz
Junge Menschen
7
84
Ältere Menschen
51
34
Was gerne gemacht wird, ist das Odds Ratio zu nehmen und das Ergebnis wie beim Risk Ratio zu formulieren. Also von einem Odds Ratio 18,1 zu schließen, dass ältere Menschen ein 18,1-Mal höheres Risiko für unzureichenden Immunschutz haben wie junge Menschen. Findet man leider so in vielen Nachrichtenartikeln. Wie man an dem Beispiel sieht, kommt man dadurch aber auf den falschen Zweig. Das Risiko ist tatsächlich 7,8-fach erhöht. Korrekt wäre zu sagen, dass die Odds für unzureichenden Immunschutz bei älteren Menschen 18,1-fach erhöht sind (und dann erklären, was Odds überhaupt sein sollen). Wie gesagt, es ist eine recht sperrige Kennzahl.
Aber ganz unintuitiv sind Odds nicht. Die Odds 51/34 = 1,5 bedeuten, dass in der Gruppe älterer Menschen auf eine Person mit guter Immunantwort statistisch 1,5 mit schlechter Immunantwort kommen. Bevorzugt man ganze Zahlen kann man auch sagen, dass auf zwei Personen mit guter Immunantwort kommen drei mit schlechter kommen. Die Odds 7/84 = 0,083 bedeuten, dass bei jungen Menschen auf 12 Personen mit guter Immunantwort 1 Person mit schlechter kommt. Odds sind sehr eng verwandt mit Wahrscheinlichkeit, nehmen nur eine etwas andere Perspektive ein. Statt zu schauen, wie oft ein gewisser Ausgang im Bezug zur gesamten Bevölkerung auftritt, so wie es bei der Wahrscheinlichkeit gemacht wird, wird betrachtet, wie oft der Ausgang auftritt und wie oft nicht.
Ein für die meisten Leute weniger relevanter Vorteil des Odds Ratios gegenüber des Risk Ratio ist Umrechnung. Das Odds Ratio lässt sich sehr leicht und ohne zusätzliche Informationen in andere Effektstärken umwandeln. Es gibt eine Formel, um OR zu Cohen’s d oder Hedge’s g zu konvertieren. Eine Formel, um OR in den Korrelationskoeffizienten umzurechnen. Und die Umwandlung in Wirksamkeit ist auch schnell gemacht (Wirksamkeit gleich 1-OR). Das Risk Ratio nimmt rechnerisch hingegen einen eigenen Raum ein. Es lässt sich nur mit zusätzlichen Informationen umrechnen.
Wie genau? Gegeben sind u Menschen mit unzureichendem Immunschutz unter n jungen Leuten und u’ Menschen mit ebensolchem Immunschutz unter n’ älteren Leuten. Die Wahrscheinlichkeiten für das Auftreten sind p = u/n bei jungen und p’ = u’/n’ bei älteren Menschen. Das Risk Ratio entsprechend RR = (u’/n’)/(u/n). Wir könnten die Situation auch so formulieren: Es gibt bei jungen Menschen u mit unzureichendem und n-u mit ausreichendem Schutz. Unter alten Leuten sind es u’ und n’-u’. Das Odds Ratio ist OR = (u’/(n’-u’))/(u/(n-u)). Sieht nicht schön aus, aber stimmt. Teilt man die Formel für RR durch OR und formt etwas um, dann erhält man:
RR = (1-p’)/(1-p)*OR
Kennt man also die Wahrscheinlichkeiten des Auftretens der untersuchten Sache in beiden Gruppen, im Nenner jene der Kontrollgruppe, dann lassen sich RR und OR eins-zu-eins ineinander umrechnen. Im obigen Beispiel trat unzureichender Impfschutz mit den Wahrscheinlichkeiten 7/91 = 0,077 = 7,7 % und 51/85 = 0,6 = 60 % auf. Die Umrechnung müsste also so geschehen:
RR = (1-0,6)/(1-0,077)*OR
RR = 0,43*OR
Tatsächlich ist auch 7,8 = 0,43*18,1 (mit leichten Rundungsfehlern). Der Knackpunkt ist, dass eine Umrechnung von OR zu RR oder umgekehrt ohne Kenntnis der Wahrscheinlichkeiten nicht möglich gewesen wäre. Für Umrechnungen von OR zu anderen Effektstärken geht es auch ohne weitere Informationen.
Eine nützliche Faustregel lässt sich aus der Formel zur Umrechnung noch herleiten. Sind die Wahrscheinlichkeiten, mit denen die untersuchte Sache in der Bevölkerung auftritt sehr gering (also p und p’ klein gegen 1 bzw. 100 %), dann gilt in guter Näherung RR = OR. Erst wenn in mindestens einer Gruppe hohe Prävalenzen zu sehen sind, unterscheiden sich RR und OR deutlich. RR = OR gilt auch in guter Näherung, wenn die beiden Wahrscheinlichkeiten zwar nicht klein gegen 100 % sind, aber einen ähnlichen Wert besitzen (also p ungefähr p’). In all diesen Fällen darf man RR und OR als austauschbar betrachten.
* Unzureichender Impfschutz bedeutet hier: Keine erkennbare Neutralisierung bei Zugabe des Virus oder Neutralisierung des Virus nur bis zu einer 1:50 Verdünnung des Bluts (und keiner erfolgreichen Neutralisierung bei weiterer Verdünnung des Bluts)
Die Wirkung von Ivermectin bei Covid wird seit mehr als einem Jahr untersucht. Alleine für den Effekt auf Mortalität gibt es schon neun Studien mit Kontrollgruppe. Man sollte meinen, dass mittlerweile ein klares Bild besteht. Aber es bleibt leider unklar, ob Ivermectin hilft oder nicht. Das Warum lässt sich schön in einem einzigen Bild zeigen. Hier sind die neun Studien (dieser Meta-Analyse entnommen) geordnet nach steigender Unsicherheit des Resultats:
Man findet viele kleine Studien (meistens Pilotprojekte), die zum Schluss kommen, dass die Verabreichung von Ivermectin das Risiko eines tödlichen Ausgangs recht deutlich senkt. Doch genau die beiden größten Studien sehen einen solchen Effekt nicht. Ein Funnel Plot macht diese Diskrepanz noch deutlicher:
Alle kleineren Studien (hoher Standardfehler) streuen unterhalb des Mittels der größten Studien. Eine solche Form kann nur durch systematischen Bias entstehen. Ohne Bias ergibt sich in Meta-Analysen eine symmetrische Trichterform: Die größten Studien konvergieren zu einem gemeinsamen Mittel, der wahren Effektstärke, während kleinere Studien nach oben und unten um diese wahre Effektstärke streuuen. Je kleiner die Studien, desto stärker kann die Abweichung vom Mittel sein. Das ist normale statistische Schwankung. Die Betonung liegt hier jedoch auf “nach oben und unten”. Eine systematische Abweichung in nur eine Richtung ergibt sich durch gewöhnliche statistische Schwankungen nicht und ist ein klarer Hinweis auf Publikationsbias. Der Funnel Plot drängt die folgende Frage auf: Was ist mit den kleineren Studien, die keinen oder sogar einen negativen Effekt von Ivermectin gefunden haben, geschehen?
Betrachtet man nur die drei größten Studien, dann ergibt sich folgendes:
Das Odds Ratio ist 0,7 mit einem 95 % Konfidenzintervall von 0,4 bis 1,3. Die Nullhypothese kann nicht abgelehnt werden. Der Schluss daraus ist, dass nicht klar ist, ob Ivermectin hilft oder nicht. Ignoriert man hingegen den ziemlich deutlichen Hinweis auf Publikationsbias und nimmt alle Studien hinzu, dann ergibt sich:
Ein Odds Ratio 0,4 mit 95 % KI von 0,2 bis 0,7. Man käme so zu dem Schluss, dass man die Nullhypothese mit gutem Gewissen ablehnen kann und Ivermectin das Risiko eines tödlichen Ausgangs mit einer Wirksamkeit von 60 % senkt (Wirksamkeit ist Eins minus OR). Was davon stimmt?
Es wäre unverantwortlich und unehrlich, den asymmetrischen Funnel Plot zu ignorieren. Es gibt gute Gründe, wieso dieser in praktisch jeder Meta-Analyse zu finden ist. Und wieso die Untersuchung auf Publikationsbias ein integraler Teil von Meta-Analysen ist. Die verlinkte Meta-Studie selbst erwähnt den Publikationsbias nicht, sie analysiert nur den individuellen Bias der verwendeten Studien. Das ist unüblich für Meta-Studien. Sie stellt jedoch zumindest fest, dass die bisherigen Resultate nicht ausreichend sind für eine behördliche Genehmigung.
Das Beispiel Ivermectin zeigt wieder, wie weitreichend das Problem Publikationsbias in der Wissenschaft ist. Und wie wichtig es ist, dass jede Studie vorregistriert wird und Journale auch konsequent insignifikante Ergebnisse publizieren. Nullresultate haben ebenso viel Aussagekraft wie signifikante Ergebnisse, landen aber leider sehr oft in der Versenkung. Mit der Analyse des Funnel Plots gibt es zwar eine verlässliche Methode dem Publikationsbias auf die Spur zu kommen, jedoch kommt diese Auswertung in vielen Meta-Analysen recht kurz und die Erwähnung des korrigierten Ergebnisses im Abstract bleibt eine absolute Seltenheit.
Wohin kommt man, wenn man im Weltall stur in eine Richtung weiterfliegt? Die intuitive und naheliegendste Antwort lautet: Immer weiter weg. Dass dem nicht unbedingt so sein muss, sieht man schon am Beispiel Erde. Läuft man immer in einer Richtung weiter, konzeptuell unwichtige Hürden wie Meere und Berge mal vernachlässigt, so kommt man nach langer Zeit wieder zum Ausgangspunkt zurück. Und das unabhängig davon, in welche Richtung man sich bewegt. Gefordert ist hier nur, dass die einmal gewählte Richtung beibehalten wird.
Aus der dreimensionalen Perspektive ist das leicht einzusehen. Die Bewegung findet, da strikt gebunden an die Oberfläche, in einem zweidimensionalen Raum statt. Dieser Raum ist endlich, unbegrenzt und geschlossen. Endlich da nur eine endliche Fläche besteht, unbegrenzt da die Fortbewegung nie an eine Grenze stößt und geschlossen da man bei Bewegung in fixer Richtung immer zum Ausgangspunkt zurückkehren wird. Diese Eigenschaften gelten nicht für beliebige zweidimensionale Räume. Eine endlose Platte wäre unendlich, unbegrenzt und offen. Die Eigenschaften werden dem Raum durch die Art der Einbettung in die dritte Dimension verliehen: Die Erdoberfläche lässt sich denken als ein zweidimensionaler Raum, der die Oberfläche eines kugelförmigen dreidimensionalen Raums bildet.
Es ist verlockend, zu jeder genannten Dimension stur “plus Eins” zu rechnen, um ein Analog für die möglichen Konfigurationen unseres dreidimensionalen Raums zu bekommen. Davor macht es aber Sinn darüber nachzudenken, wie zweidimensionale Lebewesen (ohne Möglichkeit des Blicks in die dritte Dimension) experimentell entscheiden könnten, ob sie auf einer endlosen Platte oder einer Kugeloberfläche leben. Die Antwort lautet: Krümmung messen. In einem krümmungsfreien Raum summieren sich die Winkel in beliebigen Dreiecken stets zu 180°. In sphärisch gekrümmten Räumen ist die Winkelsumme hingegen größer als 180°. So lässt sich zum Beispiel auf der Erdoberfläche leicht ein Dreieck mit Winkelsumme 270° (drei rechte Winkel) abstecken: Vom Nordpol runter zum Äquator, ein Stück den Äquator entlang und wieder zurück zum Nordpol. Es bildet sich ein Dreieck mit jeweils drei 90°-Richtungswechsel. In einem krümmungsfreien zweidimensionalen Raum wäre dies nicht möglich.
Unterscheiden müsste man auch zwischen lokaler und globaler Krümmung. Die zweidimensionale Platte, auf die jene Lebewesen beschränkt sind, könnte “Beulen” aufweisen. Kleine Bereiche, in denen lokal eine von Null verschiedene Krümmung gemessen werden kann. Über die globale Krümmung des Raums sagen solche lokalen Abweichungen natürlich nur wenig aus. Um sich sicher sein zu können, die Topologie ihres Universums richtig zu verstehen, müssten diese Lebewesen große Dreiecke abstecken. Idealerweise solche, die den gesamten beobachtbaren Raum abdecken.
Die gute Nachricht ist, dass im dreidimensionalen Raum diesselben Spielregeln gelten: Besteht keine Krümmung in eine vierte Dimension, dann summieren sich die Winkel im Dreieck zu 180°. Physiker haben schon fleißige Vorarbeit geleistet und Dreiecke vermessen, die einen weiten Teil des beobachtbaren Universums abdecken. Der Konsens, der sich daraus ergeben hat, lautet: Unser Universum ist global flach. Die lokalen Krümmungen, von denen es viele gibt, addieren sich nicht zu einer globalen Krümmung. Wir können uns also ziemlich sicher sein, dass wir nicht in einem dreidimensionalen Raum leben, der die Oberfläche einer vierdimensionalen Kugel bildet. Zumindest sofern man davon ausgeht, dass der beobachtbare Teil des Universums tatsächlich auch viel des gesamten Universums ausmacht. Das wäre aber wieder eine andere Frage. Für den Moment soll hingenommen werden, dass dem so ist, und wir in einem global flachen dreidimensionalen Raum leben.
Heißt das zwingend, dass die intuitive Antwort korrekt war? Wenn man stur in eine Richtung weiterfliegt, wird man sich einfach nur weiter und weiter vom Ausgangspunkt entfernen? Kein Zurückkommen, wie es auf der Erdoberfläche der Fall ist? Viele alte Astronomie-Bücher geben hier die Antwort: Ja. Dort findet man häufig den Grundsatz, dass ein global flaches Universum unendlich und offen sein muss. Glücklicherweise hat die Topologie da noch ein Wort mitzureden.
Es gibt Räume, die global flach und gleichzeitig endlich, unbegrenzt und geschlossen sind. Ein solcher Raum ist zum Beispiel der 3-Torus. Es handelt sich hierbei um einen dreidimensionalen Raum, der die Oberfläche eines vierdimensionalen Torus bildet. Um das etwas greifbarer zu machen, lohnt es sich erstmal den 2-Torus zu betrachten, der, wenig überraschend, ein zweidimensionaler Raum ist, der die Oberfläche eines dreidimensionalen Torus bildet. Googelt man den Begriff Torus, dann bekommt man die Form eines “Donuts” vorgesetzt, was dem Torus tatsächlich sehr nahe kommt, sich aber in einem zentralen Punkt davon unterscheidet. Man sollte diese Donut-Form verstehen als eine aufgerollte Form des Torus, nicht als den Torus selbst. Entsprechend ist die Oberfläche dieses Donuts eine aufgerollte Variante des 2-Torus. Diese Unterscheidung ist wichtig, weil sie die Krümmung des Raumes berührt. Die Aufrollung zum Zwecke der Visualisierung zeigt eine Krümmung, die im Raum selbst nicht besteht.
Eine Vorstellung, die der wahren Natur des 2-Torus viel näher kommt, bekommt man mit dem schicken gedanklichen Hilfsmittel Teleportation. Der 2-Torus ist ein glattes Stück Papier, bei welchem man am linken Rand wieder herauskommt, wenn man in den rechten Rand hineinfliegt. Und hinten wieder herauskommt, wenn man vorne hineinfliegt. Es ist dann leicht einzusehen, dass dieser Raum global flach, endlich und trotzdem unbegrenzt sowie wundervoll geschlossen ist. Aber auch diese Visualisierung hat schwerwiegende Probleme: Ein realer 2-Torus hat keine Seiten, in die man hineinfliegen könnte. Um dieses Problem zu beheben, könnte man sich nun die jeweiligen Seiten (links / rechts, vorne / hinten) gleichzeitig aneinandergeklebt denken, womit man zur Donut-Form kommen würde. Hier ist dieser Prozess als gif zu sehen. Damit würde man dem Raum aber wieder eine Krümmung zufügen, die gar nicht besteht. Ich finde es am einfachsten beim Hilfsmittel Teleportation zu bleiben, mit dem Zusatz, dass die Seiten, die hier vorhanden sind, nur dem Verständnis dienen und im Raum selbst nicht existieren.
Den 3-Torus kann man sich entsprechend als ein Zimmer vorstellen, in welchem man in an der linken Wand wieder herauskommt, wenn man in die rechte Wand fliegt. Hinten wieder herauskommt, wenn man vorne hineinfliegt. Und oben wieder herauskommt, wenn man unten hineinfliegt. Mit dem Zusatz, dass all diese Wände nur gedankliche Hilfsmittel sind um die Eigenschaften des Raumes begreifbar zu machen. Alternativ darf man sich auch vorstellen, dass all die Seiten des Zimmers (links / rechts, vorne / hinten, oben/unten) gleichzeitig zusammengeklebt sind und somit die Oberfläche eines vierdimensionalen Donut bilden. Das lässt sich auch sehr gut als gif darstellen.
Aber natürlicher sollte man nie zu weit in bloße Theorie abdriften. Am Ende bleibt die zentrale Frage: Wenn wir tatsächlich in einem solchen 3-Torus leben würden, ließe sich das experimentell nachweisen? Vielleicht. Ein Folge davon wäre ein “Hall of Mirrors”-Effekt. Zurück zum obigen Raum mit seinen magischen Eigenschaften. Was würde man sehen, wenn man in einem solchen Raum sitzt und nach vorne schaut? Man würde sich selbst sehen, also den eigenen Rücken und Hinterkopf. Einige der Photonen, die vom Rücken reflektiert werden, fliegen direkt zu der gedanklich eingefügten Hinterwand, kommen vorne wieder raus und gelangen schlussendlich in die Augen. So sehen wir den eigenen Hinterkopf. Auch Photonen, die aufgrund ihres Flugwinkels nach dem ersten Durchqueren des Raumes nicht zu den Augen gelangen, können nach späteren Durchquerungen des Raums ins Auge fallen. Man sieht sich also mehrfach reflektiert, ins Unendliche hinein, mit abnehmender Schwäche.
Etwas größenwahnsinniger gedacht: In einem 3-Torus-Universum müsste man perfekte Duplikate von Strukturen an anderen Orten des Himmels finden können. Das wäre ein klarer experimenteller Nachweis. Tatsächlich läuft diese Suche schon und zwar unter dem esoterisch anmutenden Begriff “Kosmische Kristallographie”. Die Suche war bisher erfolglos, aber, und das ist ein wichtiger Zusatz, könnte auch erfolglos bleiben, selbst wenn wir in einem 3-Torus leben. Es gibt zwei gute Gründe, wieso die Abwesenheit solcher Duplikate einen 3-Torus nicht ausschließt.
Einmal das Offensichtliche: Lichtintensität. Die Duplikate sind weit entfernt, ein Duplikat der Milchstraße wäre mindestens einen Durchmesser des Universums entfernt, und ist das Licht entsprechend schwach. Hinzu kommt: Zeit. Es dauert eine Zeit, bis die oben beschriebenen Photonen vom Hinterkopf am Auge ankommen. Bei einem kleinen Raum oder einem großen Raum, der schon immer existiert, wäre das kein Problem. Aber wie wäre es bei einem großen Raum, der erst endliche Zeit existiert, wie es wohl für unser Universum der Fall ist? Dann könnten die Photonen sich noch auf dem Weg zum Auge befinden. Je nach Größe des Universums, tauchen die Duplikate vielleicht erst in einigen Milliarden Jahren auf.
Der Kern der Ausführung ist: Die Tatsache, dass sich bei Dreiecken, die den beobachtbaren Teil des Universums abdecken, stets eine Winkelsumme von 180° ergibt und der Raum somit global flach ist, bedeutet nicht zwingend, dass der Raum unendlich und offen ist. Dass man sich zwingend immer weiter vom Ausgangspunkt entfernt, wenn man in die gleiche Richtung weiterfliegt. Das ließe sich nur mit Kenntnis der Topologie des Raums beantworten: Ein endloser euklidischer Raum, ein 3-Torus oder noch etwas wilderes. Es gibt global flache Topologien, in welchen man nach langer Zeit tatsächlich wieder zum Ausgangspunkt zurückkehrt. In manchen sogar spiegelverkehrt.
Wer Zeit und Lust hat etwas tiefer in die Materie einzusteigen, dem kann ich “The Shape of Space” von Jeffrey Weeks empfehlen. Das Buch steht schon seit Jahren in meinem Schrank und ich hole es immer wieder gerne raus. Die Mathematik nimmt keinen sonderlich großen Raum in dem Buch ein. Es ist eine eher humane (trotzdem anspruchsvolle) Einführung in die Basics der Topologie und den möglichen Topologien des Universums. Gut erklärt und angemessen bebildert. Ich bekomme kein Geld wenn man da drauf klickt, ich empfehle es nur gerne.
Vor kurzem habe ich einen YouTube-Channel entdeckt, in welchem der Content-Creater verschiedene Kaliber gegen verschiedene Objekte testet. Immer nach dem Prinzip: Kann X eine Kugel stoppen? Das reicht von Schichten von Papier und Alufolie bis hin zu professionellen Schutzwesten und Humvee-Scheiben. Das alles hat mich wiederum zum Rabbit-Hole Schusswunden gebracht. Wie tödlich sind diese wirklich? Google Scholar bietet eine breite Auswahl an Studien zu dem Thema.
Erstmal eine knappe Übersicht:
Untersuchte Variable
Anzahl Studien / Patienten
Überlebensquote
Schusswunde im Gehirn
3 / 1135
5 %
Schusswunde am Herz
2 / 374
8-24 %
Kopfschuss
3 / 617
48 %
Bauchschuss allgemein
2 / 577
88 %
Bauchschuss mit VS
1 / 226
56 %
Bauchschuss ohne VS
2 / 115
97 %
Mittlere vs. Kleine Kaliber
1 / 511
Reduktion um Faktor 2,3
Große vs. Kleine Kaliber
1 / 511
Reduktion um Faktor 4,5
Distanz zum Krankenhaus
1 / 9205
Halbierung je 3 Meilen
Schusswunden im Gehirn
Am tödlichsten sind wohl Schüsse, welche die Schädeldecke durchdringen und im Gehirn Schäden anrichten. Die Publikationen Bellal et al 2014 (132 Patienten), Cavaliere et al 1988 (178 Patienten) und Robinson et al 2019 (825 Patienten) geben hier weitere Auskunft. Die beobachteten Überlebensquoten reichen von 2 % bis 10 %, mit einem gewichteten Mittel* von 5 %. Demnach überlebt von 20 Patienten in der Regel nur 1 Patient.
Schusswunden am Herz
Bei Schusswunden am Herzen finden sich sehr viele Studien, aber die Streuung der Angaben ist viel höher als bei anderen Körperteilen. In den Studien Ricoli et al 1993 (13 Patienten), Ricks et al 1965 (31 Patienten), Rhee et al 1998 (123 Patienten), Gervin & Fischer 1982 (23 Patienten), Attar et al 1991 (49 Patienten) und Henderson et al 1994 (251 Patienten) variiert die berichtete Überlebensquote von 6,5 % bis 64,5 %, eine ganze Größenordnung. Mögliche Gründe sind hierfür die kleinen Stichproben einiger der Studien und eventuell abweichende Definitionen dafür, was als Herzregion gezählt wird. Als gewichtetes Mittel erhält man die Überlebensquote 24 %. Verwendet man nur die beiden größten Studien, erhält man einen engeren Bereich von 6,5 % bis 10 % und eine kleinere mittleren Quote von 8 %.
Welchen der beiden Mittel sollte man trauen? Sofern die größten Studien zu einem gemeinsamen Mittel konvergieren, was hier der Fall zu sein scheint, ist die Verwendung des Mittels aus den größten Studien praktisch immer verlässlicher. Entsprechend vermute ich das wahre Mittel näher an 8 % als an 24 %.
Kleiner Zusatz: Viele der oben aufgeführten Studien haben auch gleichzeitig Stichwunden am Herz untersucht. Alle kommen zu dem gleichen Schluss: Stichwunden am Herz lassen sich deutlich besser überleben als entsprechende Schusswunden. Über das Wieso weiß ich jedoch nichts.
Kopfschüsse
Kopfschüsse, da sind sich die drei Studien Benzel et al 1991 (120 Patienten), Murano et al 2005 (298 Patienten) und Gressot et al 2014 (199 Patienten) sehr einig, sind eine 50/50-Sache. Die berichteten Überlebensquoten reichen von 44 % bis 51 % mit einem gewichteten Mittel von 48 %. Vor dem Hintergrund des schlechten Ausgangs bei Schusswunden im Gehirn lautet die Regel wohl: Wird die Schädeldecke durchbrochen oder die Kugel von unten in das Gehirn reflektiert, ist der Tod nur selten zu vermeiden. Wird die Kugel hingegen von der Schädeldecke reflektiert, bleibt darin stecken oder geht durch das Gesicht, ist ein tödlicher Ausgang deutlich unwahrscheinlicher.
Prinzipiell sollte jedes Kaliber genügend Energie besitzen, um die Schädeldecke zu durchbrechen. Die Kugel, die Robert Kennedy getötet hat, war von dem kleinsten gängigen Kaliber .22LR und drang bis ins Gehirn vor. Wobei die Wahrscheinlichkeit dafür umso größer ist, je größer das Produkt m*(v/r)² ist, mit m der Masse der Kugel, v dessen Geschwindigkeit beim Aufprall und r dessen Radius. Siehe eine Ausführung der Physik dahinter hier. Und auch umso größer, je mehr die Kugel entlang der Normalen zur Oberfläche der Schädeldecke geht.
Zu den Kopfschüssen lässt sich noch hinzufügen, dass laut Benzal et al 1991 und Grahm et al 1990 bei 11-20 % der Überlebenden schwerwiegende Behinderungen bleiben. Wie bei vielem anderen auch heißt überleben nicht immer gut überleben.
Interessant ist auch noch der Blick auf die Studie Murphy et al 2016 (157 Patienten), in der es speziell um Kopfschüsse geht, die sich die Patentien selbst zugefügt haben. Eine Schlussfolgerung aus den Daten ist, dass ein Ansetzen der Waffe an der Schläfe wohl 3-4 Mal tödlicher ist als das Ansetzen unter dem Kinn oder im Mund. Jedoch überleben selbst beim Ansetzen an der Schläfe noch 18 % der Patienten.
Bauchschüsse
Bauchschüsse haben eine überraschend gute Überlebensquote. Gemäß den Studien Feliciano et al 1988 (300 Patienten) und Davidson et al 1976 (277 Patienten) überleben im Mittel 88 % die Verletzung. Laut Feliciano et al 1988 steigen die Chancen sogar auf 97 %, wenn keine vaskulären Schäden entstehen. Letzteres war in der Studie bei 75 % der Patienten mit Bauchschuss der Fall. Bei Patienten, bei denen mit dem Bauchschuss auch vaskuläre Schaden entstehen, überleben gemäß Feliciano et al 1988 (74 Patienten mit vaskulären Schäden) und Richardson et al 1996 (41 Patienten mit vaskulären Schäden) hingegen nur 56 %.
Anderes
Neben dem Ort der Penetration spielen natürlich auch weitere Faktoren für das Überleben einer Schusswunde eine wichtige Rolle. Dazu gehört offensichtlich auch das Kaliber. Basierend auf einer Stichprobe von 511 Personen mit Schusswunden, geben Braga & Cook 2018 an, dass mittlere Kaliber (.38, .380, 9 mm) im Vergleich zu kleinen Kalibern (.22, .25, .32) die Überlebensquote um das 2,3-fache senken und große Kaliber (.357 magnum, .40, .44 magnum, .45, 10 mm, 7.62 × 39 mm) sogar um das 4,5-fache. Würde man alle größeren Kaliber mit diesen kleinen Kalibern ersetzen, dann würde die Anzahl der Todesfälle durch Schusswunden schlagartig um 40 % sinken.
Ebenso zentral ist natürlich auch der schnelle Zugang zu medizinischer Hilfe. Circo et al 2019 kommt nach der Auswertung von 9205 Todesfällen durch Schusswunden zu dem Schluss, dass jede Meile zusätzliche Distanz zu einem Krankenhaus die Überlebensquote um den Faktor 1,22 senkt. Drei zusätzliche Meilen haben demnach schon die Halbierung der Chancen zur Folge.
* Beim Berechnen des Mittels wurde den jeweiligen Studie ein Gewicht proportional zur Wurzel der Anzahl Patienten zugeordnet. Das weil der Standardfehler im Allgemeinen mit der Wurzel der Stichprobengröße sinkt und sich so ein Mittel ergibt, dass einer ordentlichen Meta-Analyse am nächsten kommt.
Der Anteil erneuerbarer Energien bei der Stromerzeugung (kürzlicher Zuwachs fast alles Wind und Solar) ist gemäß dieser Quelle von 10,5 % im Jahr 2004 auf 46,1 % im Jahr 2019 angestiegen. Kombiniert mit dieser Quelle bedeutet das ein Zuwachs in der Einspeisung von 64 TWh im Jahr 2004 auf 265 TWh im Jahr 2019. Der Zuwachs hat sich stetig beschleunigt, weshalb diese Szenarien bei der zukünftigen Installation erneuerbarer Energien unterschieden werden sollen:
S3 – Optimistisch: +30,0 TWh/a (Noch nie erreicht, aber realistisch)
2019 betrug der gesamte Stromverbrauch 575 TWh. Hier soll als Ziel gesetzt werden:
100 % davon abdecken
+10 % für elektrische Heizungen
Abdeckung von Produktion und Betrieb aller E-Autos bei 100 % Umstieg
Der Verbrauch von E-Autos liegt bei aktuellen Modellen bei etwa 15 KWh/100 km. Im Durchschnitt fährt ein Deutscher 11.733 km pro Jahr. Macht 1760 kWh für den Betrieb eines E-Autos pro Jahr. Mit 48,3 Mio E-Autos (jedes Auto ersetzt durch E-Auto) werden zum Betrieb aller E-Autos 85 TWh/a benötigt.
Diese Autos müssen aber erst produziert werden. Es sollen diese 48,3 Mio E-Autos in 15 Jahren produziert werden, also 3,2 Mio E-Autos pro Jahr. Laut Sato & Nakata 2020 benötigt die Produktion eines Autos 41,8 MJ/kg. Bei einem Gewicht von 1400 kg wären das 58.500 MJ pro Auto bzw. 16.300 kWh. Die Produktion von 3,2 Mio Autos pro Jahr würde also 52 TWh/a erfordern. Rechnen wir noch konservative 10 % für den Aufbau von Ladestationen dazu. Also 57 TWh/a.
Das Ziel beträgt also:
575 + 0,1*575 + 85 + 57 = 775 TWh/a
Wann wird erneuerbare Energie dies alles abdecken können?
S1 – Pessimistisch: 2056
S2 – Mäßig: 2050
S2 – Erfreulich: 2043
S3 – Optimistisch: 2036
Es gibt keinen Grund anzunehmen, dass die Installation erneuerbarer Energien wieder auf das Mittel 2010-2016 fällt. Hingegen ist ein Zuwachs über das Mittel 2016-2019 durch den politischen Willen und den geringen Preis erneuerbarem Strom durchaus möglich. Realistisch dürfte erneuerbare Energie den aktuellen Strombedarf in Deutschland plus elektrische Heizungen sowie den gesamten Individualverkehr inklusive Produktion zwischen 2035-2050 abdecken können. Ab da könnte jeder Zuwachs in die Produktion von grünem Wasserstoff fließen, um Fernlastverkehr*, Schiffe und Flugzeuge anzutreiben.
Die Energie zum Aufbau von Stromspeichern, die ab > 70 % erneuerbar dringend erforderlich werden, ist hier nicht berücksichtigt. Das fällt aber eventuell auch nicht zu stark ins Gewicht. Sollte Wasserstoff als Speicher verwendet werden, so wie es derzeit geplant ist, und wird dieser mit der Sabatier-Reaktion methanisiert, dann ließe sich die komplette Erdgas-Infrastruktur weiternutzen. Der Aufbau einer neuen Infrastruktur wäre nicht erforderlich. Auch Kraftwerke zum Verfeuern des Methans sind schon in ausreichender Zahl vorhanden. Nur die Energie zum Aufbau der Elektrolyseanlagen müssten man hinzurechnen. Alternativ die Kosten des Imports von Wasserstoff aus sonnigeren Regionen, in denen mehr Überschuss zur Produktion von Wasserstoff verfügbar ist.
*Fernlastverkehr ist sehr schwierig zu elektrifizieren. Nahlastverkehr ginge aber relativ problemlos, da diese Grenze nicht (wie oft behauptet) dadurch gesetzt wird, dass Elektromotoren keine hohen Kräfte erzeugen können, sondern sich aus dem begrenzten Energieinhalt der Batterien und den relativ großen Ladezeiten ergibt. Die Forderung hoher Kräfte stellt kein Problem dar sofern nicht gleichzeitig lange Betriebsdauer bzw. große Reichweite benötigt wird.
Bis lange ins 20. Jahrhundert hinein herrschte in der Wissenschaft der Konsens, dass die Gehirne erwachsener Menschen zum größten Teil “in Stein gemeißelt” sind. Man ging davon aus, dass die vielen Prozesse, nach denen sich die Strukturen im Gehirn verändern können, nur in der Kinder- und Jugenzeit wirken. Ist einmal ein kritisches Alter erreicht, festigen sich die Strukturen und das Gehirn bleibt statisch. Ganz gemäß der Redewendung: Was Hänschen nicht lernt, lernt Hans nimmermehr.
Moderne Methoden zur Beobachtung von Strukturen und Prozessen im Gehirn haben die Hypothese des statischen Erwachsenenhirns jedoch überholt. Das Gehirn bleibt auch bis weit ins hohe Alter hinein veränderlich. Zwar kann die Veränderlichkeit nicht mit jener von Kindern konkurrieren, aber sie bleibt groß genug, um weitreichende Umstrukturierungen zu ermöglichen. Mehr dazu findet man gut erklärt in dem kleinen aber feinen Buch Neuroplasticity von Mohab Costandi.
Neuroplastizität ist ein Oberbegriff für all jene Prozesse, nach denen sich das Gehirn strukturell oder funktionell verändern kann. Experimente haben mittlerweile viele solcher Prozesse identifiziert. Hier eine Sammlung einiger dieser Prozesse, unter anderem auf Basis der Publikation, um die es später in dem Eintrag gehen soll:
Neue Nervenzellen werden konstruiert bzw. alte Nervenzellen aufgelöst
Dem Zellkörper werden neue Dendriten hinzugefügt bzw. alte Dendriten eliminiert
Bestehenden Dendriten werden neue Äste hinzugefügt bzw. alte Äste entfernt
Bestehende Dendriten werden verlängert bzw. gekürzt
Die Dichte der Dornenfortsätze (i.d.R. stellen diese die post-synaptischen Regionen) auf den Dendriten wird erhöht bzw. reduziert
Die Form der Dornenfortsätze verändert sich
Die Stärke einer synaptischen Verbindung wird erhöht bzw. gesenkt
Neue Verbindungen werden geschaffen bzw. alte Verbindungen gekappt
Man sieht, dass der Topologie des neuronalen Netzwerks kaum Grenzen gesetzt sind. Noch schöner ist: Man hat die Veränderlichkeit des Hirns zu einem beachtlichen Teil in der eigenen Hand. Es gibt viele Aktivitäten, die nachweislich die obigen neuroplastischen Prozesse anregen. Dazu gehört zum Beispiel Lernen, Computerspiele, künstlerische Betätigung, Reisen, Sport und Meditation.
Eine sehr potente Anregung neuroplastischer Prozesse ergibt sich auch beim Konsum von Psychedelika, wie diese Publikation ausführlich darlegt. So erhöht die Verabreichung von LSD die Anzahl Dendriten, die direkt vom Zellkörper abgehen, im Mittel um 25 %. Die Anzahl Äste pro Dendrit steigt um 75 %. Die gesamte Länge der Dendriten erhöht sich um 20 %. Die Dichte der Dornenfortsätze erfährt sogar eine Verdopplung. All diese Veränderung wurden in der Studie mit einer Signifikanz p < 0,001 festgestellt. Das neuronale Netzwerk gewinnt also deutlich an Komplexität.
Auch erhöht sich der Formenreichtum der Dornenfortsätze, was sich etwas schwieriger in Zahlen ausdrücken lässt, aber gut mit mikroskopischen Methoden festgehalten werden konnte. Zu den reifen Dornenfortsätzen, die für gewöhnlich einem breiten Pilz ähneln, haben sich viele junge Dornenfortsätze gesellt, die entweder einem dünnen, länglichen Pilz gleichen oder eine komplett filamentartige Form besitzen. Die Abhängigkeit der Formbarkeit der Strukturen vom Alter des Organismus konnte die Studie ebenso bestätigen. Die Veränderung der Anzahl Äste pro Dendrit war im frühen Entwicklungsstadium (erstes Instar) knapp 4-Mal höher als im späteren Entwicklungsstadium (drittes Instar). Die Veränderung im dritten Instar war aber trotzdem noch beachtlich.
Es ist aus früheren Experimenten bekannt, dass die gleichzeitige Verabreichung eines Antagonisten für den Serotonin-Rezeptor 5-HT-2A (z.B. Ketanserin) die psychedelische Wirkung von LSD blockiert. Mittlerweile gilt es Konsens, dass eine spezielle Bindung an diesen Rezeptor für die psychedelische Wirkung verantwortlich ist. Eine spezielle Bindung ist gefordert, da viele Stoffe bekannt sind, die ebenso an diesen Rezeptor binden, aber keine psychedelischen Effekte auslösen (gewöhnliche SSRI zum Beispiel). Wieso LSD dies tut ist noch unbekannt. Die Autoren dieser Studie zeigen, dass der Antagonist Ketanserin mit der psychedelischen Wirkung auch die oben aufgeführten neuroplastischen Prozesse unterdrückt. Bei hohen Dosen ist die psychedelische Wirkung also entweder erforderlich oder zumindest schwer zu umgehen bei der Hervorrufung der neuronalen Veränderungen.
Der potente Eingriff von LSD in die neuronale Struktur weckt therapeutische Hoffnung. Es gibt eine Reihe an Experimenten, die demonstrieren, dass psychische Erkrankungen (explizit auch Depression) mit ungünstigen neuronalen Prozessen assoziiert sind, etwa der Auflösung von Neuronen und Reduktion der Dichte an Dornenfortsätzen. Diese Erkenntnisse kann man als Zusätze zu der recht erfolgreichen Serotonin-Hypothese sehen. Psychedelika werden daher in der Forschung zaghaft als Kandidat für eine neue Generation von Antidepressiva (oder zumindest Ergänzung zu SSRI) gehandelt. Die Forschung läuft wegen der staatlichen Repression bisher jedoch nur langsam an.
Wer noch etwas über die Dosierung von LSD erfahren möchte, ist herzlich dazu eingeladen hier weiterzulesen.
Es finden sich im Internet viele Guides zur Dosierung von LSD, die meisten auch sehr verlässlich, jedoch finden sich selten welche, die einen Fit auf experimentelle Daten bieten. Eine aktuelle Studie (2020) zum Effekt verschiedener Dosen im Bereich von 25-200 Mikrogramm gibt es hier. Ein Fit an diese Daten produziert einige nützliche Faustformeln zur Dosierung. In der Studie wurden verschiedene Dosen verabreicht und die subjektive Stärke des Rausches regelmäßig bei den Teilnehmern abgefragt. Die bei Dosis x maximal erreichte Rauschstärke, gemessen in % maximal möglicher Rauschstärke, ergibt sich grob aus:
s_max = 100*(1-20/x)
Umgekehrt: Möchte man beim Konsum eine maximale Stärke s_max erreichen, sollte man die folgende Dosis x wählen
x = 20/(1-s_max/100)
Die aus dem Fit berechnete Schwelle liegt bei einer Dosis x = 20 Mikrogramm. Erst ab dieser Dosis folgt ein merklicher Effekt durch die Droge. Dieser Wert für die Schwelle deckt sich gut mit Angaben aus anderen Quellen.
Dosis x in Mikrogramm
Maximale Subjektive Rauschstärke s_max
20
0 %
40
50 %
60
67 %
80
75 %
100
80 %
150
87 %
200
90 %
Die subjektive Stärke des Rausches nach einer beliebigen Zeit t (in Stunden) nach Einnahme einer Dosis x lässt sich näherungsweiser aus folgendem Fit berechnen. exp bezeichnet die Exponentialfunktion:
s(x,t) = 120*(1-20/x)*t*exp(-t/2,3)
Bei t = 2,3 Stunde, für jede Dosis der Zeitpunkt des Peaks, ergibt sich s = s_max.
Beispielverlauf subjektiver Rauschstärke für x = 100 Mikrogramm:
Zeit t nach Einnahme in h
Subjektive Rauschstärke s(100,t)
0
0 %
0,5
38 %
1
62 %
1,5
75 %
2
80 %
2,5
80 %
3
78 %
3,5
73 %
4
67 %
4,5
61 %
5
55 %
Sei die Tripdauer T definiert als die Zeit von Einnahme bis Absinken der subjektiven Stärke auf 12,5 % nach Erreichen des Peaks. Ein guter Fit an die Daten ist:
T = 16*sqrt(x-20)/(6,7+sqrt(x-20))
Mit der Quadratwurzel sqrt und der Tripdauer T in Stunden. Anekdotisch: Menschen, die SSRI nehmen, haben wohl eine höhere Tripdauer. Hier bietet sich die Multiplikation mit 1,2 oder 1,3 nach Berechnung an. Desweiteren sind Trips bei gleichzeitiger Einnahme von SSRI deutlich weniger visuell bzw. es ist eine höhere Dosis erforderlich, um den selben visuellen Effekt wie ohne Einnahme von SSRI zu erzielen.
Dosis x in Mikrogramm
Gesamte Tripdauer T in h
20
0
40
6,2
60
7,6
80
8,4
100
9,0
150
9,9
200
10,5
Beispiel: Effekt einer Dosis 120 Mikrogramm
Die maximal erreichte Rauschstärke ist:
s_max = 100*(1-20/120) = 83 %
Das ist die erreichte Rauschstärke zum Peak, also nach t = 2,3 Stunden. Eine Zeit t = 8 Stunden nach Einnahme dieser Dosis x = 120 Mikrogramm ist die Rauschstärke noch:
s(120, 8) = 120*(1-20/120)*t*exp(-8/2,3) = 25 %
Die zu erwartende Tripdauer ist:
T = 16*( sqrt(120-20)/(6,7+sqrt(120-20) ) = 9,5 h
Bei Konsum von SSRI sollte man eher um die 12 h erwarten.
Von einem perfekten Fit sollte man nicht ausgehen, die über die obigen Formeln berechneten Werte decken sich aber gut mit den experimentellen Daten der Publikation über den gesamten getesteten Bereich x = 20-200 Mikrogramm.
In der Studie haben sich für Dosen < 100 Mikrogramm keine negativen Rauscheffekte (Unwohlsein, Angst) ergeben. Man darf davon ausgehen, dass solche Effekte für geringere Dosen eher eine Seltenheit sind.
Zu beachten sind bei der Dosierung auch Gewöhnungseffekte.
Nachlegen wie bei anderen Drogen ist bei LSD kaum möglich. Eine Dosis 50 Mikrogramm initial plus 50 Mikrogramm drei Stunden später ergibt nicht diesselbe Wirkung wie 100 Mikrogramm initial. Die Wirkung der späteren 50 Mikrogram verstärkt und verlängert den Rausch etwas, jedoch wird der Rausch in der Qualität weiterhin eher einem Rausch mit 50 Mikrogramm initial gleichen als einem mit 100 Mikrogramm initial. Die nachgelegte Dosis verpufft größtenteils. LSD-User betrachten deshalb ein Nachlegen tendenziell als Verschwendung der Droge.
In den Tagen nach einem Konsum wird ein Gewöhnungseffekt deutlich bemerkbar sein. Laut Trippingly wäre am Tag danach der Konsum einer dreifachen Dosis erforderlich, um diesselbe Rauschwirkung zu erzielen. Zwei Tage danach noch die doppelte Dosis. Und drei Tage danach die 1,5-fache Dosis. Circa sieben Tage danach ist jegliche Gewöhnung abgeklungen, explizit auch bei vorherigem Langzeitkonsum. Wie verlässlich die exakten Zahlenangaben hier sind ist unklar, jedoch ist die obige Beschreibung der Gewöhnung in grober Form korrekt.
Diese schnelle Gewöhnung ist einer der Gründe, wieso das Abhängigkeitspotential bei LSD (ähnlich wie bei magischen Pilzen) als sehr gering einzustufen ist.
Kombination von LSD mit Aspirin, Vomex, Benzos, Kratom, Alkohol, Cannabis und MDMA ist anekdotisch relativ risikofrei sofern es in vernünftigen Dosen geschieht und Dehydrierung vermieden wird. Benzos senken die LSD-Wirkung, Cannabis und MDMA können diese von kaum merklich bis unerwartet deutlich verstärken.
Zu empfehlen ist vor einer vollen Kombination ein Allergietest, also der Konsum einer kleinen Menge der zusätzlichen Droge während eines LSD-Trips um die prinzipielle Verträglichkeit (welche sich von Individuum zu Individuum unterscheiden kann) zu prüfen. Das macht die spätere Kombination auch sorgenfreier.
Da LSD wie auch 1cp-LSD illegal sind, sollte man es selbstverständlich nie zu sich nehmen. Die CDU/CSU, mit der vollen Kraft des lieben Herrgotts hinter sich, schützt uns zum Glück vor solch sündhaften Dingen. 1v-LSD (Valerie) soll zum Zwecke von wissenschaftlichen Experimenten für neugierige Forscher und Privatpersonen ab Ende Juli oder August 2021 legal erhältlich sein. Die ordentliche Prüfung der Sündhaftigkeit wird dann alsbald erfolgen, jedoch benötigt ein solcher Prozess seine Zeit.
Wer noch etwas über die Wirkung von LSD auf Neuroplastizität erfahren möchte, der ist dazu eingeladen hier weiterzulesen.
Vulkane machen vor, wie man die Erde schnell abkühlen kann: Eine massive Injektion von Aerosolen in die obere Atmosphäre. Das führt zu drei Effekten, deren Strahlungsantrieb in der Summe negativ ist: a) Verstärkte Reflektion und Streuung von Sonnenlicht durch die Aerosol-Teilchen, b) Verstärkte Absorption von Sonnenlicht und terrestrischer thermischer Rückstrahlung, c) Verstärkte Reflektion von Sonnenlicht durch verstärkte Wolkenbildung. Klimasimulationen sind sich recht einig darüber, welches Potential für stratosphärische Injektion besteht. Angegeben ist der erwartete Strahlungsantrieb (Radiative Forcing) bei einer Injektion einer gewissen Anzahl Megatonnen Sulfaten pro Jahr in 20-25 km Höhe, gemittelt über die gesamte Atmosphäre:
Ein Strahlungsantrieb von -2 W/m² ließe sich also schon mit grob 10 Mt/a erreichen, -3 W/m² mit 25-30 Mt/a. Die letzte verlinkte Studie beschreibt -2 W/m² als den Grenzwert, der auch bei Erhöhung der Injektionsrate nicht überschritten werden kann, jedoch betrachtet diese nur die Auswirkung der direkten Effekte a) und b). Die anderen Studien, welche jeweils die Summe aller Effekte simulieren, finden einen solchen Grenzwert nicht. Wobei auch bei diesen für hohe Injektionsraten eine Reduktion gegenüber einer naiven linearen Fortsetzung des Trends festgestellt wird. Dass mit steigenden Injektionsraten ab einem gewissen Punkt ein Grenzwert für den Strahlungsantrieb erreicht werden kann ist also gut denkbar, jedoch scheint das noch nicht für Injektionsraten < 50 Mt/a der Fall zu sein.
Alle Studien gehen von einer Injektion in Äquatornähe aus, da hier die Luftströmungen die Aerosole am effektivsten über die gesamte Atmosphäre verteilen. Jedoch wird trotz der relativ effektiven Verteilung bei keiner Simulation eine Gleichverteilung erreicht. Die Konzentrationen bleiben im Äquator höher und der Strahlungsantrieb an den Polen sehr gering. Eine mittlerer Strahlungsantrieb von -2 W/m² sollte man also verstehen als -4 W/m² am Äquator, -2 W/m² in milden Regionen und praktisch 0 W/m² in der Arktis. Die Arktis würde jedoch durch bestehende Mechanismen zum Wärmetransfer (z.B. Verdampfen in den Tropen und Abregnen in der Arktis) trotzdem von der Injektion profitieren. Bei 12 Mt/a ist eine Umkehr des Eisverlustes in der Arktis um 20-40 Jahre möglich.
Für die Reduktion der globalen Temperatur ergibt sich folgendes. Man sollte bei diesen Angaben bedenken, dass die erzielte Reduktion sehr stark davon abhängt, wann die Injektion beginnt, wie lange die Injektion läuft und welche anderen Maßnahmen zur Mitigation des Klimawandels parallel dazu eingesetzt werden.
Wichtig ist hier die Berücksichtigung des Termination Shocks. Nach Beendigung der Injektion wirken die zu dieser Zeit aktuellen Strahlungsantriebe wieder unvermindert. Wurden diese über den Zeitraum der Injektion nicht reduziert, dann folgt ein entsprechender Anstieg der Temperatur. Im Extremfall (Null parallele Mitigation, Szenario RCP8.5) wird der Effekt der Injektion nach einigen Jahrzehnten komplett verpuffen und die Temperatur erreicht wieder grob jene Werte, die man auch ohne Injektion erhalten hätte. Mit paralleler Mitigation lässt sich jedoch durch die Injektion, auch bei Auftreten eines Termination Shocks, ein permanenter positiver Effekt auf die globale Temperatur erzielen.
Bezüglich maximal erreichter Temperatur im Laufe des Wandels produziert eine eigene Simulation mit einer “Spielzeugatmosphäre” eine Reduktion von -0,4 °C im Jahr 2080 (Maximum) bei einmaliger Injektion von 10 Mt/a zwischen 2050-2060 und paralleler Mitigation grob entsprechend dem Szenario RCP2.6. Eine Injektion 20-30 Jahre vor dem injektionsfreien Maximum scheint auch in anderen Szenario stets den größten Effekt auf die maximal erreichte Temperatur zu haben. Für die gesamte absorbierte Wärme über einen längeren Zeitraum spielt das Timing der Injektion jedoch kaum eine Rolle. Disbezüglich ergibt sich immer eine ähnliche Reduktion von 10-15 %. Die Simulation bestätigt auch, dass ohne parallele Mitigation der Effekt der Injektion schnell verpufft.
Zu den Kosten: Diese sind im Vergleich zu anderen Methoden zur Reduktion der globalen Temperatur recht gering. In Klammern ist der Anteil der jeweiligen Kosten am Welt-GDP (87.000 Milliarden) angegeben:
Die möglichen Gefahren einer Injektion habe ich bisher noch nicht zusammengetragen, ich will das in einem späteren Eintrag nachholen. Die Natur hat prinzipiell demonstriert, dass eine massive Injektion von Aerosolen in die obere Atmosphäre ohne katastrophale Langzeitfolgen für das Klima möglich ist. Die plötzliche Abkühlung, die in der Vergangheit für den Großteil der negativen Folgen verantwortlich war, ist in diesem Fall der gewünschte Effekt. Jedoch gibt es viele Unbekannte, wie z.B. den Effekt auf Ozon oder Landwirtschaft.
The IPCC (as well as other research groups) frequently use the term radiative forcing to describe the effects of certain anthropogenic and natural processes on the global temperature. Radiative forcing is a neat way of bringing all these different processes to a common denominator and it even allows a pretty painless estimation of how the global temperature can be expected to develop in the long run. Though some physics is required to fully appreciate it.
Every object emits thermal radiation. The higher its temperature T, the higher the intensity I at which it emits thermal radiation. Intensity here refers to the power emitted in watt per square meter m² of surface area, so its unit is W/m². The Stefan-Boltzman law tells us the specific value for I:
I_thermal = k*T^4
So the intensity of the thermal radiation is equal to some constant times the temperature (in Kelvin) to the power of four. Doubling the temperature thus means that the intensity of the thermal radiation goes up by a factor of 2^4 = 16. Since the intensity is measured in watt per square meter, the total power emitted by the object is just the above expression times the total surface area S:
P_thermal = k*S*T^4
Say you are given an object of very low temperature and put this object under a beam of intense radiation. The radiation reaches the object with an intensity I_incoming. Given that the cross-sectional area of the object relative to the source of radiation is C (its shadow area), the object will absorb energy with the rate:
P_incoming = I_incoming*C
Since we agreed to start with a low-temperature object, we can expect that initially P_incoming > P_thermal. The object absorbs more energy than it emits thermally, so it’s temperature will rise. For how long? The temperature will continue to increase until a balance is established and the absorbed power is equal to the emitted power:
P_incoming = P_thermal
I_incoming*C = k*S*T^4
Solving for T, this allows us to calculate the equilibrium temperature from the intensity of the incoming radiation and the ratio of cross-sectional area to surface area:
T = ( (1/k)*(C/S)*I_incoming ) ^ (1/4)
Granted, it’s not a beautiful formula, but all the more useful. If the intensity changes only by very little in relation to its base value, we can simplify this formula for maximum convenience. The derivation uses a bit of calculus, which I’ll ban to the appendix, but it’s good enough to know that using the above formula, we can arrive at the following rule. Changing the intensity of the incoming radiation by an amount dI changes the temperature by the amount dT:
dT = 0.8*dI
A very simple relationship. Change the intensity by dI = +5 W/m² and the temperature will change by dT = +4 °C. Actually, the value 0.8 is not exact science. Inputting pre-industrial values (temperature 287 K and 340 W/m² at the surface on average) gives you a constant K = T_initial/(4*I_initial) = 0.2 rather than 0.8. Why not use this? The above model does not include any effects of weather and climate. 0.2 corresponds to a body with no surface features. Taking into account an atmosphere which can delay the release of heat, trap it someplace, exhibit complex feedback loops, and so on, changes this constant to 0.8 with a fair amount of uncertainty (0.6-1.0). So it may be more accurate to say that a change in intensity by dI = +5 W/m² will, to the best of our knowledge, lead to a change in global temperature of anywhere between dT = +3 °C and dT = +5 °C, with the best guess around dT = +4 °C.
Now we come to the term radiative forcing. Looking at the IPCC documentation, you will find that anthropogenic land use (for example turning grass into wheat fields) is associated with a radiative forcing of dI = -0.15 W/m². It means that the cumulative effect of all these changes is equivalent to turning the sun down by -0.15 W/m². It takes all the complex changes in environment and condenses them down to a single number. A number that tells us how strong the effect is when converted into an equivalent change in incoming solar radiation. And by extension, using the simplified Stefan-Boltzman law, what its individual effect on global temperature in equilibrium is. The radiative forcing of anthropogenic land use dI = -0.15 W/m² is thus expected to decrease global temperature by anywhere between dT = -0.09 °C to dT = -0.15 °C, with the best guess being around dT = -0.12 °C.
The effect of the ozone layer in its current state corresponds to a radiative forcing of dI = +0.35 W/m², equivalent to turning the sun up by +0.35 W/m² (by the way just a change of 0.09 % of the total incoming solar radiation). From it, we can expect the global temperature to go up by dT = +0.28 °C compared to the pre-industrial global temperature. You can see that the term radiative forcing is pretty useful since it takes two very different effects and brings them to a common basis. It allows us to compare climate effect of processes, that are otherwise very difficult to compare.
For the climate effect of CO2 accumulated in the atmosphere we can use the formula:
dI = 5.4*ln(c/280)
Where c is the current concentration of CO2 in the atmosphere in ppm (280 ppm is the pre-industrial value). For the effect of all greenhouses gases combined, with the concentration of CO2 as a proxy for all others, you can use the constant 8.1 instead of 5.3. ln is the natural logarithm. Currently the atmosphere contains CO2 at a concentration of 410 ppm. Inserting this gives us a radiative forcing of dI = +2.1 W/m² for CO2 alone and dI = +3.1 W/m² for all greenhouse gases combined. This corresponds to a change in global temperature of dT = +1.7 °C from CO2 alone and dT = +2.5 °C when taking all greenhouse gases into account.
You might be wondering: Why is this so high? Currently we are at +1.0 °C above pre-industrial, which is far from the +2.5 °C calculated here. Is the calculation wrong? The calculation is correct, but remember that what we are calculating here is the equilibrium temperature we would eventually reach if maintaining this state. We did not look at the changes over time when deriving the formula, we only considered the final steady-state P_incoming = P_thermal. So the temperature calculated via radiative forcing should always be interpreted as the temperature that is “baked in” given that no changes will occur. Staying at 410 ppm CO2 and maintaining the concentrations of the other greenhouse gases as well leads to a temperature change dT = +2.5 °C in the long run. That’s when P_incoming = P_thermal.
Of course, aside from being great for comparison, we can also combine radiative forcings of different effects to calculate a combined effect. We have dI = +3.1 from greenhouse gases, dI = +0.35 from ozone, dI = -0.9 from the build-up of aerosols (high uncertainty) and dI = -0.15 from land use. Adding all leads to a rounded combined effect of dI_total = +2.4 W/m² and a corresponding change in equilibrium temperature from anywhere between dT = +1.4 °C to dT = +2.4 °C compared to pre-industrial times, with the best guess being dT = +1.9 °C.
Note that since each of the radiative forcings has its own uncertainty, the possible range for changes in global temperature is actually larger. Best case we have dI = +2.6 from greenhouse gases, +0.1 from ozone, -1.9 from aerosols and -0.3 from land use, which leads to dI _total = +0.5 W/m² and the range dT = +0.3 °C to dT = +0.5 °C. Worst case we have dI = +3.6 from greenhouse gases, +0.5 from ozone, -0.1 from aerosols and -0.1 from land use, then we get dI _total = +3.9 W/m² and the range dT = +2.3 °C to dT = +3.9 °C. So taking into account all these individual uncertainties, the range that covers all conceivable outcomes goes from dT = +0.3 °C to dT = +3.9 °C. Though thankfully uncertainties usually cancel out to a large degree when adding many variables, the more variables included the better, so our initial dT = +1.4 °C to dT = +2.4 °C is highly likely to include the correct equilibrium temperature.
The loss of arctic sea-ice, which has been accelerating in recent decades and is now happening at a rate faster than predicted by almost all climate models, can also be incorporated with a proper radiative forcing. A recent calculation puts it at around dI = +0.7 W/m², thus adding another dT = +0.6 °C on top if the trend continues.
With these basics, you should be able to find this document by the IPCC a much more enjoyable read. An updated and in-depth look at radiative forcing of aerosols can be found here. Remember, radiative forcing just tells you how strong an effect is in terms of turning the intensity of the sun up or down by a bit. A useful basis for comparison and rule-of-thumb prediction of global temperature.
An added technical afterthought you may or may not find interesting: Radiative forcing does not just inform us about the value of the equilibrium temperature, but also about the rate of change in temperature (in °C per year or decade). Adding the heat dE to a body changes its temperature by c*m*dT with c being the specific heat capacity and m the mass. Using the power P = dE/dt with which heat is added we get: P = c*m*dT/dt or dT/dt = P/(c*m). If not in equilibrium, the power is P = P_incoming-P_thermal, so:
dT/dt = (I_incoming*C – k*S*T_current^4)/(c*m)
In equilibrium we have: I_incoming*C = k*S*T_equilibrium^4. This leads to:
dT/dt = n*(T_equilibrium^4 – T_current^4)
With the constant n = k*S/(c*m). Rewriting this as:
dT/dt = n*((T_pre+dT)^4 – (T_pre+dT_current)^4)
And using a binomial expansion assuming dT << T_pre and dT_current << T_pre:
With the constant m = 4*T_pre^3*n. Using reference data dT_current = 1 °C, dT = 2 °C and dT/dt = 0.2 °C per decade in recent times, we get the rough estimate m = (0.2 °C per decade) per (°C gap to equilibrium temperature). The brackets are only here to aid understanding. So given a radiative forcing dI, we can estimate the corresponding change in equilibrium global temperature dT = 0.8*dI and combine this with the current excess in global temperature dT_current to estimate the rate of change in temperature dT/dt = 0.2*(dT-dT_current) in °C per decade. Naturally, once dT_current = dT, the equilibrium state is reached and the rate of change dT/dt becomes zero. This idea also works works backwards in the sense of measuring the current rate of change as well as the current excess temperature and deducing from this the equilibrium temperature dT and the corresponding total radiative forcing dI.
Here’s as promised the derivation of dT = constant*dI
Using T_0 = 13.6 °C = 287 K and I_0 = 340 W/m² (pre-industrial):
constant = 0.2 °C/(W/m²)
(Note that for changes in temperature, K is the same as °C)
As mentioned, this only holds true for a body with no surface features. The presence of an atmosphere with climate dynamics leads to constant = 0.8 °C/(W/m²)
Ketamin erlebt gerade ein großes Comeback, diesmal nicht auf Parties, sondern vor allem in Laboren und Kliniken. Die nächste Generation antidepressiver Medikamente wird es zwar nicht werden, dafür ist das Sicherheitsprofil nicht gut genug, aber es etabliert sich als eine “Last Line of Defence”. Also angewandt bei Leuten, bei denen a) traditionelle Behandlungsmethoden für Depression versagt haben (CBT, SSRI) und b) es keine Geschichte von Suchtverhalten gibt. Letzteres da Ketamin in klinischer Umgebung zusammen mit Benzos verabreicht wird, um die Gefahr schwerer Angstzustände aufgrund der dissoziativen Wirkung von Ketamin zu dämpfen, und Benzos bekannt dafür sind, sehr schnell zu einer starken Abhängigkeit zu führen.
Die Datenlage für Ketamin ist noch recht überschaubar, aber sehr vielversprechend. Ich beziehe mich hier auf die Meta-Analyse “A systematic review and meta-analysis of the efficacy of intravenous ketamine infusion for treatment resistant depression: January 2009 – January 2019” von Walter S. Marcantoni. Ich habe die Daten dieser Meta-Analyse mal durch mein Programm Autobias gejagt, um zu sehen, wie es in diesem Fall um den Publikationsbias steht und ob sich auch nach Korrektur noch eine gute Effektstärke zeigt. Wie man am ersten Output sehen kann, umfassen die kontrollierten Experimente (Behandlungs- versus Placebogruppe) zu Ketamin bisher knapp 350 Probanten, im Mittel 50 Probanten pro Experiment. Die Heterogenität (Uneinigkeit) der Experimente bzgl. Effektstärke ist relativ gering.
Insgesamt ergibt sich eine antidepressive Wirkung der Stärke (Cohen’s) d = 0.75 oberhalb des Placebo-Effekts, mit einem 95 % Konfidenzintervall von d = 0.51 bis d = 1.00. Die Nullhypothese kann mit sehr hoher Sicherheit abgelehnt werden (p < 0.001).
Bleibt das auch bestehen, wenn man die kleinsten Experimente verwirft? Tendenziell gilt die Regel: Je umfangreicher das Experiment, desto näher liegt die gefundene Effektstärke an der wahren Effektstärke. Es lohnt sich also, die Meta-Analyse unter Beschränkung auf die größten Experimente zu wiederholen. Hier bei Beschränkung auf die fünf größten Experimente:
Es ergibt sich eine Reduktion auf d = 0.61 oberhalb des Placebo-Effekts, mit einem verschobenen 95 % KI von d = 0.37 bis d = 0.85. Die größten Experimente implizieren eine etwas kleinere Effektstärke, jedoch ist die Reduktion a) nicht als signifikant zu werten und b) gefährdet nicht die Ablehnung der Nullhypothese. Den schwachen Publikationsbias sieht man auch an der Asymmetrie des Funnel-Plots, mit zwei klaren Ausreißern in Richtung stärkerer Effekt.
Für eine numerische Auswertung der Asymmetrien sind jedoch zu wenige Datenpunkte vorhanden. Am zeitlichen Plot kann man schön das steigende Interesse an Ketamin erkennen. Mit Ausnahme des Ausreißers von 2006 scheint das Publikationsjahr keinen nennenswerten Einfluss auf die Effektstärke zu haben.
Insgesamt hält der Effekt einer strengen Prüfung auf Publikationsbias sehr gut stand. Laut der Meta-Studie gibt es auch keine besonderen Auffälligkeiten beim Bias einzelner Studien (z.B. bezüglich Selektion oder Blinding). Man darf also guten Gewissens davon ausgehen, dass die festgestellte antidepressive Wirkung einem realen Effekt entspricht. In der Stärke sogar gut vergleichbar mit SSRI.
Hier ging es strikt um Experimente, bei denen Ketamin intravenös verabreicht wurde. Andere Experimente zeigen aber, dass die antidepressive Wirkung auch bei der Verabreichung über ein Nasenspray funktioniert. In den USA ist eine solches Nasenspray schon verfügbar, hergestellt von Johnson & Johnson, jedoch mit einem deftigen Preisschild von um die $ 400 pro Dosis versehen. Nicht nur die Nebenwirkungen, sondern auch der Preis zeigt, dass es bei Ketamin eher um klinische Interventionen in Extremfällen geht.
Letzteres ist aber sehr nützlich, da SSRI a) vier bis sechs Wochen brauchen um die volle Wirkung zu entfalten und b) in den ersten zwei Wochen suizidale Ideation sogar verstärken. Denkbar ungeeignet für Interventionen, bei denen schnell eine Wirkung erzielt werden soll. Ketamin könnte also tatsächlich eine wichtige Lücke füllen.
Von einer Selbstbehandlung mit Ketamin mit Bezug des Ketamins über einen Dealer ist definitiv abzuraten. Ohne medizinische Überwachung und gleichzeitiger Verabreichung sedierender Mittel, die gut in Kombination mit Ketamin funktionieren, ist die Gefahr von starken Angstreaktionen / Panikattacken inakzeptabel hoch. Mal abgesehen davon, dass es Methoden der Selbstbehandlung gibt, die in Meta-Analysen ähnlich vielversprechende Effektstärken zeigen, ohne die Gefahr solcher Reaktionen zu bergen: Fitness, Mindfulness, Lichttherapie.
Über die letzten Wochen habe ich an einer App zur automatischen Ermittlung, Visualisierung und Korrektur von Publikationsbias in Meta-Analysen gearbeitet und denke, dass ich es bei der jetzigen (zufriedenstellenden) Version belassen werde. Das Programm beginnt mit dem Input der Daten der kontrollierten Experimente (RCTs). Diese können direkt aus der Meta-Studie entnommen werden. Da Meta-Studien die RCT-Daten oft unterschiedlich präsentieren, habe ich vier Modi zum Input bereitgestellt. Wenn die Meta-Studie die Effektstärken und Grenzen der jeweiligen 95 % Konfidenzintervalle berichtet, bieten sich die ersten beiden Input-Modi an:
Input-Modus 1: Input als drei separate Listen. Liste der Effektstärken d = [0.30, 0.42, 0.08], Liste der unteren Grenzen dlow = [-0.20, 0.04, -0.48], Liste der oberen Grenzen dhigh = [0.50, 0.80, 0.54].
Input-Modus 2: Input als eine Liste der Abfolge d, dlow, dhigh. Zum Beispiel: l = [0.30, -0.20, 0.50, 0.42, 0.04, 0.80, 0.08, -0.48, 0.54].
Sind statt der Grenzen die Standardfehler oder Varianzen gegeben, was ziemlich oft der Fall ist, kann man die anderen beiden anderen Input-Modi nutzen. Die Grenzen des 95 % KI werden dann automatisch vor der Analyse berechnet.
Input-Modus 3: Input als eine Liste der Abfolge d, SE. Zum Beispiel: lse = [0.30, 0.18, 0.42, 0.25, 0.08, 0.24]
Input-Modus 3: Input als eine Liste der Abfolge d, Var. Zum Beispiel: lv = [0.30, 0.03, 0.42, 0.05, 0.08, 0.04]
Eine bestimmte Reihenfolge muss dabei nicht eingehalten werden. Notwendige Sortierungen werden automatisch gemacht. Da ein Teil der Ermittlung und Korrektur des Publikationsbias darauf basiert, eine Neuberechnung der Meta-Analyse mit Beschränkung auf die Top k RCTs vorzunehmen, muss dieser Wert k als Input gegeben werden. Top k RCTs meint hier die Anzahl k RCTs mit dem geringsten Standardfehler (höchste Probantenzahlen).
Mit der Variable fixed_mode = 1 lässt sich eine Meta-Analyse nach dem Fixed-Effects-Model erzwingen. Standardmäßig ist fixed_mode = 0 und es erfolgt eine Analyse nach dem Random-Effects-Model. Ein letzter möglicher Input ist die Aktivierung des Comparison Mode, darauf gehe ich aber später ein.
Zuerst rechnet das Programm die gesamte Meta-Analyse nach, beginnend mit der Berechnung von Cochrane’s Q, der Heterogenität I² und der Zwischen-Studien-Varianz Tau² sowie einem Histogramm der Effektstärken.
Danach werden Charakteristiken der einzelnen RCTs berechnet und angezeigt. Dazu gehören die Gewichte, mit denen die jeweiligen RCTs in die Meta-Analyse einfließen, sowie die jeweiligen Probantenzahlen, mittlere Probantenzahl pro RCT und gesamte Probantenzahl der RCTs. Das gefolgt von einem Histogramm der Probantenzahlen.
Zum Schluss die Meta-Analyse (nach Borenstein) und die Resultate: Varianz des Effekts, Standardfehler des Effekts, Effektstärke inklusive 95 % Konfidenzintervall, p-Wert der Differenz zum Nulleffekt und H0C als Maß für die Sicherheit der Ablehnung der Nullhypothese.
Dann beginnt der eigentliche Job: Publikationsbias ermitteln und wenn nötig korrigieren. Teil I basiert auf dem Prinzip der Konvergenz zum wahren Effekt. Man nimmt an, dass je größer die Studie, desto näher liegt der gefundene Effekt am wahren Effekt. Die Meta-Analyse wird also nochmals berechnet mit Beschränkung auf die k RCTs mit dem geringsten Standardfehler. Das Programm sortiert die Inputs, kürzt sie und berechnet die Gewichte neu. Tau² und der Standardfehler des Effekts wird explizit nicht neu berechnet. Das hat sehr gute Gründe (siehe Anmerkungen).
Das Programm zeigt dann das Resultat im gleichen Format an und wertet die Differenz zur kompletten Meta-Analyse. Es wird angenommen, dass jegliche Verschiebung der Effektstärke infolge des Publikationsbias geschieht. Es wird gewertet, ob der Einfluss des Publikationsbias auf die Effektstärke signifikant ist (und bei welchem p-Niveau) und ob die Effekt-Verschiebung die Sicherheit bei der Ablehnung der Nullhypothese maßgeblich berührt. Danch wird noch ein Plot der Unterschiede generiert. Für die Analyse des Funnel Plots in Teil II des Programms wird angenommen, dass die hier gefundene Effektstärke die wahre Effektstärke ist.
In Teil II wird versucht, Asymmetrien des Funnel Plots zu quantifizieren und somit eine ergänzende Einschätzung zum Publikationsbias zu liefern. Alle Effekstärken werden zuerst auf die in Teil I gefundene Effektstärke zentriert. Dann wird der Plot der Effekte oberhalb 0 gemacht, die Regressionsgerade berechnet, der Plot der Effekte unterhalb 0 generiert, wieder die Regressionsgerade berechnet und schlussendlich der gesamte Funnel Plot inklusive der Geraden gezeigt.
Jetzt werden die Asymmetrien berechnet:
Asymmetrie der Steigung der Geraden
Asymmetrie der Anzahl RCTs
Asymmetrie der Anzahl Ausreißer
Asymmetrie der Summe der Distanzen zur Mittellinie
Asymmetrie der maximalen Abweichungen zur Mittellinie
Zu jeder Asymmetrie wird eine Korrektur vorgenommen, die wildes Verhalten für Meta-Studien mit einer kleinen Anzahl RCTs verhindern soll (und somit eventuellen Trugschlüssen vorbeugt), die durch die Asymmetrie implizierte Wahrscheinlichkeit zur Publikation unerwünschter RCT-Ausgänge geschätzt und die Signifikanz gewertet.
Krönender Abschluss ist dann die Zusammenfassung dieser Asymmetrie-Merkmale zu einer Schätzung für die Wahrscheinlichkeit der Publikation unerwünschter RCT-Ausgänge (ohne Publikationsbias 100 %) und einer abschließenden Wertung der Signifikanz der Asymmetrien.
Man sieht, dass die gesamte Analyse auf zwei wohletablierten Prinzipien fußt:
Konvergenz der größten Studien zum wahren Effekt
Asymmetrien des Funnel-Plots
Teil I widmet sich dem ersten Punkt, Teil II dem zweiten. Weicht das Mittel der größten RCTs vom Mittel der kleinsten RCTs (bzw. dem Mittel aller RCTs) ab, dann ist das ein deutlicher Hinweis darauf, dass Publikationsbias vorliegt. Die Verschiebung der Effektstärke gibt Auskunft über das Maß des Publikationsbias. Der Blick auf den Funnel Plot wird dies bei signifikanter Verschiebung bestätigen. Die Asymmetrie auf viele verschiedene Arten zu quantifizieren schützt vor Trugschlüssen infolge bestimmter Eigenheiten oder Ausreißern. Man sieht am obigen Beispiel, dass eine reine Zählung der RCTs den Publikationsbias in diesem Fall nicht offenbart hätte, andere Indikatoren schlagen hingegen deutlich an.
Was ist H0C? Nichts anderes als der zum Unsicherheitsintervall gehörige Z-Wert, jedoch a) als Absolutwert und b) so skaliert, dass H0C >= 1 eine sichere Ablehnung der Nullhypothese bedeutet
Es gilt: H0C = abs(0.85*Effektstärke/(1.96*Standardfehler))
Was machen die Asymmetrie-Korrekturen beim Funnel-Plot? Eine sehr kleine Anzahl an RCTs kann zu enormen prozentualen Differenzen führen, welche nicht notwendigerweise enormen Publikationsbias reflektieren. Je kleiner die Anzahl RCTs, desto stärker dämpft das Programm die prozentualen Unterschiede, bevor sie in weitere Berechnungen einfließen
Ist die Wahrscheinlichkeit zur Publikation unerwünschter Resultate genau? Jein. Die Asymmetrie des Funnel Plots impliziert, dass auf der schwächeren Hälfte etwas fehlt. Es lässt sich grob ermitteln (Trim-And-Fill), wieviel man hinzufügen müsste, um den Plot bezüglich dem gegebenen Indikator symmetrisch zu machen. Daraus wiederrum lässt sich diese Wahrscheinlichkeit schätzen. Es bleibt aber ein Schätzwert. Durch die Mittellung über mehrere Asymmetrie-Indikatoren ist er immerhin genauer als die Schätzung basierend auf einem Indikator
Wieso wird bei der Beschränkung auf die Top k RCTs der Wert für Tau² und das 95 % KI nicht neuberechnet? Die Erklärung dazu ist leider etwas sperrig. Es gibt bestimmte Aspekte der Meta-Analyse, die ein typisches Verhalten mit der Änderung der Anzahl RCTs zeigen. Die Beschränkung auf wenige RCTs wird in fast allen Fällen die Zwischen-Studien-Varianz massiv reduzieren, so dass I² und Tau² Null wird. Somit ergibt sich eine Fixed-Effects Analyse mit unrealistisch engem Unsicherheitsintervall. Großes Problem! Es macht mehr Sinn, und ist auch viel konservativer, stattdessen die Unsicherheit der gesamten Meta-Analyse zu übernehmen und nur die Effektstärke anzupassen
Update 24. März 2021:
Ich habe vier zusätzliche Input-Modi hinzugefügt, welche erlauben, die Effektstärken auch mittels dem Odds-Ratio OR oder dem Korrelationskoeffizienten r einzugeben. Das ist vor allem für medizinische Meta-Studien nützlich, da dort gerne mit dem OR gearbeitet wird. Der Output der Ergebnisse erfolgt neben der Effektstärke als Cohen’s d jetzt stets auch in Form des OR und r.
Ich habe auch eine Sensitivity-Analyse hinzugefügt, ein Standard bei Meta-Analysen. Die Meta-Analyse wird wiederholt nachgerechnet, jeweils unter Entfernung eines einzigen Experiments. Dies erlaubt zu sehen, wie stark ein bestimmtes Experiment das Gesamtergebnis beeinflusst. Die Sensitivity-Analyse erfolgt einmal für die gesamte Meta-Analyse (alle RCTs) und einmal für die auf die Top k RCTs beschränkte Analyse, letztere auch wieder mit einem verschobenem statt neuberechnetem 95 % KI.
Update 25. März 2021:
Optional kann man jetzt über die Variable year das Erscheinungsjahr der jeweiligen RCTs eingeben. Es folgt dann eine Visualisierung der Veröffentlichungen mit der Zeit und Test auf Abhängigkeit der gefundenen Effektstärken von Erscheinungsjahr. Letzterer Test ist häufig in Meta-Analysen zu finden. Für eine leere Liste year = [ ] wird dieser Abschnitt übersprungen.
Optional kann man jetzt über die Variable ind_bias den RCTs Gewichte für individuellen Bias zuordnen. Bei einem Eintrag 1 in der Liste ind_bias erfolgen keine Änderungen, bei einem Eintrag > 1 wird der Standardfehler der RCT um eben jenen Faktor erhöht. Dadurch erhält dieses RCT ein geringeres Gewicht in der Meta-Analyse. Will man z.B. bei insgesamt 5 RCTs die letzten beiden eingetragenen RCTs wegen hohem Bias-Risiko schwächer gewichten, so könnte man z.B. ind_bias = [1,1,1,1.33,1.33] setzen. Für eine leere Liste ind_bias = [ ] wird keine Anpassung vorgenommen.
Neben dem Funnel-Plot wird jetzt auch der theoretische Funnel-Plot angezeigt. Er zeigt die Regressionslinien, die man bei Abwesenheit von Publikationsbias für normalverteilte Effektstärken erhält, wenn die Anzahl RCTs gegen unendlich geht.
Einführung einer Reihe von Checks, um gängige Inputfehler zu erkennen und wenn möglich zu übergehen. Ansonsten eine saubere Beendigung des Programms.
Bekannte Fehler:
Die Interpolation beim Funnel-Plot bzw. Jahresplot erzeugt manchmal die Fehlermeldung “RuntimeWarning: invalid value encountered in power kernel_value”. Bisher bin ich noch nicht dahinter gekommen, aber die Interpolation funktioniert trotzdem und das Programm läuft ohne Probleme weiter.
Der Code:
Der aktuelle Code (25. März), geschrieben in Python 3.9. Zum Ausführen benötigt man a) einen Python-kompatiblen Compiler, b) die Installation von Python und c) die Installation aller verwendeten Module (Matplotlib, Scipy, etc …)
#%%
import matplotlib.pyplot as plt
import math
import scipy.stats
import numpy as np
import pandas as pd
import statsmodels.api as sm
from prettytable import PrettyTable
import sys
# Number to restrict
k_test = 3
# specify year and individual bias, if available, otherwise leave empty
# ind_bias = 1 -> no individual bias, ind_bias > 1 -> higher individual bias
ind_bias = [1,1,1,1,1.33,1.33,1.33]
year = [2018,2018,2013,2011,2013,2018,2006]
# input modes
# 1 = pre-formatted / 2 = d, dlow, dhigh, ... / 3 = d, se, ... / 4 = d, var, ...
# 5 = pre-formatted OR / 6 = OR, ORlow, ORhigh, ...
# 7 = pre-formatted r / 8 = r, rlow, rhigh, ...
mode = 1
if mode > 0.5 and mode < 1.5:
d = [0.43,0.60,0.61,0.66,0.80,1.19,1.43]
dlow = [-0.01,0.03,0.10,0.00,0.31,0.53,0.71]
dhigh = [0.86,1.17,1.12,1.31,1.30,1.84,2.15]
if mode > 1.5 and mode < 2.5:
l = [-0.82,-1.55,-0.09,-0.94,-1.59,-0.29,-0.65,-1.24,-0.06,-0.93,-1.45,-0.41,-0.85,-1.29,-0.41,-0.90,-1.45,-0.35,-1.13,-1.72,-0.54,-1.07,-1.51,-0.63,-0.93,-1.48,-0.38,-0.61,-1.23,0.01]
d = []
dlow = []
dhigh = []
i = 0
while i < len(l):
d.append(l[i])
i += 1
dlow.append(l[i])
i += 1
dhigh.append(l[i])
i += 1
if mode > 2.5 and mode < 3.5:
lse = [-1.39,0.34,-0.35,0.37,-1.06,0.51,-1.76,0.44,-0.86,0.28,-0.59,0.29]
d = []
dlow = []
dhigh = []
i = 0
while i < len(lse):
d.append(lse[i])
davg = lse[i]
i += 1
low = davg-1.96*lse[i]
dlow.append(low)
high = davg+1.96*lse[i]
dhigh.append(high)
i += 1
dlow_new = [round(x, 3) for x in dlow]
dhigh_new = [round(x, 3) for x in dhigh]
if mode > 3.5 and mode < 4.5:
lv = [0.1, 0.06, 0.8, 0.01, -0.2, 0.04]
lse = []
i = 0
while i < len(lv):
lse.append(lv[i])
i += 1
se = math.sqrt(lv[i])
lse.append(se)
i += 1
d =[]
dlow =[]
dhigh = []
i = 0
while i < len(lse):
d.append(lse[i])
davg = lse[i]
i += 1
low = davg-1.96*lse[i]
dlow.append(low)
high = davg+1.96*lse[i]
dhigh.append(high)
i += 1
lse_new = [round(x, 3) for x in lse]
dlow_new = [round(x, 3) for x in dlow]
dhigh_new = [round(x, 3) for x in dhigh]
if mode > 4.5 and mode < 5.5:
OR = [1.22, 1.65, 1.82]
ORlow = [0.93, 1.02, 1.33]
ORhigh = [1.92, 2.11, 2.67]
d = []
i = 0
while i < len(OR):
d_temp = math.log(OR[i])*0.5513
d.append(d_temp)
i += 1
dlow = []
i = 0
while i < len(OR):
dlow_temp = math.log(ORlow[i])*0.5513
dlow.append(dlow_temp)
i += 1
dhigh = []
i = 0
while i < len(OR):
dhigh_temp = math.log(ORhigh[i])*0.5513
dhigh.append(dhigh_temp)
i += 1
if mode > 5.5 and mode < 6.5:
ORl = [1.20,0.40,3.30,0.99,0.80,1.22,0.93,0.78,1.19,1.08,0.63,1.85,0.44,0.16,1.24,2.61,1.10,6.17,1.00,0.76,1.32,0.32,0.16,0.62,1.06,0.51,2.20,0.89,0.23,3.47,1.05,0.77,1.33,0.47,0.28,0.79,1.12,0.98,1.30,0.93,0.79,1.11]
d = []
dlow = []
dhigh = []
i = 0
while i < len(ORl):
temp = math.log(ORl[i])*0.5513
d.append(temp)
i += 1
temp = math.log(ORl[i])*0.5513
dlow.append(temp)
i += 1
temp = math.log(ORl[i])*0.5513
dhigh.append(temp)
i += 1
if mode > 6.5 and mode < 7.5:
r = [0.55,0.35,0.38]
rlow = [0.22,0.16,0.12]
rhigh = [0.72,0.58,0.67]
d = []
i = 0
while i < len(r):
d_temp = 2*r[i]/math.sqrt(1-r[i]**2)
d.append(d_temp)
i += 1
dlow = []
i = 0
while i < len(r):
dlow_temp = 2*rlow[i]/math.sqrt(1-rlow[i]**2)
dlow.append(dlow_temp)
i += 1
dhigh = []
i = 0
while i < len(r):
dhigh_temp = 2*rhigh[i]/math.sqrt(1-rhigh[i]**2)
dhigh.append(dhigh_temp)
i += 1
if mode > 7.5 and mode < 8.5:
rl = [0.55,0.22,0.72,0.35,0.16,0.58,0.38,0.12,0.67]
d = []
dlow = []
dhigh = []
i = 0
while i < len(rl):
temp = 2*rl[i]/math.sqrt(1-rl[i]**2)
d.append(temp)
i += 1
temp = 2*rl[i]/math.sqrt(1-rl[i]**2)
dlow.append(temp)
i += 1
temp = 2*rl[i]/math.sqrt(1-rl[i]**2)
dhigh.append(temp)
i += 1
print('RCT Inputs:')
print()
print('Effect Sizes d:')
print(d)
print()
print('Lower Limits of 95 % CI:')
print(dlow)
print()
print('Upper Limits of 95 % CI:')
print(dhigh)
print()
print()
# Fixed-Effects Mode: 1 = activated, 0 = deactivated
fixed_mode = 0
# k_test check to prevent error
if k_test > len(d):
k_test = len(d)
print('+++ Number of RCTs for restricted analysis greater than number of RCTs')
print('+++ Number of RCTs for restricted analysis set to number of RCTs')
print()
print()
# k_test check to prevent error
if k_test < 1:
k_test = 3
print('+++ Number of RCTs for restricted analysis smaller than one')
print('+++ Number of RCTs for restricted analysis set to three')
print()
print()
# ind_bias check to prevent error
if len(ind_bias) > len(d) or len(ind_bias) < len(d):
ind_bias = []
print('+++ Specified bias list not equal in size to effect size list')
print('+++ Specified bias list emptied')
print()
print()
# year check to prevent error
if len(year) > len(d) or len(year) < len(d):
year = []
print('+++ Year list not equal in size to effect size list')
print('+++ Year list emptied')
print()
print()
# lower limit check to prevent error
if len(dlow) > len(d) or len(dlow) < len(d):
print('+++ Lower limit list not equal in size to effect size list')
print('+++ Terminating Program')
print()
print()
sys.exit()
# upper limit check to prevent error
if len(dhigh) > len(d) or len(dhigh) < len(d):
print('+++ Upper limit list not equal in size to effect size list')
print('+++ Terminating Program')
print()
print()
sys.exit()
# adjustment for individual bias
if len(ind_bias) > 0:
i = 0
while i < len(d):
se_here = (abs(dhigh[i]-dlow[i])/3.92)
se_adj = ind_bias[i]*se_here
dlow[i] = d[i]-1.96*se_adj
dhigh[i] = d[i]+1.96*se_adj
i += 1
formatted_dlow = [ round(elem, 2) for elem in dlow ]
formatted_dhigh = [ round(elem, 2) for elem in dhigh ]
print('Individual Bias Adjusted RCT Results:')
print()
print('Effect Sizes d:')
print(d)
print()
print('Lower Limits of 95 % CI:')
print(formatted_dlow)
print()
print('Upper Limits of 95 % CI:')
print(formatted_dhigh)
print()
print()
print('------------------------------------')
print(u'\u2022'u'\u2022'u'\u2022'' RANDOM-EFFECTS META-ANALYSIS 'u'\u2022'u'\u2022'u'\u2022')
print('------------------------------------')
print()
def w(x, y):
w = 1/((abs(x-y)/3.92)**2)
return w
wsum = 0
i = 0
while i < len(d):
wsum = wsum + w(dlow[i], dhigh[i])
i += 1
q1sum = 0
i = 0
while i < len(d):
q1sum = q1sum + w(dlow[i], dhigh[i])*d[i]**2
i += 1
q2sum = 0
i = 0
while i < len(d):
q2sum = q2sum + w(dlow[i], dhigh[i])*d[i]
i += 1
Q = q1sum - (q2sum**2)/wsum
c1sum = 0
i = 0
while i < len(d):
c1sum = c1sum + w(dlow[i], dhigh[i])**2
i += 1
C = wsum - c1sum/wsum
df = len(d) - 1
tau_squared_prelim = (Q-df)/C
if tau_squared_prelim < 0:
tau_squared = 0
else:
tau_squared = tau_squared_prelim
if fixed_mode > 0:
tau_squared = 0
I_squared_prelim = 100*(Q-df)/Q
if I_squared_prelim < 0:
I_squared = 0
else:
I_squared = I_squared_prelim
if fixed_mode > 0:
I_squared = 0
Q = 0
print('(Forcing Fixed-Effects Analysis)')
print()
# General Information
print('Cochranes Q:', "%.2f" % Q)
print('Heterogeneity I_Squared:', "%.2f" % I_squared, '%')
print('Tau_Squared:', "%.2f" % tau_squared)
print()
print('Histogram of Effect Sizes:')
print()
plt.hist(d, density=False, bins=len(d), ec='black')
plt.ylabel('Count')
plt.xlabel('Effect Size')
plt.show()
print()
v = 1/wsum
n_total = 4/v
n_avg = n_total/len(d)
# random-effects meta-analysis
def g(x, y):
g = 1/((abs(x-y)/3.92)**2+tau_squared)
return g
gsum = 0
i = 0
while i < len(d):
gsum = gsum + g(dlow[i], dhigh[i])
i += 1
v = 1/gsum
se = math.sqrt(v)
print('RCT Weights and Imputed Sample Size:')
print()
t1 = PrettyTable(['Effect Size', 'Standard Error', 'Weight Share (%)', 'Sample Size'])
nhisto = []
i = 0
while i < len(d):
gprint = g(dlow[i], dhigh[i])
gshare = 100*gprint/gsum
wprint = w(dlow[i], dhigh[i])
vprint = 1/wprint
nprint = round(4/vprint,0)
nhisto.append(nprint)
dprint = d[i]
seprint = abs(dlow[i]-dhigh[i])/3.92
t1.add_row(["%+.2f" % dprint,"%.2f" % seprint,"%.1f" % gshare,"%.0f" % nprint])
i += 1
print(t1)
print()
print('Average Imputed Sample Size:', "%.0f" % n_avg)
print('Total Imputed Sample Size:', "%.0f" % n_total)
print()
print('Histogram of Sample Sizes:')
print()
plt.hist(nhisto, density=False, bins=len(nhisto),ec='black')
plt.ylabel('Count')
plt.xlabel('Sample Size')
plt.show()
print()
print('Variance of Weighted Effect:', "%.3f" % v)
print('Standard Error of Weighted Effect:', "%.3f" % se)
print()
# calculation of final results
dsum = 0
i = 0
while i < len(d):
dsum = dsum + g(dlow[i], dhigh[i])*d[i]
i += 1
davg = dsum/gsum
dlower = davg - 1.96*se
dupper = davg + 1.96*se
z = abs(davg/se)
p = scipy.stats.norm.sf(z)
c = abs(davg/(1.96*se)*0.85)
print('Weighted Effect with 95 % CI and One-Tailed p-Value:')
print()
print('--->>> d =', "%+.3f" % davg, '[', "%+.3f" % dlower, ',', "%+.3f" % dupper, '] / p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print()
OR = math.exp(davg*1.8138)
ORlower = math.exp(dlower*1.8138)
ORupper = math.exp(dupper*1.8138)
print('--->>> OR =', "%.3f" % OR, '[', "%.3f" % ORlower, ',', "%.3f" % ORupper, '] and p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print()
r = davg/math.sqrt(davg**2+4)
rlower = dlower/math.sqrt(dlower**2+4)
rupper = dupper/math.sqrt(dupper**2+4)
print('--->>> r =', "%+.3f" % r, '[', "%+.3f" % rlower, ',', "%+.3f" % rupper, '] and p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print()
# ------ Random-Effects Meta-Analysis Restricted to Largest RCTs ------
davg_uncorrected = davg
dlower_uncorrected = dlower
dupper_uncorrected = dupper
se_uncorrected = se
print()
print()
se_critical = 0.12
print('-----------------------------------------------------------')
print(u'\u2022'u'\u2022'u'\u2022'' RANDOM-EFFECTS META-ANALYSIS RESTRICTED TO TOP RCTs 'u'\u2022'u'\u2022'u'\u2022')
print('-----------------------------------------------------------')
print()
# ordered list creation
dtemp = list(d)
dlowtemp = list(dlow)
dhightemp = list(dhigh)
sort = []
sortlow = []
sorthigh = []
u = 1
while u < (k_test+1):
se_min = 100
i_min = 0
i = 0
while i < len(dtemp):
se_test = abs(dhightemp[i]-dlowtemp[i])/3.92
if se_test < se_min:
i_min = i
se_min = se_test
i += 1
sort.append(dtemp[i_min])
sortlow.append(dlowtemp[i_min])
sorthigh.append(dhightemp[i_min])
dtemp.pop(i_min)
dlowtemp.pop(i_min)
dhightemp.pop(i_min)
u +=1
print('Top RCTs Effect Size, SE and Imputed Sample Size:')
print()
t2 = PrettyTable(['Effect Size', 'Standard Error', 'Weight Share (%)', 'Sample Size'])
gsum = 0
i = 0
while i < k_test:
gsum = gsum + g(sortlow[i], sorthigh[i])
i += 1
i = 0
while i < k_test:
se_test = abs(sorthigh[i]-sortlow[i])/3.92
gprint = g(sortlow[i], sorthigh[i])
gshare = 100*gprint/gsum
wprint = w(sortlow[i], sorthigh[i])
vprint = 1/wprint
nprint = 4/vprint
t2.add_row(["%+.2f" % sort[i], "%.2f" % se_test, "%.1f" % gshare, "%.0f" % nprint])
i += 1
print(t2)
print()
d_original = list(d)
dlow_original = list(dlow)
dhigh_original = list(dhigh)
d = list(sort)
dlow = list(sortlow)
dhigh = list(sorthigh)
# Bias Testing
v = 1/gsum
se = math.sqrt(v)
dsum = 0
i = 0
while i < k_test:
dsum = dsum + g(dlow[i], dhigh[i])*d[i]
i += 1
davg = dsum/gsum
d_test = davg
dlower = davg - 1.96*se_uncorrected
dupper = davg + 1.96*se_uncorrected
z = abs(davg/se_uncorrected)
p = scipy.stats.norm.sf(z)
c = abs(davg/(1.96*se_uncorrected)*0.85)
print('Top Analysis with Shifted 95 % CI:')
print()
print('--->>> d =', "%+.3f" % davg, '[', "%+.3f" % dlower, ',', "%+.3f" % dupper, '] and p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print()
OR = math.exp(davg*1.8138)
ORlower = math.exp(dlower*1.8138)
ORupper = math.exp(dupper*1.8138)
print('--->>> OR =', "%.3f" % OR, '[', "%.3f" % ORlower, ',', "%.3f" % ORupper, '] and p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print()
r = davg/math.sqrt(davg**2+4)
rlower = dlower/math.sqrt(dlower**2+4)
rupper = dupper/math.sqrt(dupper**2+4)
print('--->>> r =', "%+.3f" % r, '[', "%+.3f" % rlower, ',', "%+.3f" % rupper, '] and p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print()
z_bias = abs((davg_uncorrected-davg)/se_critical)
p_bias = scipy.stats.norm.sf(z_bias)
print()
print('Difference to Calculated Effect: d =', "%.3f" % davg_uncorrected, '/ Z =', "%.3f" % z_bias, '/ p =', "%.3f" % p_bias)
davg_corrected = davg
print()
if p_bias >= 0.1:
print('--->>> Influence of Publication Bias on Effect Size is NOT SIGNIFICANT')
if p_bias < 0.1 and p_bias >= 0.05:
print('--->>> Influence of Publication Bias on Effect Size APPROACHES SIGNIFICANCE')
if p_bias < 0.05 and p_bias >= 0.01:
print('--->>> Influence of Publication Bias on Effect Size is SIGNIFICANT AT p < 0.05')
if p_bias < 0.01 and p_bias >= 0.001:
print('--->>> Influence of Publication Bias on Effect Size is SIGNIFICANT AT p < 0.01')
if p_bias < 0.001:
print('--->>> Influence of Publication Bias on Effect Size is SIGNIFICANT AT p < 0.001')
print()
if c >= 1.1:
print('--->>> Influence of Publication Bias on H0 Rejection is NOT CRITICAL')
if c < 1.1 and c >= 1.0:
print('--->>> Influence of Publication Bias on H0 Rejection APPROACHES CRITICALITY')
if c < 1.0 and c >= 0.9:
print('--->>> Influence of Publication Bias on H0 Rejection is CRITICAL')
if c < 0.9 and c >= 0.8:
print('--->>> Influence of Publication Bias on H0 Rejection is HIGHLY CRITICAL')
if c < 0.8:
print('--->>> Influence of Publication Bias on H0 Rejection is SEVERE')
print()
means = [davg_uncorrected, davg]
ci = [(dlower_uncorrected, dupper_uncorrected), (dlower, dupper)]
y_r = [means[i] - ci[i][1] for i in range(len(ci))]
plt.bar(range(len(means)), means, yerr=y_r, align='center', error_kw=dict(lw=2, capsize=5, capthick=2))
plt.xticks(range(len(means)), ['Original Effect','Corrected Effect'])
x = np.linspace(-0.5, len(means)-0.5)
y = 0*x
plt.plot(x, y, 'black', linewidth=0.5)
plt.show()
d = list(d_original)
dlow = list(dlow_original)
dhigh = list(dhigh_original)
print()
print()
print()
print('------------------------------------------------------------------------')
print(u'\u2022'u'\u2022'u'\u2022'' FUNNEL PLOT (D-SE) ANALYSIS CENTERED ON TOP ANALYSIS EFFECT SIZE 'u'\u2022'u'\u2022'u'\u2022')
print('------------------------------------------------------------------------')
print()
j = 0
epos = []
xpos = []
while j < len(d):
if d[j]-d_test >= 0:
epos.append(d[j]-d_test)
xpos.append(abs(dhigh[j]-dlow[j])/3.92)
j += 1
if len(epos) > 0:
t3 = PrettyTable(['Standard Error', 'Centered Effect Size'])
j = 0
while j < len(epos):
t3.add_row(["%+.2f" % xpos[j], "%+.2f" % epos[j]])
j += 1
print(t3)
xpos_max = 0
j = 0
while j < len(epos):
if xpos[j] > xpos_max:
xpos_max = xpos[j]
j += 1
productsum = 0
xsquaresum = 0
j = 0
while j < len(epos):
productsum = productsum + xpos[j]*epos[j]
xsquaresum = xsquaresum + xpos[j]**2
j += 1
slope_pos = productsum/xsquaresum
print()
print('Above Effect Funnel Plot:')
print()
plt.scatter(xpos, epos)
plt.title("Above Effect Funnel Plot")
plt.xlabel("Standard Error")
plt.ylabel("Centered Effect Size")
plt.xlim(0, xpos_max+0.05)
x = np.linspace(0, xpos_max+0.05)
y = slope_pos*x
plt.plot(x, y)
plt.show()
print()
print('---> Above Test Effect Zero Intercept SLOPE: ' "%+.3f" % slope_pos)
print()
print()
else:
print()
print('UNABLE TO CALCULATE Above Test Effect Regression Line')
print()
j = 0
eneg = []
xneg = []
while j < len(d):
if d[j]-d_test <= 0:
eneg.append(d[j]-d_test)
xneg.append(abs(dhigh[j]-dlow[j])/3.92)
j += 1
if len(eneg) > 0:
t4 = PrettyTable(['Standard Error', 'Centered Effect Size'])
j = 0
while j < len(eneg):
t4.add_row(["%+.2f" % xneg[j], "%+.2f" % eneg[j]])
j += 1
print(t4)
productsum = 0
xsquaresum = 0
j = 0
while j < len(eneg):
productsum = productsum + xneg[j]*eneg[j]
xsquaresum = xsquaresum + xneg[j]**2
j += 1
slope_neg = productsum/xsquaresum
xneg_max = 0
j = 0
while j < len(eneg):
if xneg[j] > xneg_max:
xneg_max = xneg[j]
j += 1
print()
print('Below Effect Funnel Plot:')
print()
plt.scatter(xneg, eneg)
plt.title("Above Effect Funnel Plot")
plt.xlabel("Standard Error")
plt.ylabel("Centered Effect Size")
plt.xlim(0, xneg_max+0.05)
x = np.linspace(0, xneg_max+0.05)
y = slope_neg*x
plt.plot(x, y)
plt.show()
print()
print('---> Below Test Effect Zero Intercept SLOPE: ' "%+.3f" % slope_neg)
print()
print()
print('Complete Funnel Plot:')
print()
x = xneg+xpos
e = eneg+epos
if xneg_max > xpos_max:
xmax = xneg_max
else:
xmax = xpos_max
plt.scatter(x, e)
plt.title("Funnel Plot")
plt.xlabel("Standard Error")
plt.ylabel("Centered Effect Size")
plt.xlim(0, xmax+0.05)
x = np.linspace(0, xmax+0.05)
y = slope_pos*x
plt.plot(x, y)
x = np.linspace(0, xmax+0.05)
y = slope_neg*x
plt.plot(x, y)
x = np.linspace(0, xmax+0.05)
y = 0*x
plt.plot(x, y,'black', linewidth=0.5)
plt.show()
print()
x = xneg+xpos
e = eneg+epos
print()
print('Comparison to Theoretical Funnel Plot Regression Lines:')
print()
plt.scatter(x, e)
plt.title("Theoretical Funnel Plot")
plt.xlabel("Standard Error")
plt.ylabel("Centered Effect Size")
plt.xlim(0, xmax+0.05)
x = np.linspace(0, xmax+0.05)
y = 0.8*x
plt.plot(x, y)
x = np.linspace(0, xmax+0.05)
y = -0.8*x
plt.plot(x, y)
x = np.linspace(0, xmax+0.05)
y = 0*x
plt.plot(x, y, 'black', linewidth=0.5)
plt.show()
from statsmodels.nonparametric.kernel_regression import KernelReg
X = xneg+xpos
Y = eneg+epos
# Combine lists into list of tuples
points = zip(X, Y)
# Sort list of tuples by x-value
points = sorted(points, key=lambda point: point[0])
# Split list of tuples into two list of x values any y values
X, Y = zip(*points)
print()
print()
print('Funnel Plot Interpolation:')
print()
kr = KernelReg(Y,X,'o')
y_pred, y_std = kr.fit(X)
plt.xlim(0, xmax+0.05)
plt.scatter(X,Y, s = 20)
plt.title("Funnel Plot")
plt.xlabel("Standard Error")
plt.ylabel("Centered Effect Size")
x = np.linspace(0, xmax+0.05)
y = 0*x
plt.plot(x, y, 'black', linewidth=0.5)
plt.plot(X, y_pred, color = 'orange')
plt.show()
print()
print('R_Squared =',"%.2f" % kr.r_squared())
print()
else:
print()
print('UNABLE TO CALCULATE Below Test Effect Regression Line')
print()
if len(epos) > 0 and len(eneg) > 0:
if davg_uncorrected > 0:
if abs(slope_neg) > slope_pos:
prob = 100
else:
prob = 100*(0.3*math.exp(-abs(slope_neg))+abs(slope_neg))/(0.3*math.exp(-abs(slope_pos))+slope_pos)
else:
if slope_pos > abs(slope_neg):
prob = 100
else:
prob = 100*(0.3*math.exp(-abs(slope_pos))+slope_pos)/(0.3*math.exp(-abs(slope_neg))+abs(slope_neg))
print()
slope_diff = slope_pos-abs(slope_neg)
print(u'\u2022'' TEST FOR FUNNEL PLOT ASYMMETRIES:')
print()
print()
print('Slopes: ' "%.3f" % slope_pos, 'Above Effect versus', "%.3f" % slope_neg, 'Below Effect')
print('Slope Difference: ' "%.3f" % slope_diff)
print()
print('---> Estimated Probability of Publishing Undesired Result:', "%.0f" % prob, '%')
if prob >= 83:
print('---> Slope Asymmetry Implies INSIGNIFICANT Publication Bias')
if prob < 83 and prob >= 65:
print('---> Slope Asymmetry Implies SLIGHT Publication Bias')
if prob < 65 and prob >= 48:
print('---> Slope Asymmetry Implies MODERATE Publication Bias')
if prob < 48 and prob >= 30:
print('---> Slope Asymmetry Implies STRONG Publication Bias')
if prob < 30:
print('---> Slope Asymmetry Implies SEVERE Publication Bias')
print()
else:
print()
print('UNABLE TO CALCULATE Slope Difference')
print()
if len(epos) > 0 and len(eneg) > 0:
ipos = len(xpos)
ineg = len(xneg)
iref = max(ipos,ineg)
n_diff_raw = 100*(ipos-ineg)/iref
n_diff = 100*(ipos-ineg)/(iref+2)
print()
print('RCT Counts: ' "%.0f" % ipos, 'Above Effect versus', "%.0f" % ineg, 'Below Effect')
print('RCT Count Asymmetry Raw: ' "%+.0f" % n_diff_raw, '%')
print('RCT Count Asymmetry Corrected: ' "%+.0f" % n_diff, '%')
if davg_uncorrected > 0:
if n_diff < 0:
prob1 = 100
else:
prob1 = 100-n_diff
else:
if n_diff > 0:
prob1 = 100
else:
prob1 = 100-abs(n_diff)
print()
print('---> Estimated Probability of Publishing Undesired Result:', "%.0f" % prob1, '%')
if prob1 >= 83:
print('---> RCT Count Asymmetry Implies INSIGNIFICANT Publication Bias')
if prob1 < 83 and prob1 >= 65:
print('---> RCT Count Asymmetry Implies SLIGHT Publication Bias')
if prob1 < 65 and prob1 >= 48:
print('---> RCT Count Asymmetry Implies MODERATE Publication Bias')
if prob1 < 48 and prob1 >= 30:
print('---> RCT Count Asymmetry Implies STRONG Publication Bias')
if prob1 < 30:
print('---> RCT Count Asymmetry Implies SEVERE Publication Bias')
print()
outlierpos = 0
j = 0
while j < len(epos):
if epos[j] > 0.5:
outlierpos = outlierpos + 1
j += 1
outlierneg = 0
j = 0
while j < len(eneg):
if eneg[j] < -0.5:
outlierneg = outlierneg + 1
j += 1
iref = max(outlierpos,outlierneg)
if iref <= 0: iref = 1
outlier_diff_raw = 100*(outlierpos-outlierneg)/iref
outlier_diff = 100*(outlierpos-outlierneg)/(iref+1)
print()
print('RCT Outlier Counts: ' "%.0f" % outlierpos, 'Above Effect versus', "%.0f" % outlierneg, 'Below Effect')
print('Outlier Asymmetry Raw: ' "%+.0f" % outlier_diff_raw, '%')
print('Outlier Asymmetry Corrected: ' "%+.0f" % outlier_diff, '%')
if davg_uncorrected > 0:
if outlier_diff < 0:
prob2 = 100
else:
prob2 = 100-outlier_diff
else:
if outlier_diff > 0:
prob2 = 100
else:
prob2 = 100-abs(outlier_diff)
print()
print('---> Estimated Probability of Publishing Undesired Result:', "%.0f" % prob2, '%')
if prob2 >= 83:
print('---> Outlier Asymmetry Implies INSIGNIFICANT Publication Bias')
if prob2 < 83 and prob2 >= 65:
print('---> Outlier Asymmetry Implies SLIGHT Publication Bias')
if prob2 < 65 and prob2 >= 48:
print('---> Outlier Asymmetry Implies MODERATE Publication Bias')
if prob2 < 48 and prob2 >= 30:
print('---> Outlier Asymmetry Implies STRONG Publication Bias')
if prob2 < 30:
print('---> Outlier Asymmetry Implies SEVERE Publication Bias')
print()
distance_pos = 0
j = 0
while j < len(epos):
distance_pos = distance_pos+epos[j]
j += 1
distance_neg = 0
j = 0
while j < len(eneg):
distance_neg = distance_neg+eneg[j]
j += 1
distance_ref = max(distance_pos,abs(distance_neg))
distance_diff_raw = 100*(distance_pos+distance_neg)/distance_ref
distance_diff = 100*(distance_pos+distance_neg)/(distance_ref+0.4)
print()
print('Effect Distance Sums: ' "%.2f" % distance_pos, 'Above Effect versus', "%.2f" % distance_neg, 'Below Effect')
print('Effect Distance Sum Asymmetry Raw: ' "%+.0f" % distance_diff_raw, '%')
print('Effect Distance Sum Asymmetry Corrected: ' "%+.0f" % distance_diff, '%')
if davg_uncorrected > 0:
if distance_diff < 0:
prob3 = 100
else:
prob3 = 100-abs(distance_diff)
else:
if distance_diff > 0:
prob3 = 100
else:
prob3 = 100-abs(distance_diff)
print()
print('---> Estimated Probability of Publishing Undesired Result:', "%.0f" % prob3, '%')
if prob3 >= 83:
print('---> Effect Distance Sum Asymmetry Implies INSIGNIFICANT Publication Bias')
if prob3 < 83 and prob3 >= 65:
print('---> Effect Distance Sum Asymmetry Implies SLIGHT Publication Bias')
if prob3 < 65 and prob3 >= 48:
print('---> Effect Distance Sum Asymmetry Implies MODERATE Publication Bias')
if prob3 < 48 and prob3 >= 30:
print('---> Effect Distance Sum Asymmetry Implies STRONG Publication Bias')
if prob3 < 30:
print('---> Effect Distance Sum Asymmetry Implies SEVERE Publication Bias')
print()
epos_max = 0
j = 0
while j < len(epos):
if epos[j] > epos_max:
epos_max = epos[j]
j += 1
eneg_max = 0
j = 0
while j < len(eneg):
if eneg[j] < eneg_max:
eneg_max = eneg[j]
j += 1
maxeffect_ref = max(epos_max,abs(eneg_max))
maxeffect_diff_raw = 100*(epos_max+eneg_max)/maxeffect_ref
maxeffect_diff = 100*(epos_max+eneg_max)/(maxeffect_ref+0.1)
print()
print('Effect Ranges: ' "%.2f" % epos_max, 'Above Effect versus', "%.2f" % eneg_max, 'Below Effect')
print('Effect Range Asymmetry Raw: ' "%+.0f" % maxeffect_diff_raw, '%')
print('Effect Range Asymmetry Corrected: ' "%+.0f" % maxeffect_diff, '%')
if davg_uncorrected > 0:
if maxeffect_diff < 0:
prob4 = 100
else:
prob4 = 100-abs(maxeffect_diff)
else:
if maxeffect_diff > 0:
prob4 = 100
else:
prob4 = 100-abs(maxeffect_diff)
print()
print('---> Estimated Probability of Publishing Undesired Result:', "%.0f" % prob4, '%')
if prob4 >= 83:
print('---> Effect Range Asymmetry Implies INSIGNIFICANT Publication Bias')
if prob4 < 83 and prob4 >= 65:
print('---> Effect Range Asymmetry Implies SLIGHT Publication Bias')
if prob4 < 65 and prob4 >= 48:
print('---> Effect Range Asymmetry Implies MODERATE Publication Bias')
if prob4 < 48 and prob4 >= 30:
print('---> Effect Range Asymmetry Implies STRONG Publication Bias')
if prob4 < 30:
print('---> Effect Range Asymmetry Implies SEVERE Publication Bias')
print()
gw = (100/prob)**1.33
gw1 = (100/prob1)**1.33
gw2 = (100/prob2)**1.33
gw3 = (100/prob3)**1.33
gw4 = (100/prob4)**1.33
gwsum = gw + gw1 + gw2 + gw3 + gw4
prob_mean = (gw*prob+gw1*prob1+gw2*prob2+gw3*prob3+gw4*prob4)/gwsum
ugw = (100/prob)
ugw1 = (100/prob1)
ugw2 = (100/prob2)
ugw3 = (100/prob3)
ugw4 = (100/prob4)
ugwsum = ugw + ugw1 + ugw2 + ugw3 + ugw4
uvar = 1/ugwsum
use = 100*math.sqrt(uvar)
prob_lower = prob_mean - 0.75*use
prob_upper = prob_mean + 0.75*use
print()
print(u'\u2022'' COMBINED FUNNEL PLOT ANALYSIS:')
print()
print('--->>> Estimated Probability of Publishing Undesired Result:', "%.0f" % prob_mean, '% [', "%.0f" % prob_lower, '% ,', "%.0f" % prob_upper, '% ]')
if prob_mean >= 83:
print('--->>> Funnel Plot Analysis Implies INSIGNIFICANT Publication Bias')
if prob_mean < 83 and prob_mean >= 65:
print('--->>> Funnel Plot Analysis Implies SLIGHT Publication Bias')
if prob_mean < 65 and prob_mean >= 48:
print('--->>> Funnel Plot Analysis Implies MODERATE Publication Bias')
if prob_mean < 48 and prob_mean >= 30:
print('--->>> Funnel Plot Analysis Implies STRONG Publication Bias')
if prob_mean < 30:
print('--->>> Funnel Plot Analysis Implies SEVERE Publication Bias')
else:
print()
print('UNABLE TO CALCULATE Asymmetries')
print()
print()
print('Imputed Probabilities of Publishing Undesired Results:')
print()
means = [prob, prob1, prob2, prob3, prob4, prob_mean]
ci = [(prob,prob),(prob1,prob1),(prob2,prob2),(prob3,prob3),(prob4,prob4), (prob_lower, prob_upper)]
y_r = [means[i] - ci[i][1] for i in range(len(ci))]
plt.bar(range(len(means)), means, yerr=y_r, align='center', error_kw=dict(lw=2, capsize=5, capthick=2))
plt.xticks(range(len(means)), ['Slopes','Counts', 'Outliers', 'Distances', 'Ranges', 'Combined'])
plt.show()
print()
print()
print()
print('--------------------------------------------------')
print(u'\u2022'u'\u2022'u'\u2022'' SENSITIVITY ANALYSIS OF FULL META-ANALYSIS 'u'\u2022'u'\u2022'u'\u2022')
print('--------------------------------------------------')
print()
dremain = []
dlowerremain = []
dupperremain = []
changesum = 0
changemax = 0
minhoc = 100
n = 0
while n < len(d_original):
d = list(d_original)
dlow = list(dlow_original)
dhigh = list(dhigh_original)
del d[n]
del dlow[n]
del dhigh[n]
wsum = 0
i = 0
while i < len(d):
wsum = wsum + w(dlow[i], dhigh[i])
i += 1
q1sum = 0
i = 0
while i < len(d):
q1sum = q1sum + w(dlow[i], dhigh[i])*d[i]**2
i += 1
q2sum = 0
i = 0
while i < len(d):
q2sum = q2sum + w(dlow[i], dhigh[i])*d[i]
i += 1
Q = q1sum - (q2sum**2)/wsum
c1sum = 0
i = 0
while i < len(d):
c1sum = c1sum + w(dlow[i], dhigh[i])**2
i += 1
C = wsum - c1sum/wsum
df = len(d) - 1
tau_squared_prelim = (Q-df)/C
if tau_squared_prelim < 0:
tau_squared = 0
else:
tau_squared = tau_squared_prelim
if fixed_mode > 0:
tau_squared = 0
I_squared_prelim = 100*(Q-df)/Q
if I_squared_prelim < 0:
I_squared = 0
else:
I_squared = I_squared_prelim
if fixed_mode > 0:
I_squared = 0
Q = 0
# random-effects meta-analysis
gsum = 0
i = 0
while i < len(d):
gsum = gsum + g(dlow[i], dhigh[i])
i += 1
v = 1/gsum
se = math.sqrt(v)
# calculation of final results
dsum = 0
i = 0
while i < len(d):
dsum = dsum + g(dlow[i], dhigh[i])*d[i]
i += 1
davg = dsum/gsum
dremain.append(davg)
dlower = davg - 1.96*se
dupper = davg + 1.96*se
dlowerremain.append(dlower)
dupperremain.append(dupper)
z = abs(davg/se)
p = scipy.stats.norm.sf(z)
c = abs(davg/(1.96*se)*0.85)
if c < minhoc:
minhoc = c
change = 100*(davg-davg_uncorrected)/davg_uncorrected
changesum = changesum + abs(change)
if abs(change) > changemax:
changemax = abs(change)
print('--->>> d =', "%+.3f" % davg, '[', "%+.3f" % dlower, ',', "%+.3f" % dupper, '] / p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print('--->>> Change to Uncorrected Effect:', "%+.1f" % change, '%')
print()
n += 1
print('Plot for Remaining Effect Size after Removing the n-th RCT:')
print()
means = []
labels = []
n = 0
while n < len(dremain):
means.append(dremain[n])
labels.append(n+1)
n += 1
ci = []
n = 0
while n < len(dremain):
ci.append((dlowerremain[n],dupperremain[n]))
n += 1
y_r = [means[i] - ci[i][1] for i in range(len(ci))]
plt.bar(range(len(means)), means, yerr=y_r, align='center', error_kw=dict(lw=2, capsize=5, capthick=2))
plt.xticks(range(len(means)), labels)
plt.axhline(y=davg_uncorrected,linewidth=1, color='red')
x = np.linspace(-1, len(dremain))
y = 0*x
plt.plot(x, y, 'black', linewidth=0.5)
plt.show()
changeavg = changesum/len(dremain)
print()
print('Average Absolute Change:', "%.1f" % changeavg, '%')
print('Maximum Absolute Change:', "%.1f" % changemax, '%')
print()
print('Minimum H0C:', "%.2f" % minhoc)
if k_test > 1:
print()
print()
print()
print('--------------------------------------------------------')
print(u'\u2022'u'\u2022'u'\u2022'' SENSITIVITY ANALYSIS OF RESTRICTED META-ANALYSIS 'u'\u2022'u'\u2022'u'\u2022')
print('--------------------------------------------------------')
print()
dremain = []
dlowerremain = []
dupperremain = []
changesum = 0
changemax = 0
minhoc = 100
n = 0
while n < len(sort):
d = list(sort)
dlow = list(sortlow)
dhigh = list(sorthigh)
del d[n]
del dlow[n]
del dhigh[n]
wsum = 0
i = 0
while i < len(d):
wsum = wsum + w(dlow[i], dhigh[i])
i += 1
q1sum = 0
i = 0
while i < len(d):
q1sum = q1sum + w(dlow[i], dhigh[i])*d[i]**2
i += 1
q2sum = 0
i = 0
while i < len(d):
q2sum = q2sum + w(dlow[i], dhigh[i])*d[i]
i += 1
Q = q1sum - (q2sum**2)/wsum
c1sum = 0
i = 0
while i < len(d):
c1sum = c1sum + w(dlow[i], dhigh[i])**2
i += 1
C = wsum - c1sum/wsum
df = len(d) - 1
if k_test > 2:
tau_squared_prelim = (Q-df)/C
if tau_squared_prelim < 0:
tau_squared = 0
else:
tau_squared = tau_squared_prelim
else:
tau_squared = 0
if fixed_mode > 0:
tau_squared = 0
if k_test > 2:
I_squared_prelim = 100*(Q-df)/Q
if I_squared_prelim < 0:
I_squared = 0
else:
I_squared = I_squared_prelim
else:
I_squared = 0
if fixed_mode > 0:
I_squared = 0
Q = 0
# random-effects meta-analysis
gsum = 0
i = 0
while i < len(d):
gsum = gsum + g(dlow[i], dhigh[i])
i += 1
v = 1/gsum
se = math.sqrt(v)
# calculation of final results
dsum = 0
i = 0
while i < len(d):
dsum = dsum + g(dlow[i], dhigh[i])*d[i]
i += 1
davg = dsum/gsum
dremain.append(davg)
dlower = davg - 1.96*se_uncorrected
dupper = davg + 1.96*se_uncorrected
dlowerremain.append(dlower)
dupperremain.append(dupper)
z = abs(davg/se_uncorrected)
p = scipy.stats.norm.sf(z)
c = abs(davg/(1.96*se_uncorrected)*0.85)
if c < minhoc:
minhoc = c
change = 100*(davg-davg_corrected)/davg_corrected
changesum = changesum + abs(change)
if abs(change) > changemax:
changemax = abs(change)
print('--->>> d =', "%+.3f" % davg, '[', "%+.3f" % dlower, ',', "%+.3f" % dupper, '] / p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print('--->>> Change to Corrected Effect:', "%+.1f" % change, '%')
print()
n += 1
print('Plot for Remaining Effect Size after Removing the n-th RCT:')
print()
means = []
labels = []
n = 0
while n < len(dremain):
means.append(dremain[n])
labels.append(n+1)
n += 1
ci = []
n = 0
while n < len(dremain):
ci.append((dlowerremain[n],dupperremain[n]))
n += 1
y_r = [means[i] - ci[i][1] for i in range(len(ci))]
plt.bar(range(len(means)), means, yerr=y_r, align='center', error_kw=dict(lw=2, capsize=5, capthick=2))
plt.xticks(range(len(means)), labels)
plt.axhline(y=davg_corrected,linewidth=1, color='red')
x = np.linspace(-1, len(dremain))
y = 0*x
plt.plot(x, y, 'black', linewidth=0.5)
plt.show()
changeavg = changesum/len(dremain)
print()
print('Average Absolute Change:', "%.1f" % changeavg, '%')
print('Maximum Absolute Change:', "%.1f" % changemax, '%')
print()
print('Minimum H0C:', "%.2f" % minhoc)
if len(year) > 0:
print()
print()
print()
print('---------------------------')
print(u'\u2022'u'\u2022'u'\u2022'' TIME-SERIES OF RCTS 'u'\u2022'u'\u2022'u'\u2022')
print('---------------------------')
print()
yearmin = 10000
i = 0
while i < len(d_original):
if year[i] < yearmin:
yearmin = year[i]
i += 1
yearmax = 0
i = 0
while i < len(d_original):
if year[i] > yearmax:
yearmax = year[i]
i += 1
print('Earliest RCT:', yearmin)
print('Most Recent RCT:',yearmax)
print()
yearrange = yearmax-yearmin
yearlist = []
i = 0
while i < yearrange+1:
yearlist.append(yearmin+i)
i += 1
numberstudies = []
i = 0
while i < yearrange+1:
number = year.count(yearmin+i)
numberstudies.append(number)
i += 1
print('Number of RCTs Over Time:')
print()
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
ax.bar(yearlist,numberstudies)
plt.show()
X = year
Y = d_original
print()
print('Linear Regression Test of Effect Sizes Over Time:')
model = sm.OLS(Y,sm.add_constant(X))
results = model.fit()
plt.scatter(X,Y, s = 20)
X_plot = np.linspace(yearmin-2,yearmax+2,100)
plt.plot(X_plot, results.params[0] + X_plot*results.params[1], color = 'orange')
print()
plt.show()
print()
print('Slope =', "%+.2f" % results.params[1], '/ p =', "%.3f" % results.pvalues[1])
print('R_Squared =',"%.2f" % results.rsquared)
print()
print('Interpolation of Effect Sizes Over Time:')
print()
from statsmodels.nonparametric.kernel_regression import KernelReg
# Combine lists into list of tuples
points = zip(X, Y)
# Sort list of tuples by x-value
points = sorted(points, key=lambda point: point[0])
# Split list of tuples into two list of x values any y values
X, Y = zip(*points)
kr = KernelReg(Y,X,'o')
y_pred, y_std = kr.fit(X)
plt.xlim(yearmin-2, yearmax+2)
plt.scatter(X,Y, s = 20)
plt.plot(X, y_pred, color = 'orange')
plt.show()
print()
print('R_Squared =',"%.2f" % kr.r_squared())
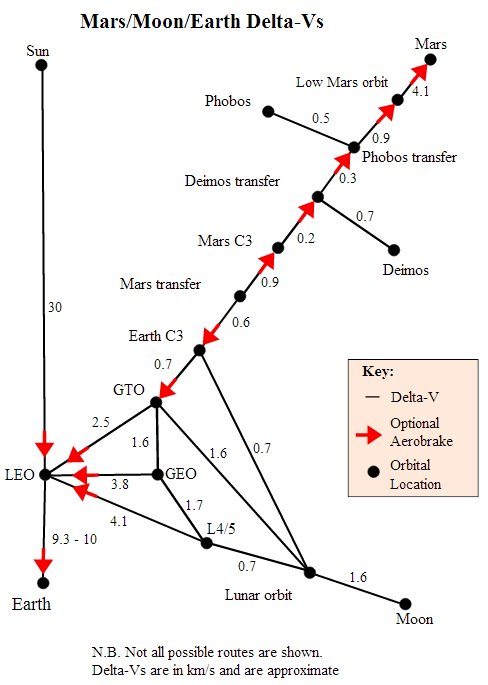
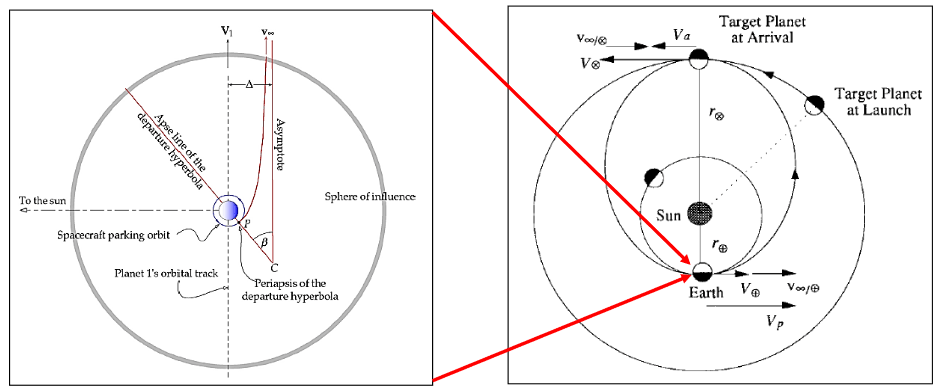
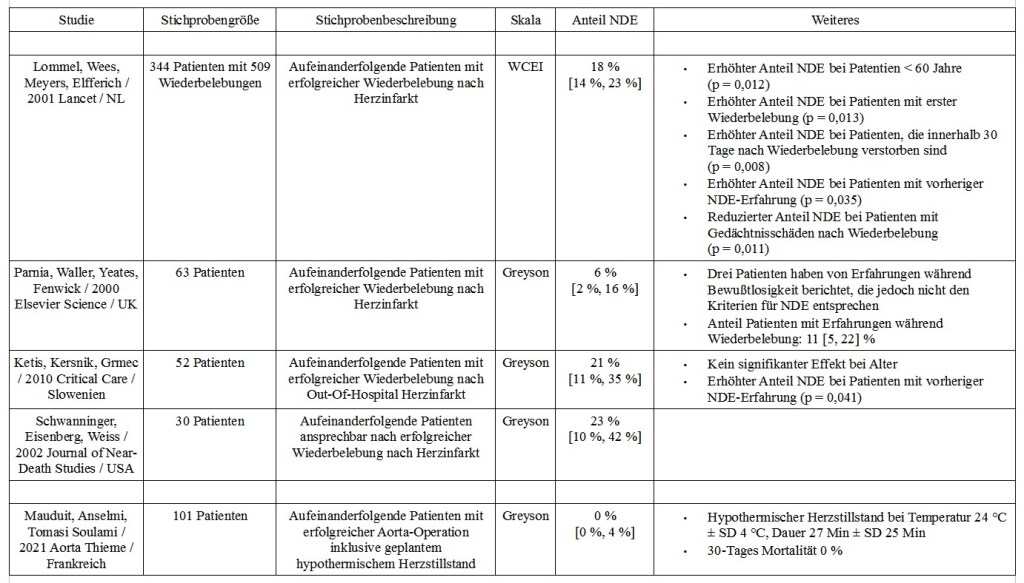
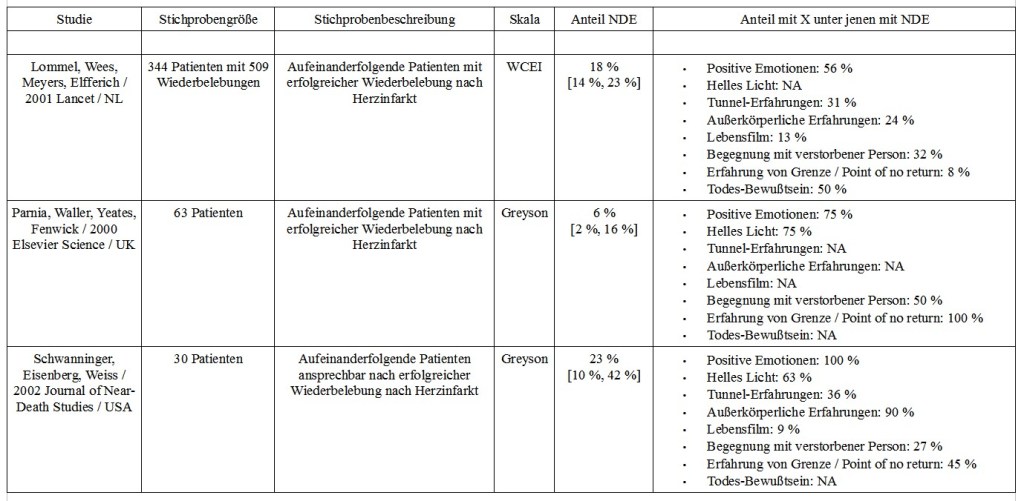
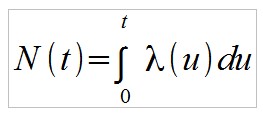
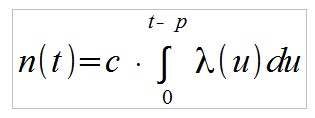
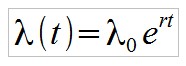
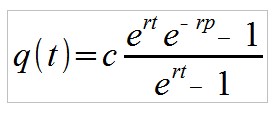
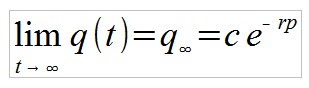
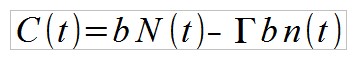
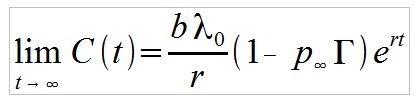

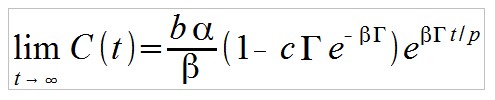
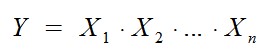
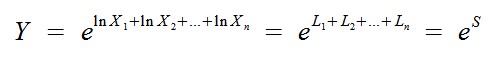
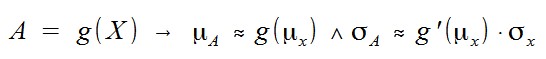
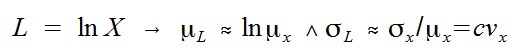
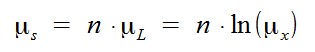
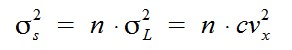
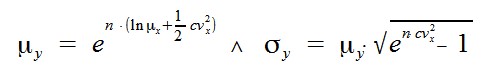
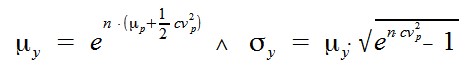
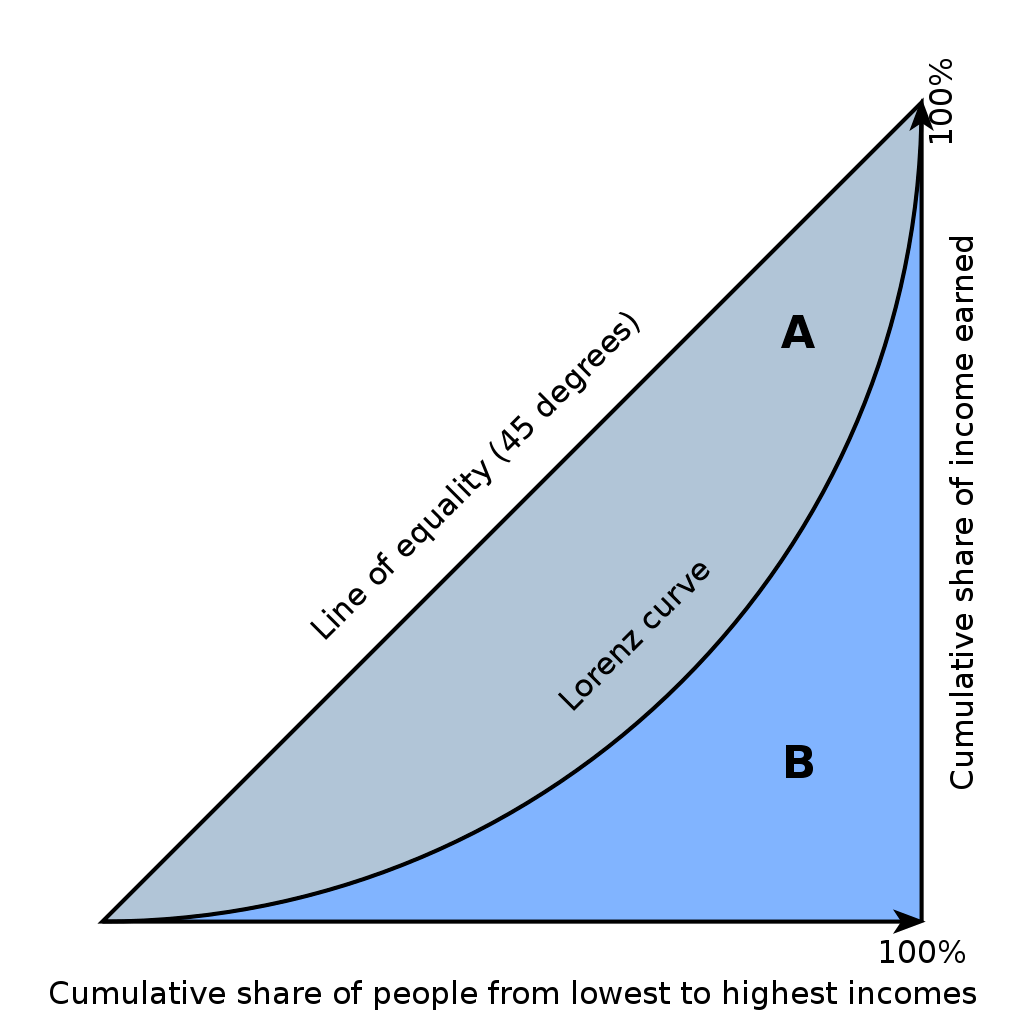
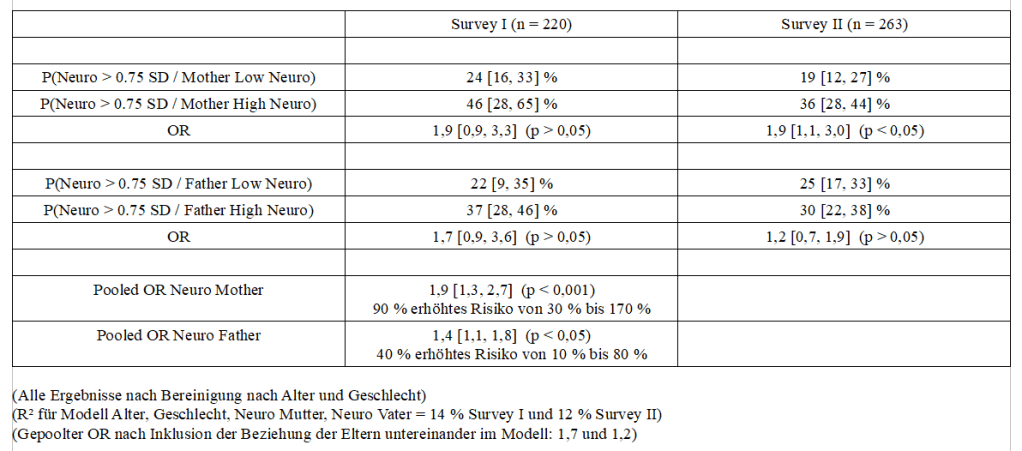
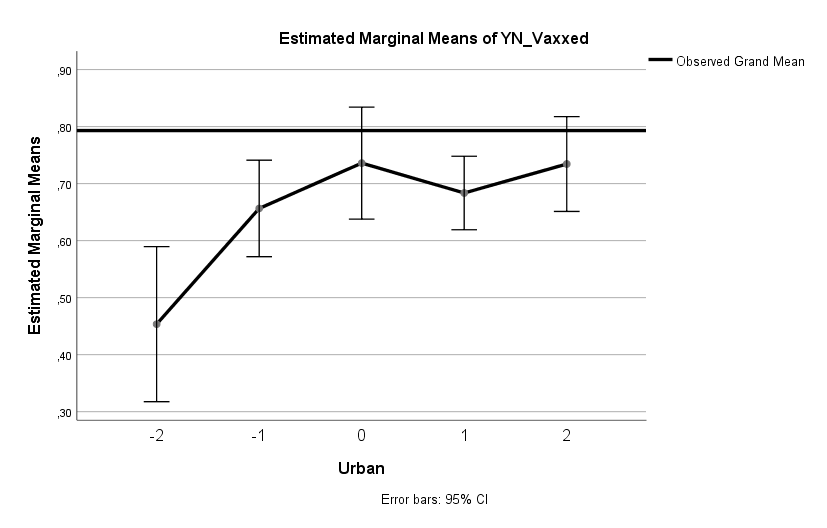
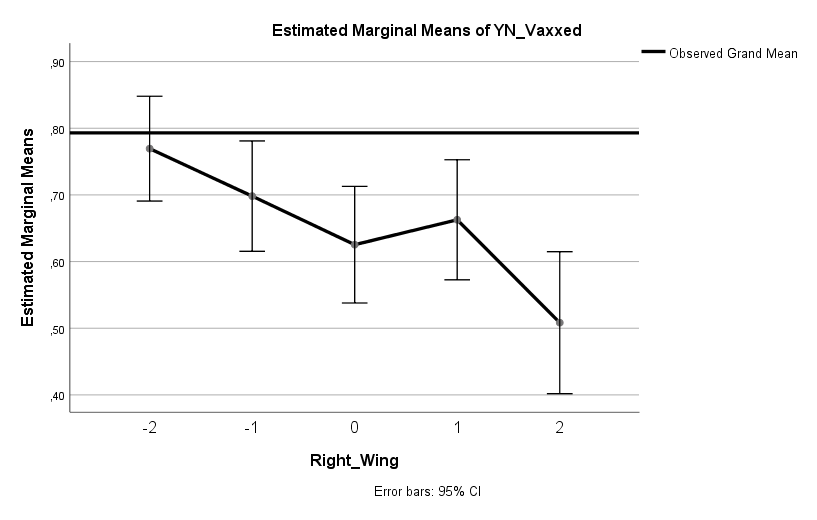
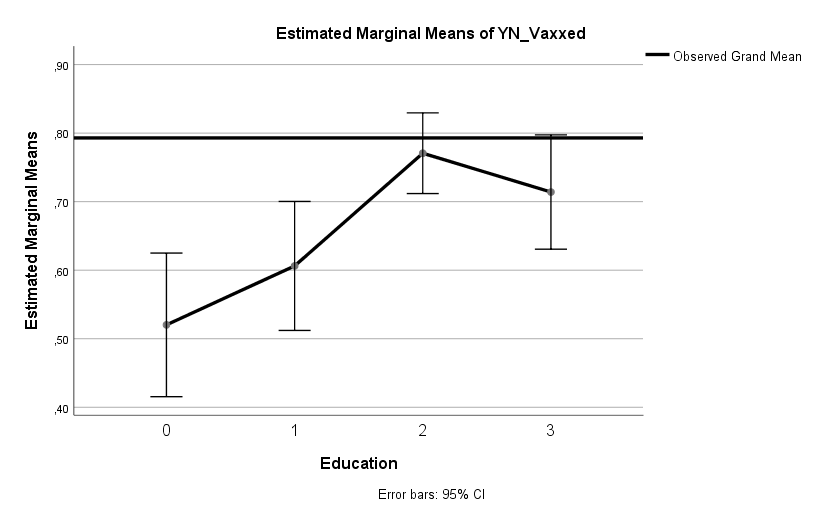

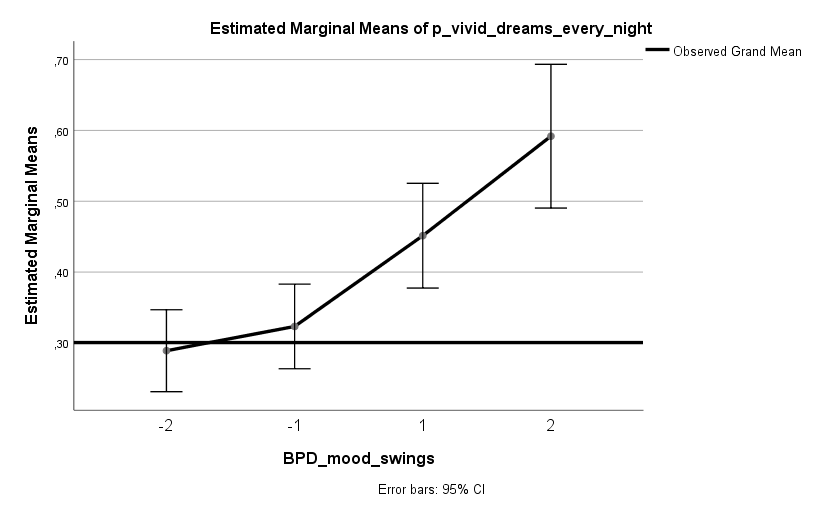
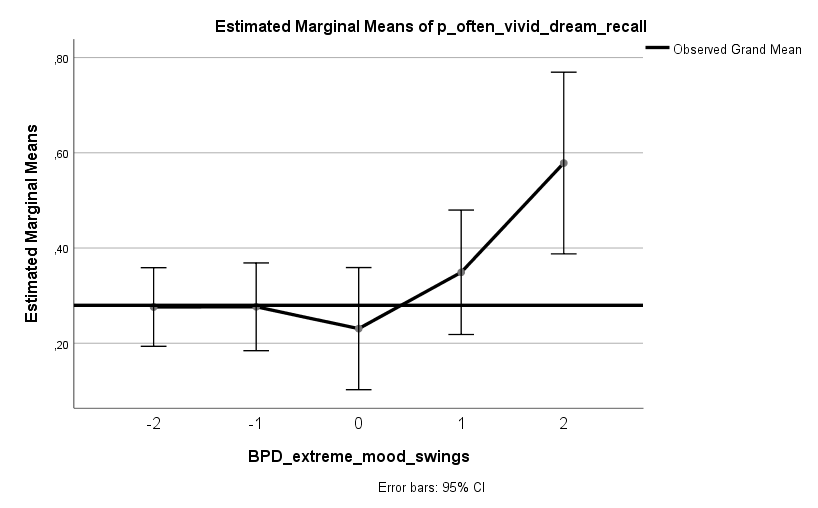
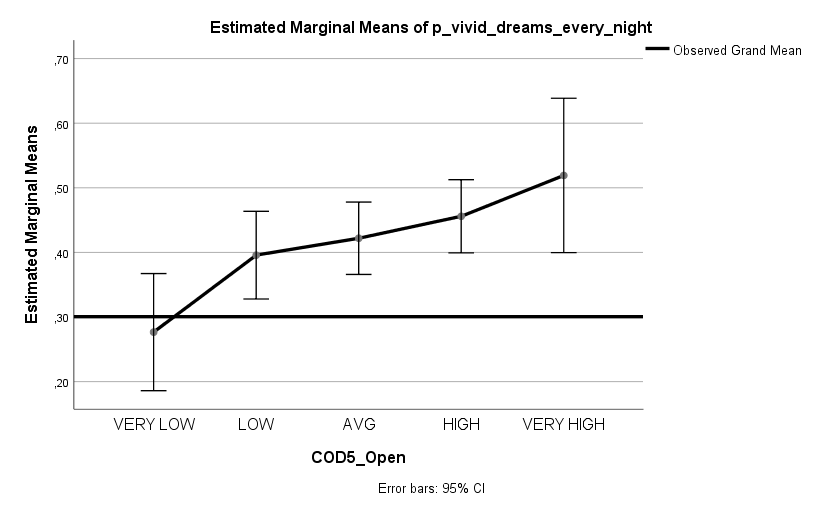
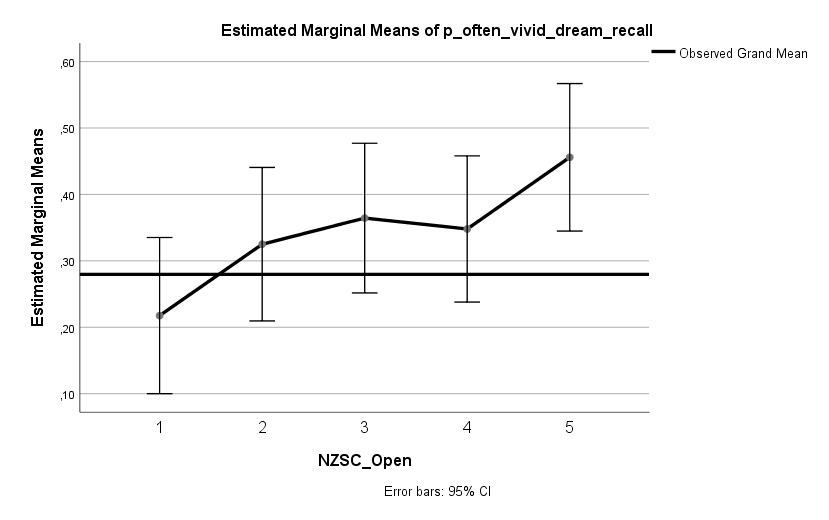
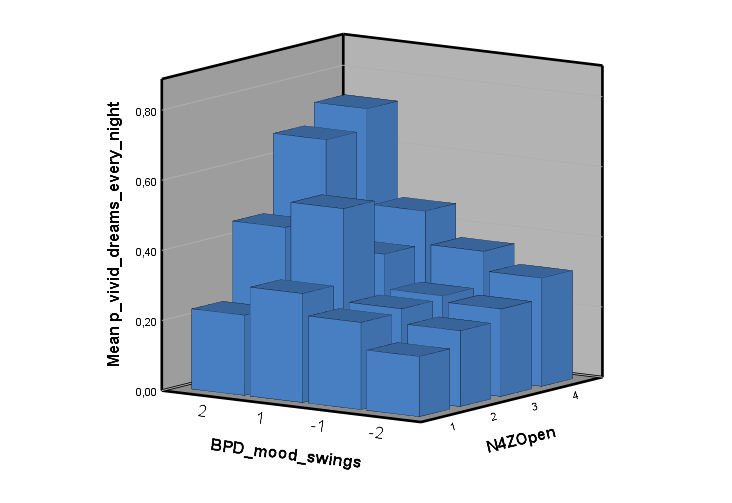
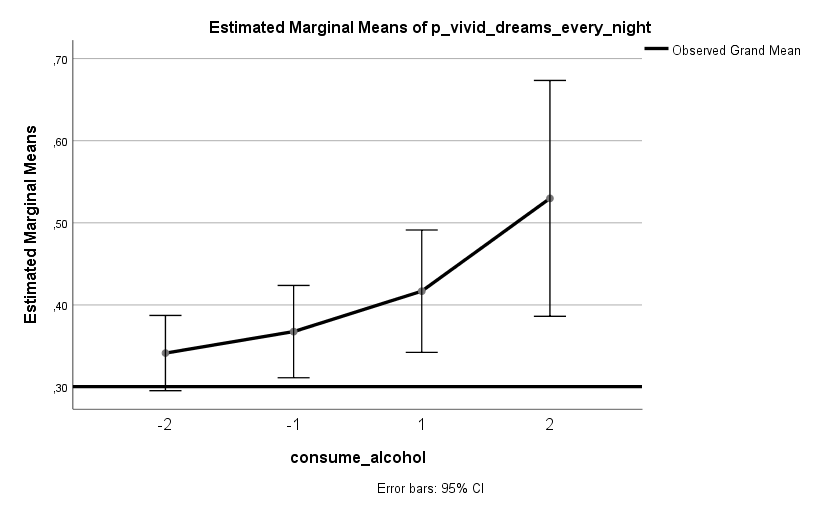
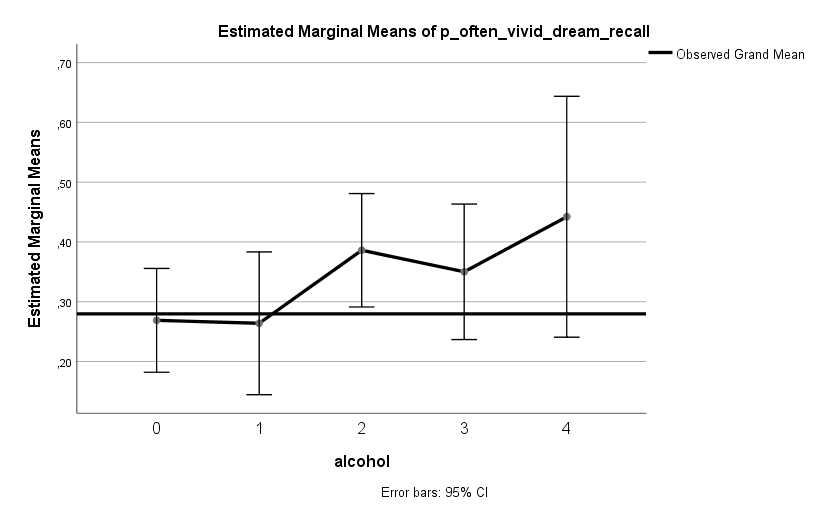
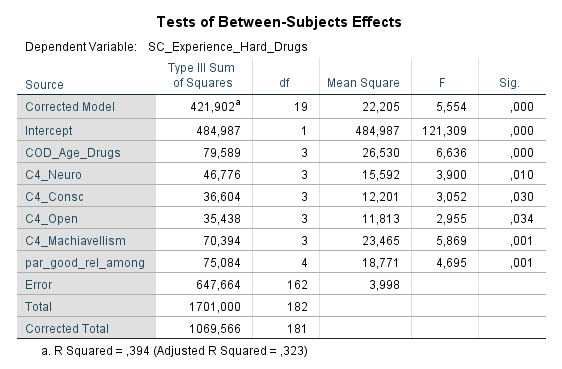
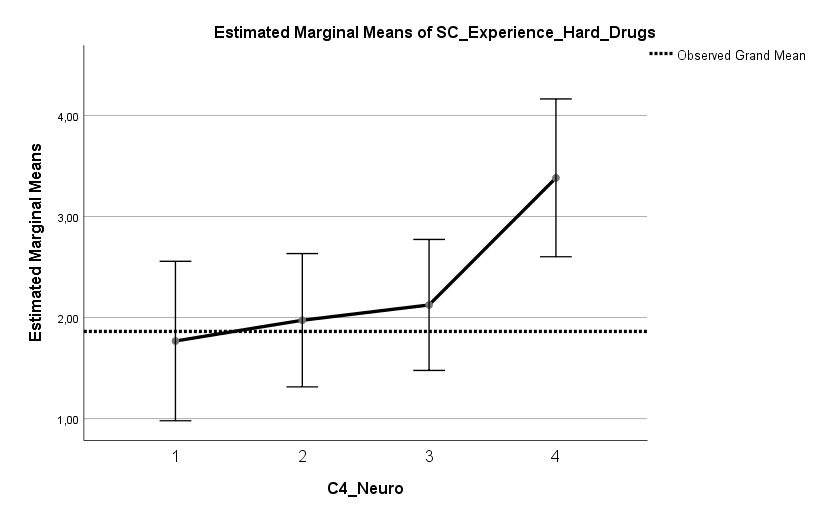
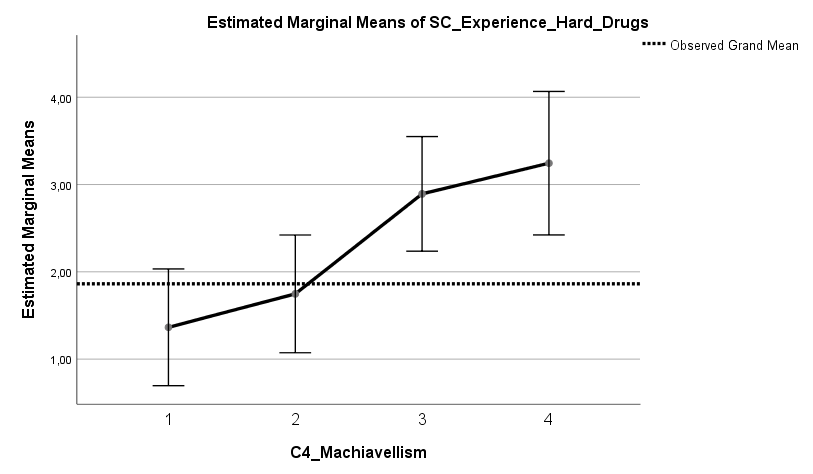
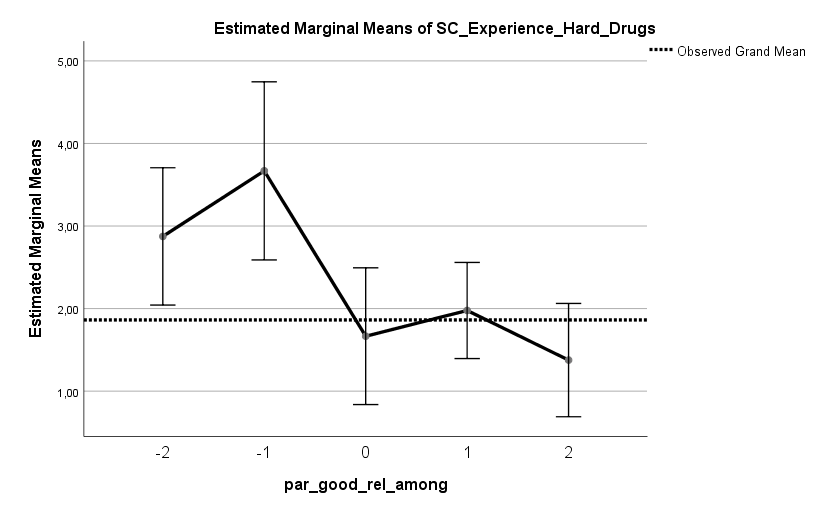
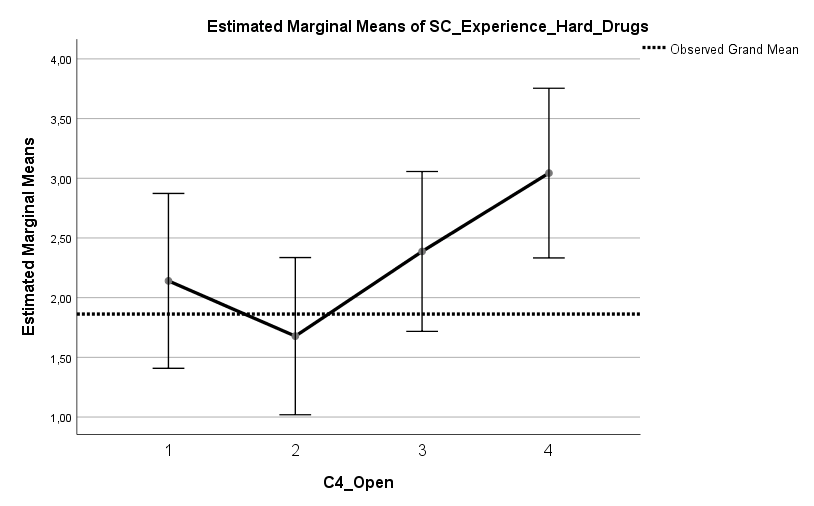
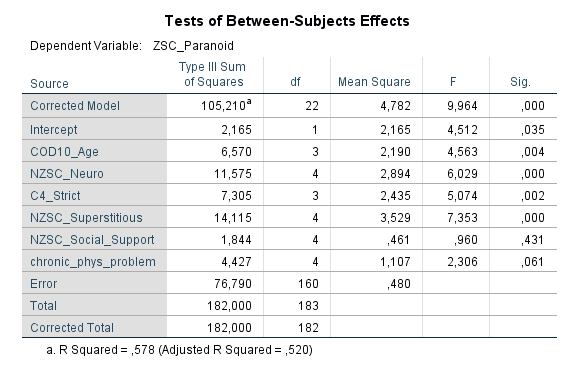
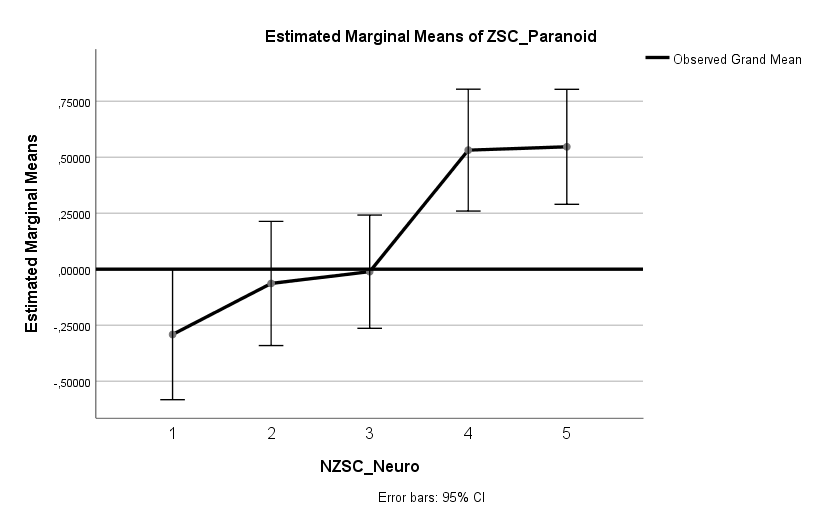
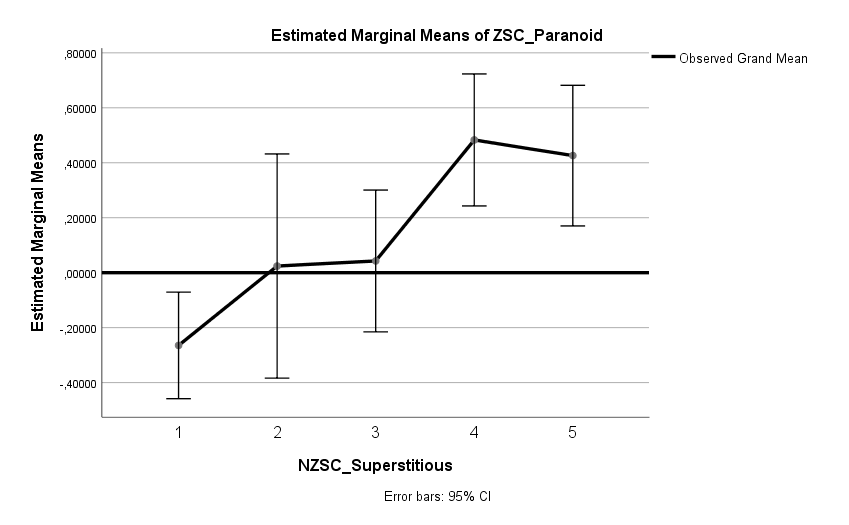
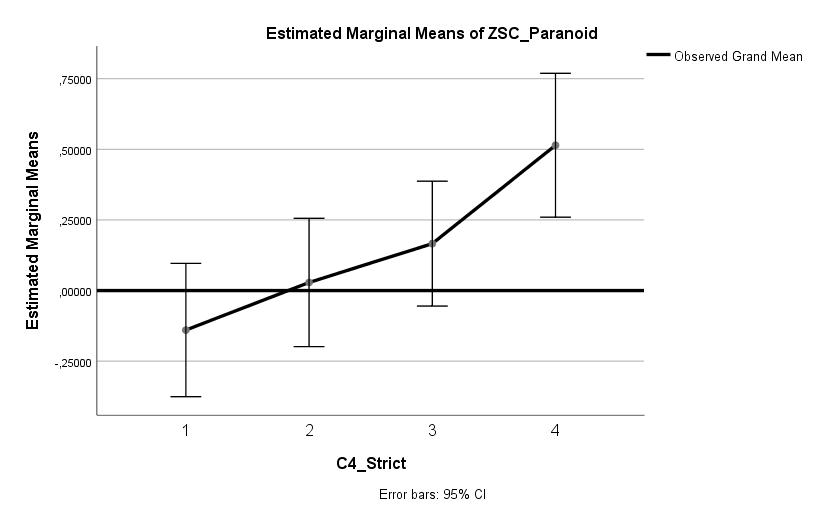
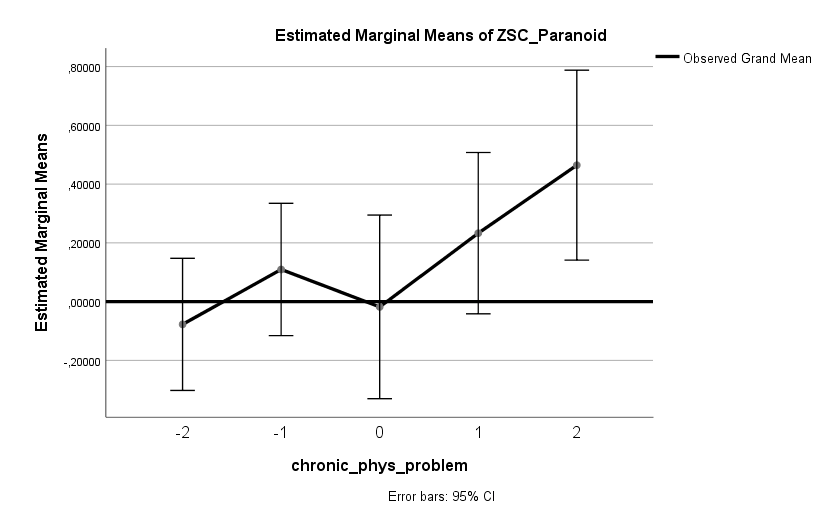
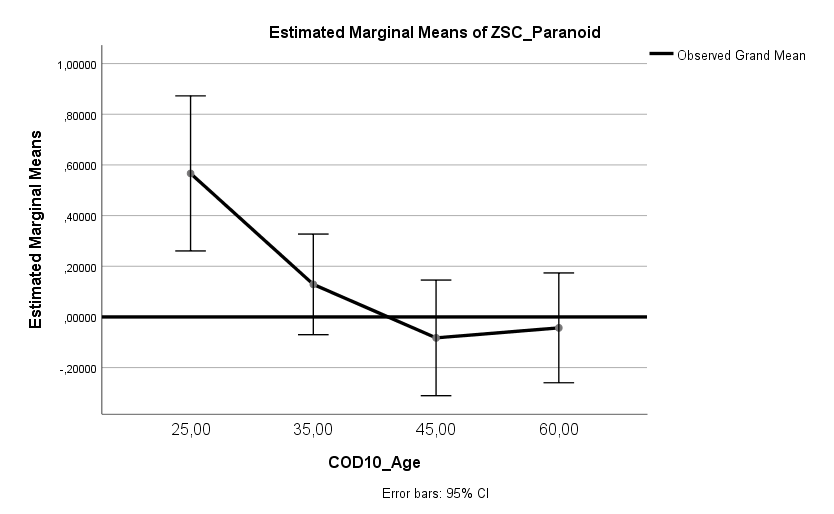
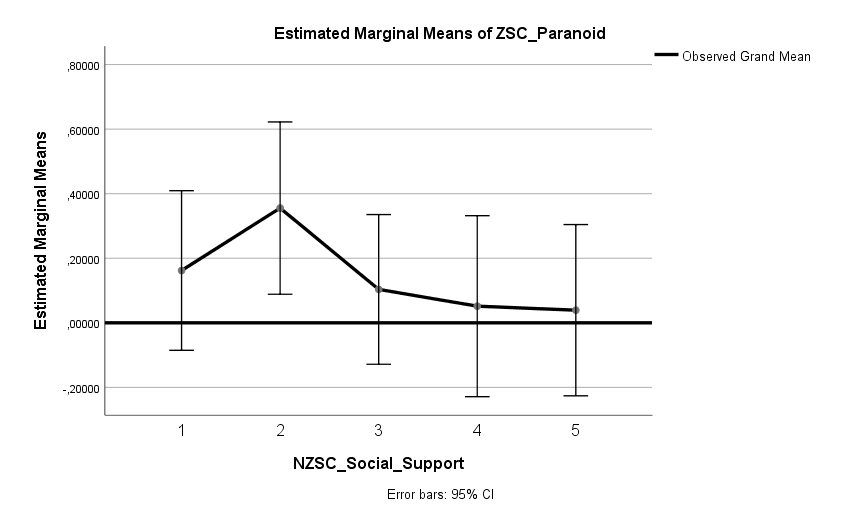
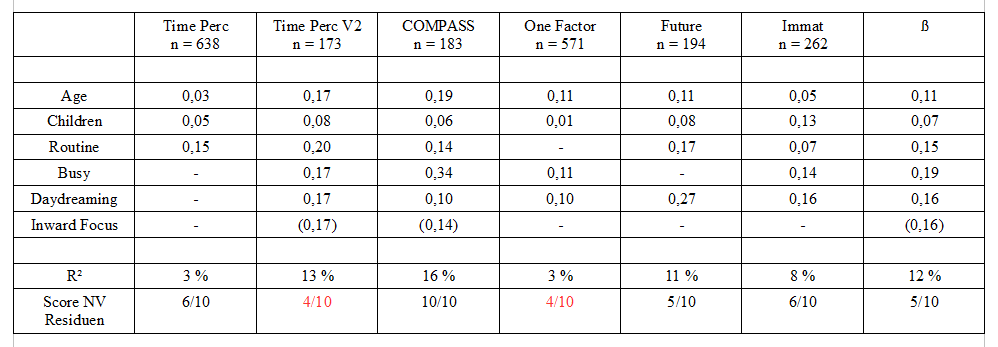
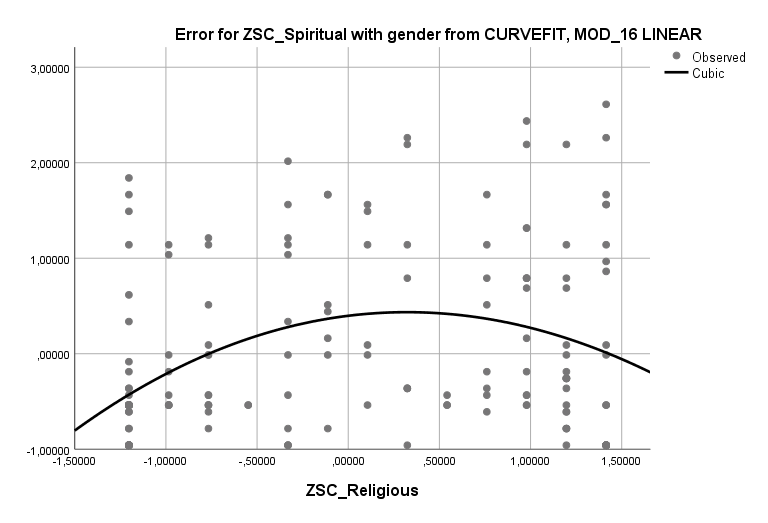
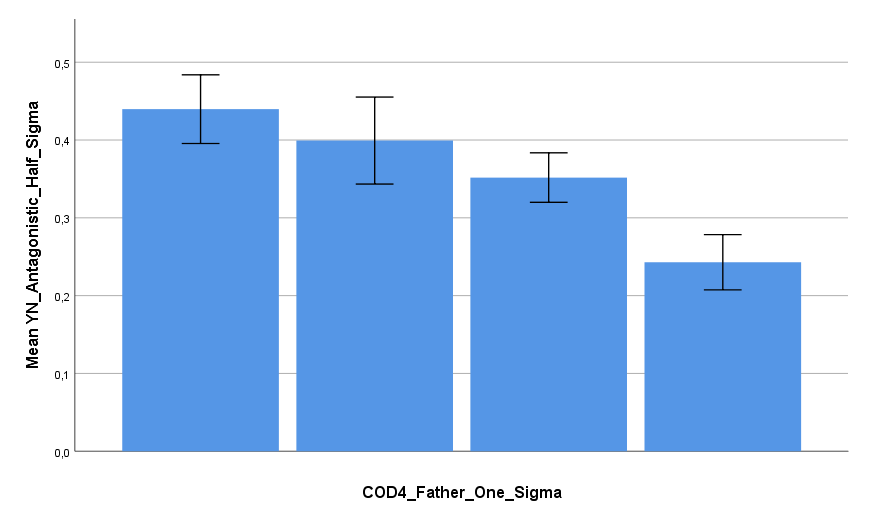
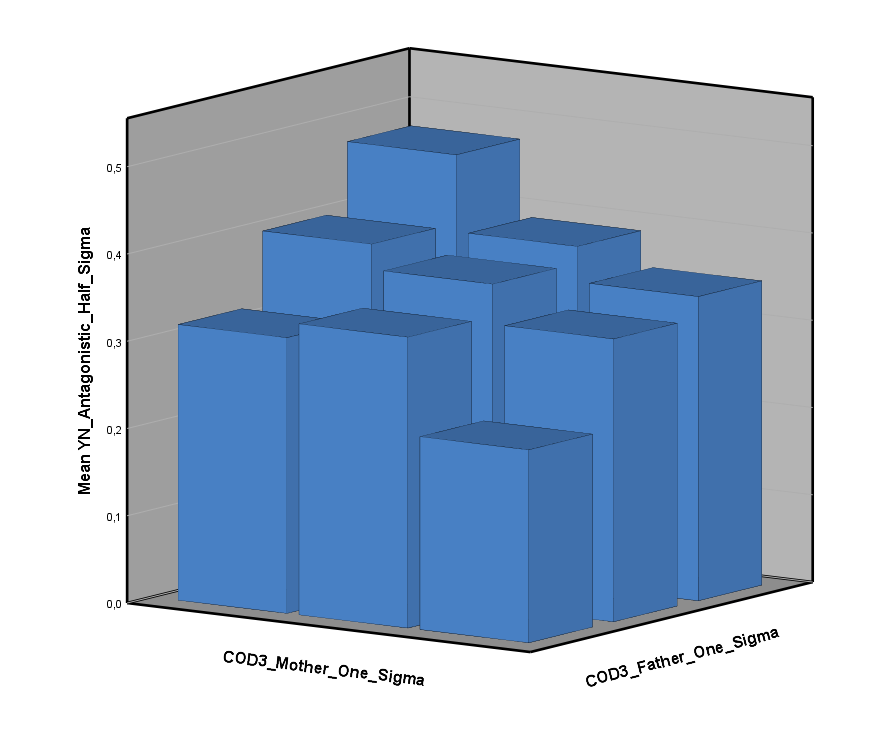
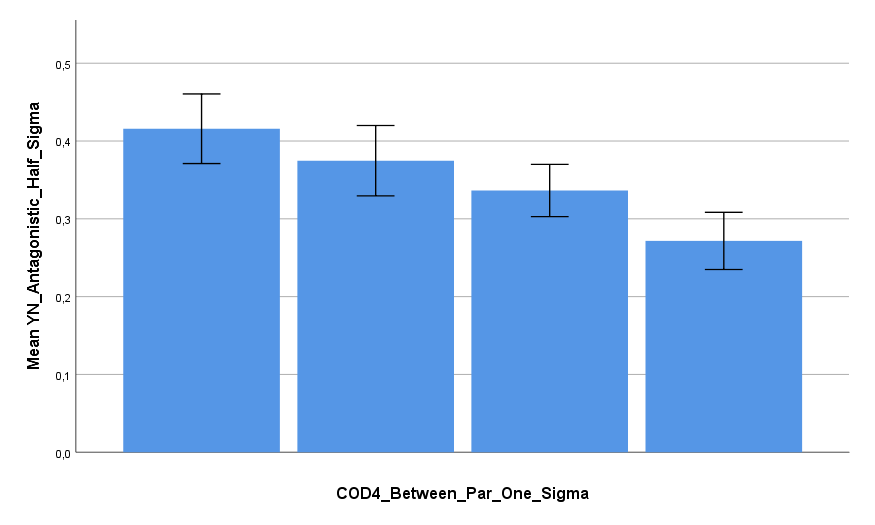
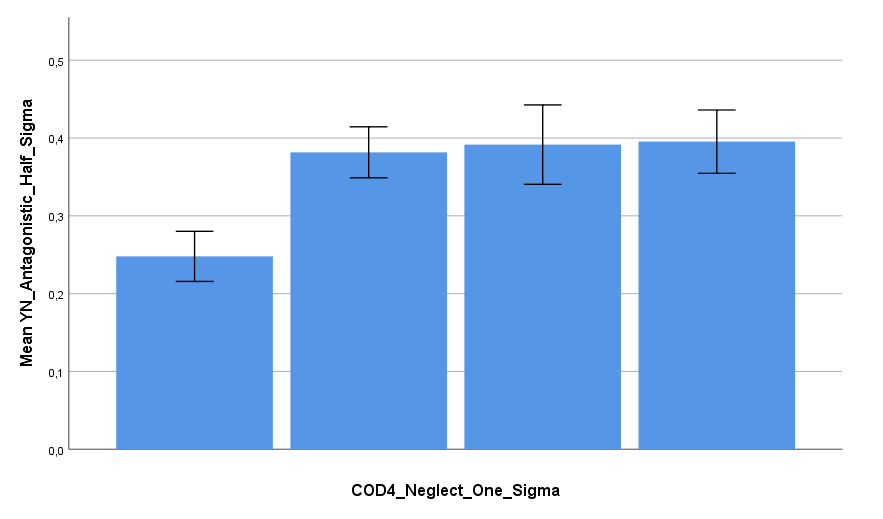
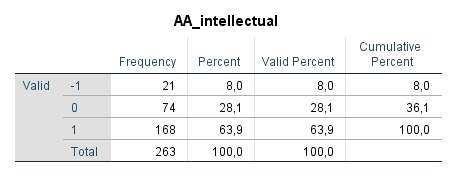
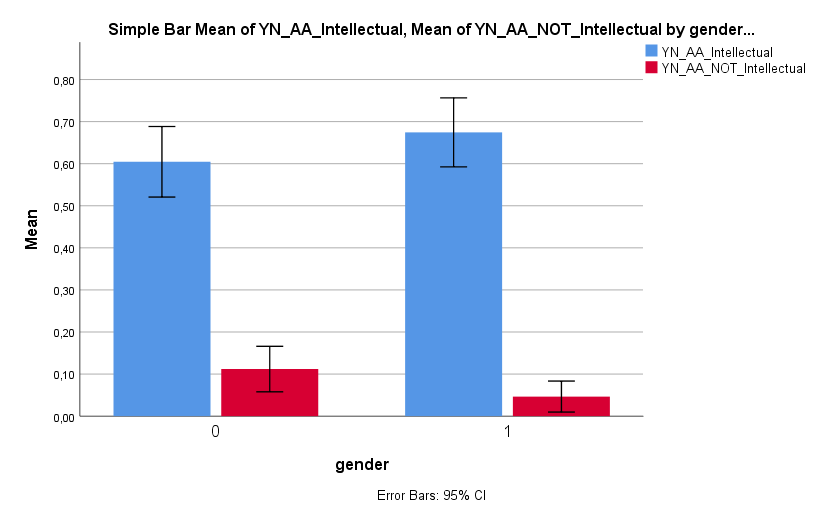
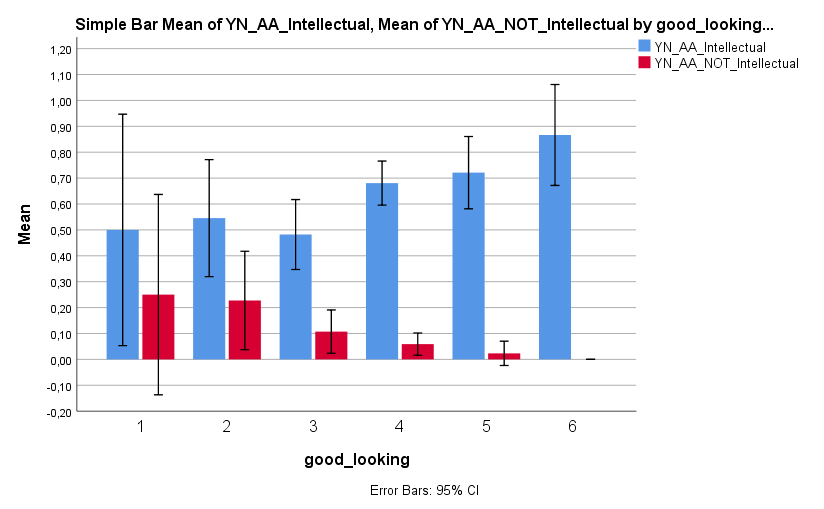
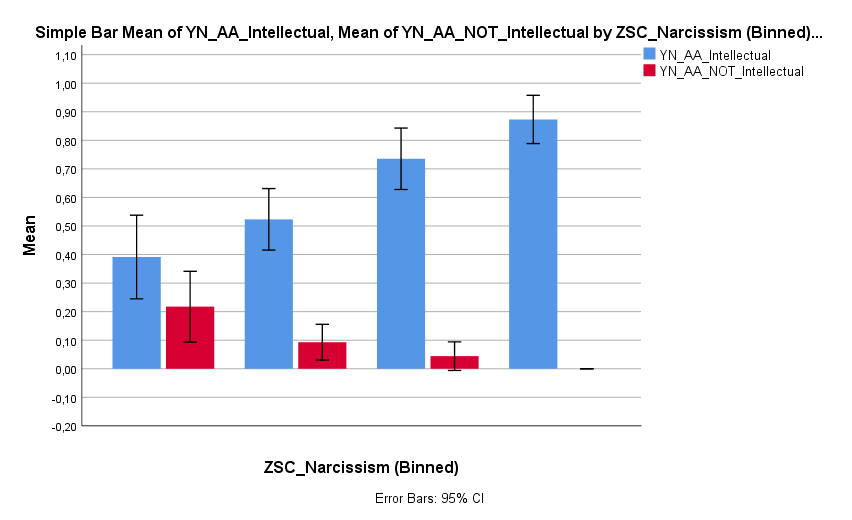

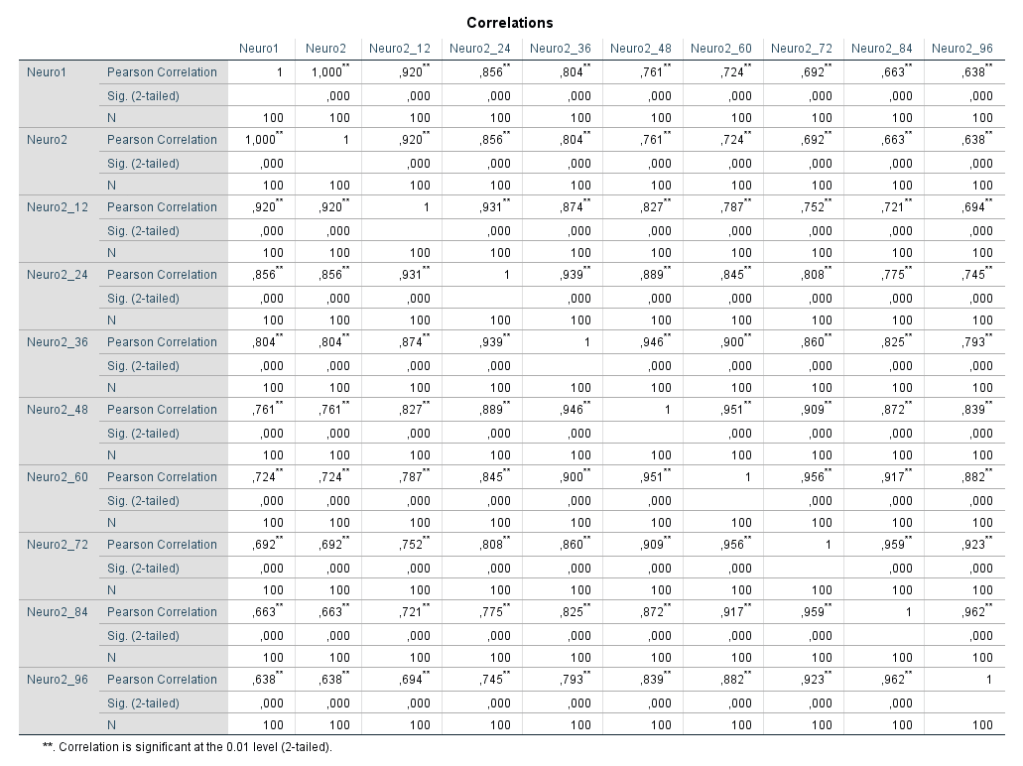
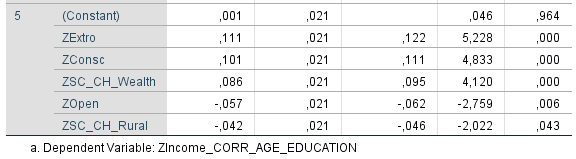
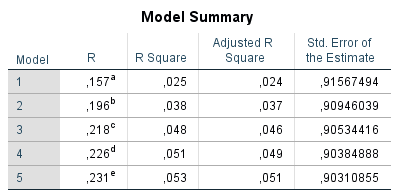
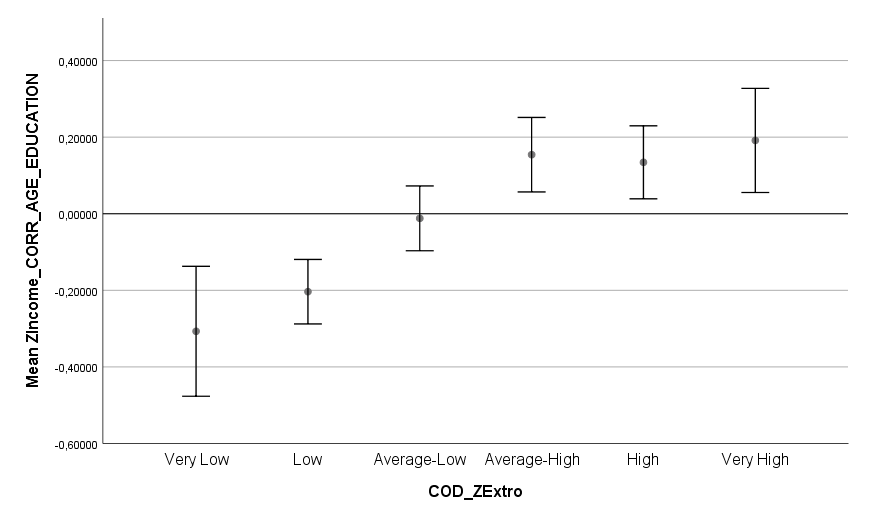
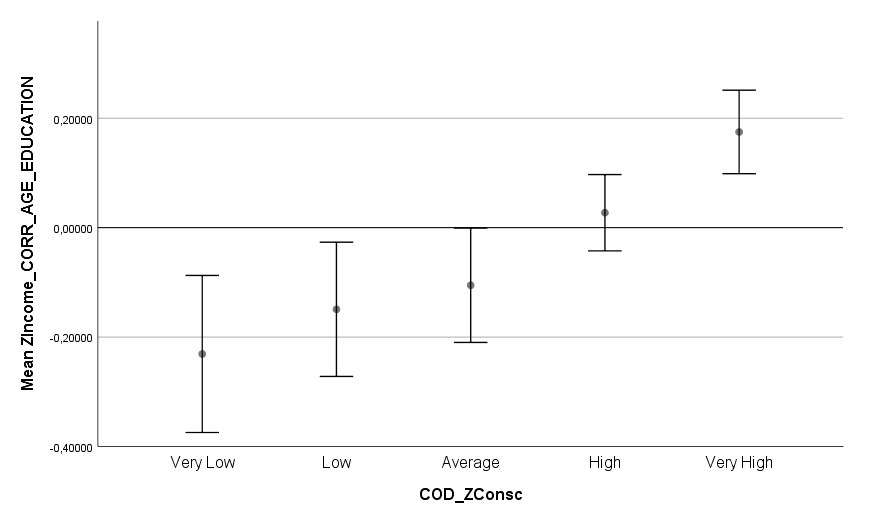
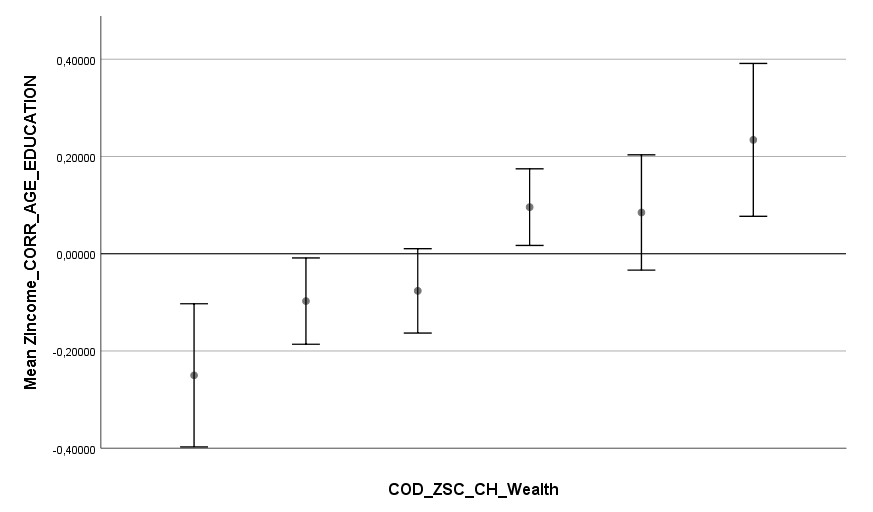
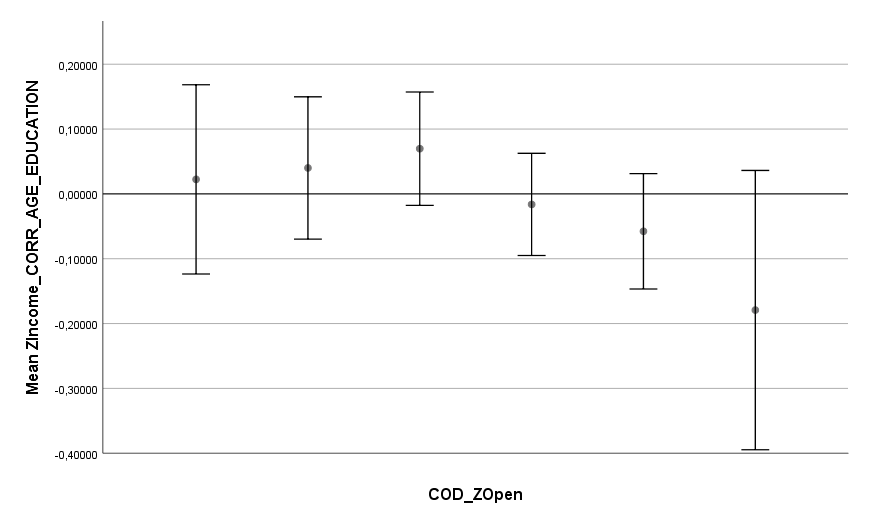
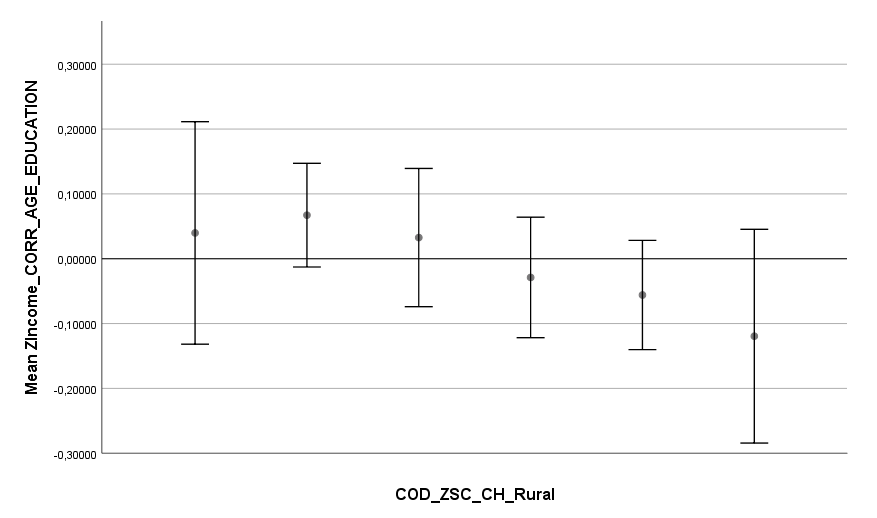
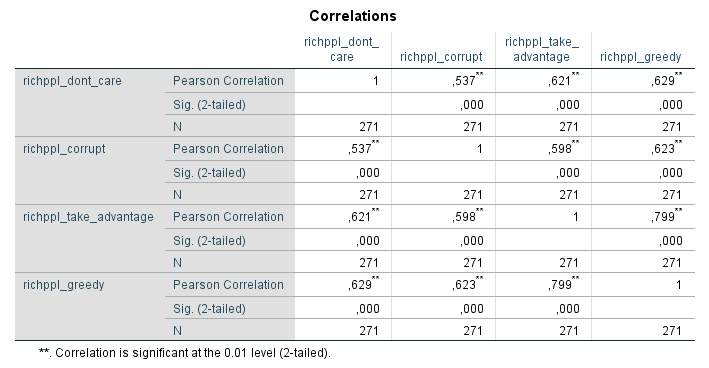
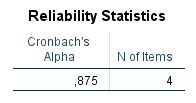
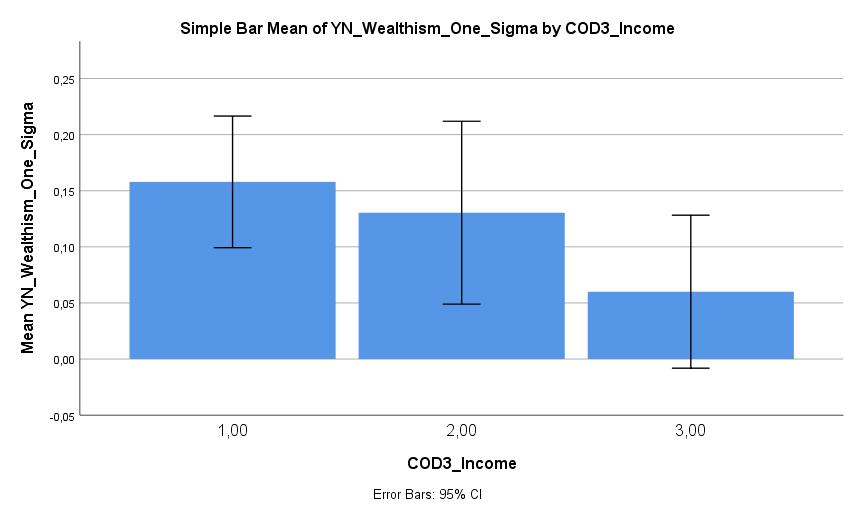


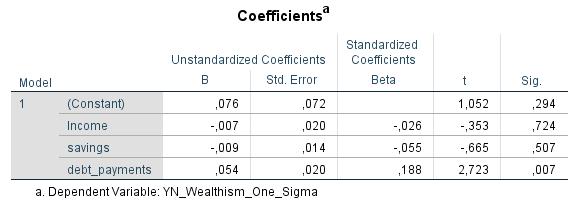
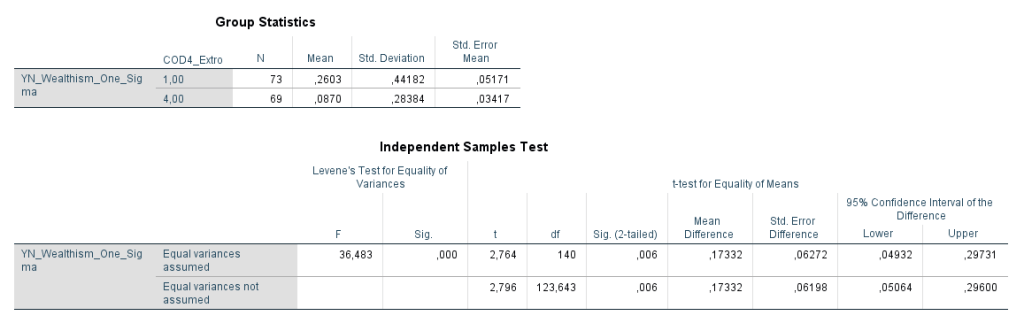
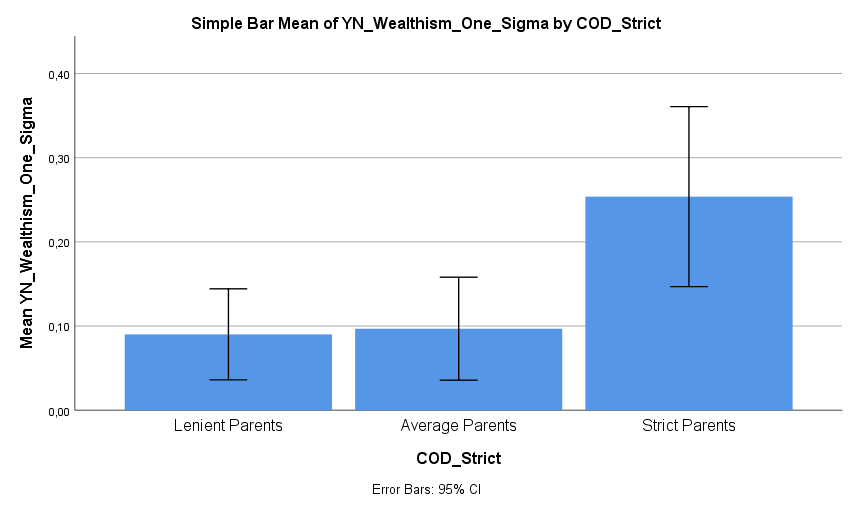

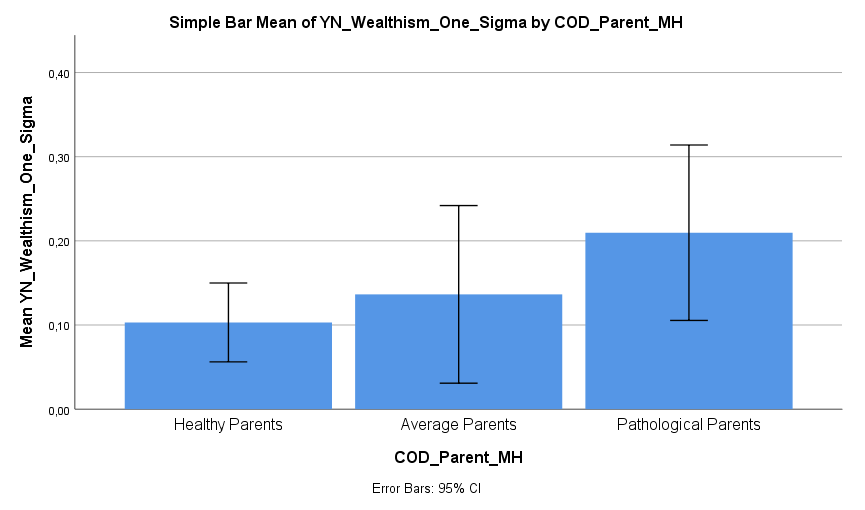

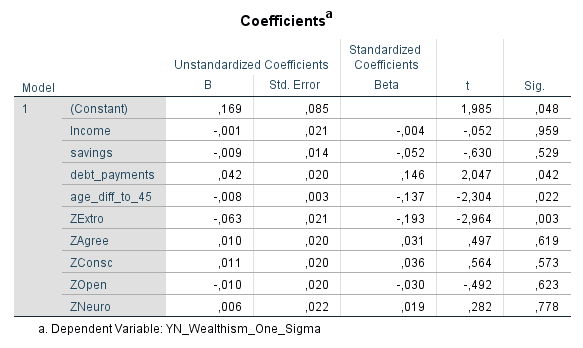
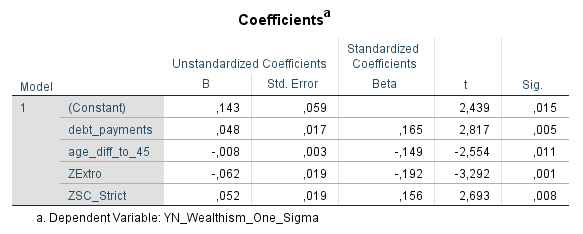
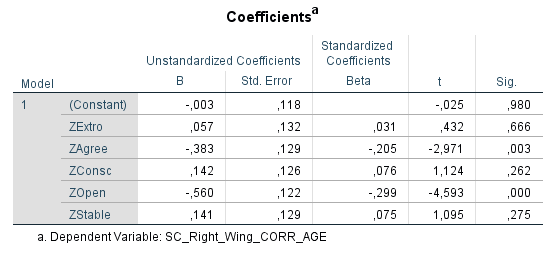
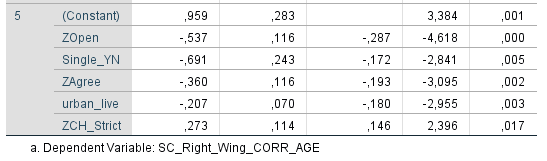

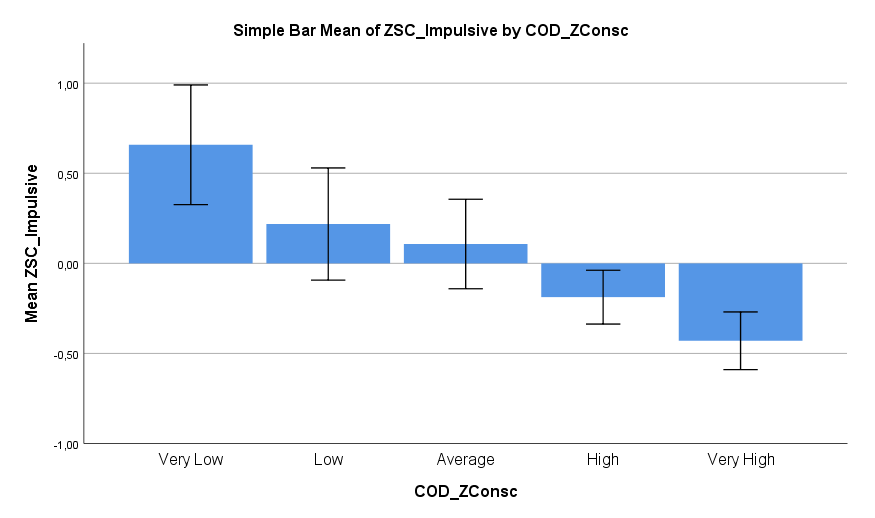

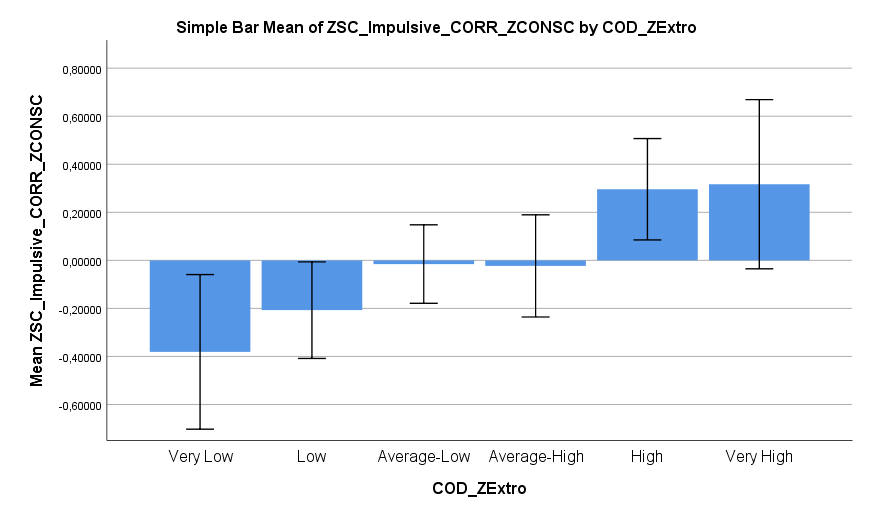

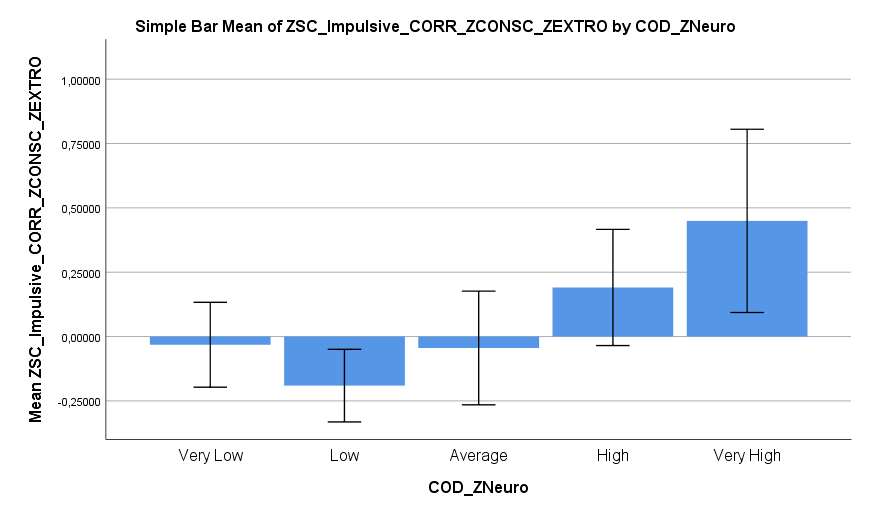
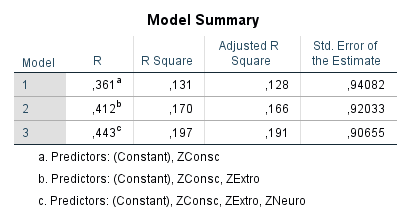

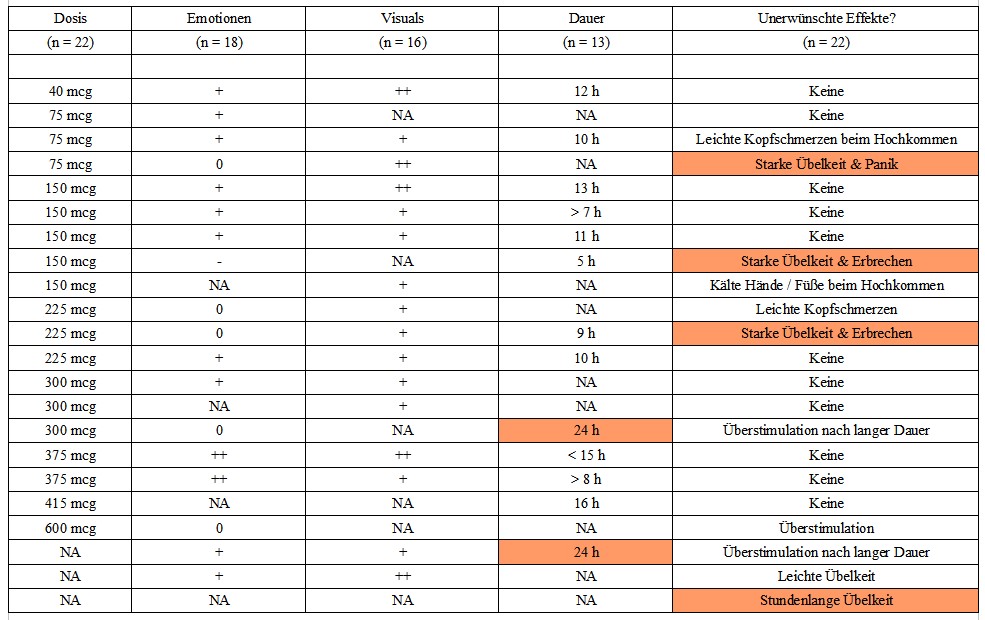

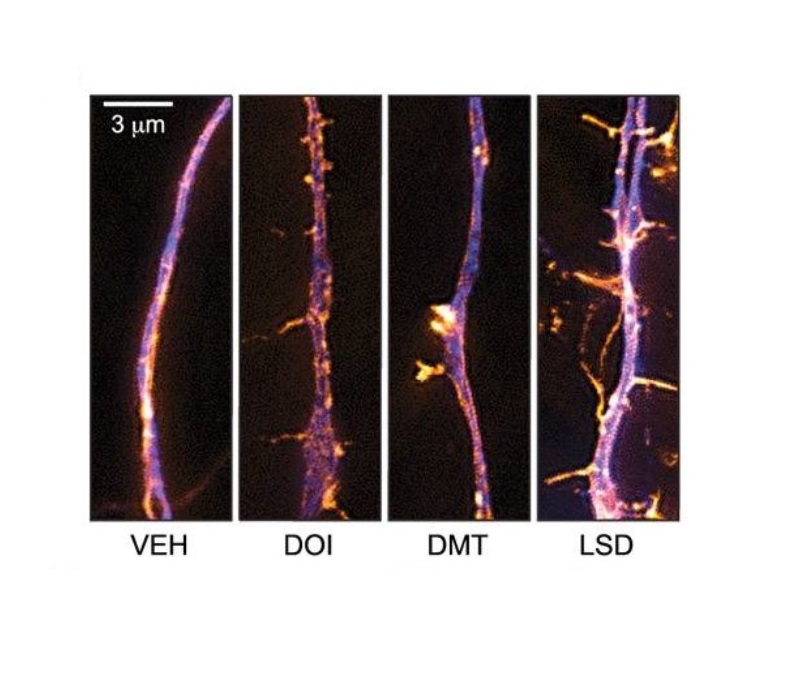


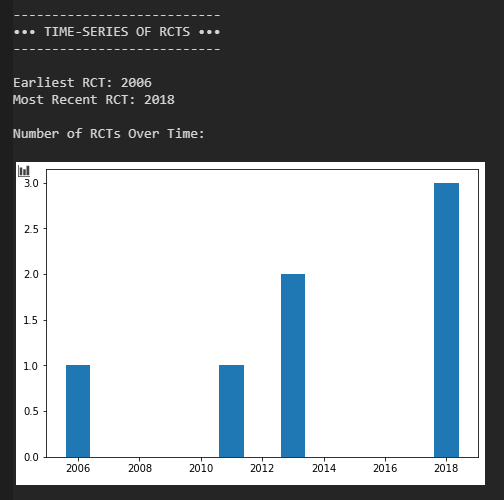
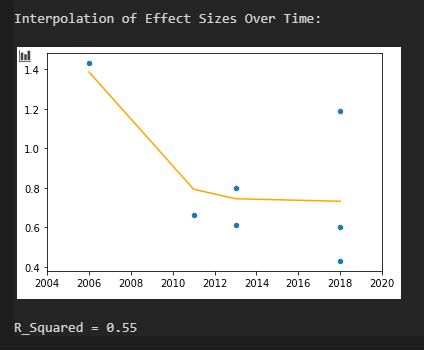
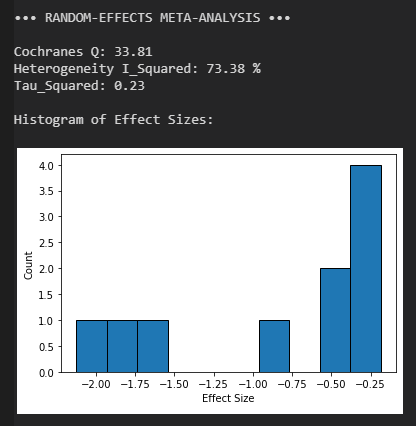
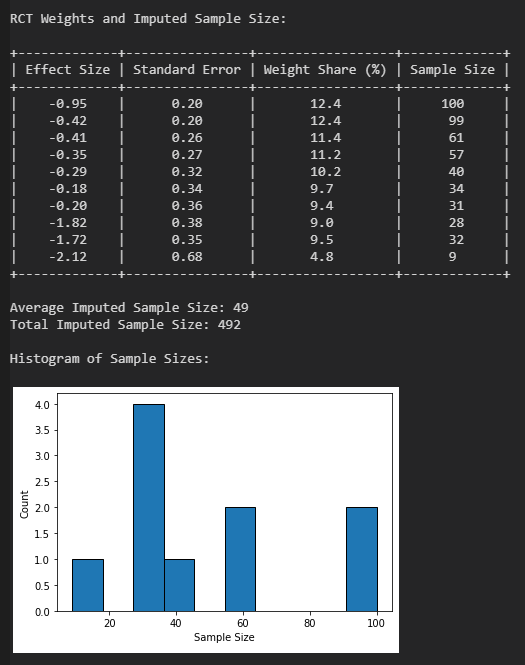
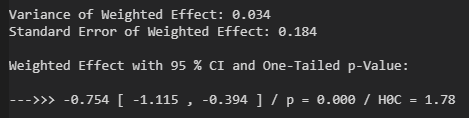
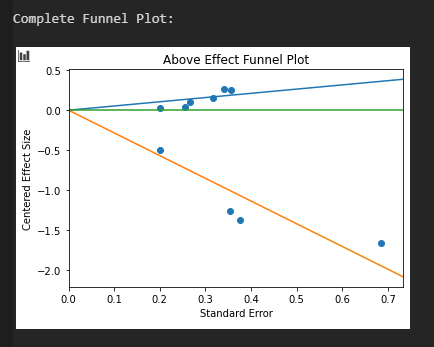

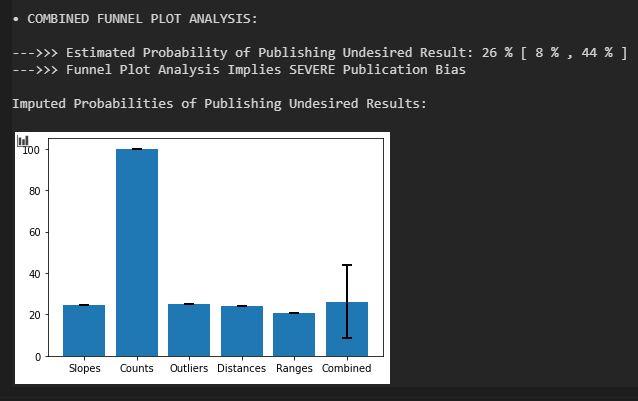

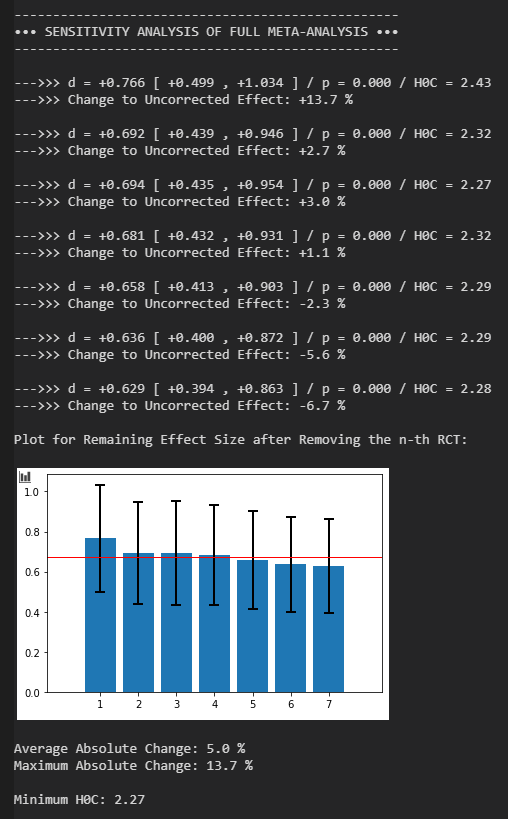
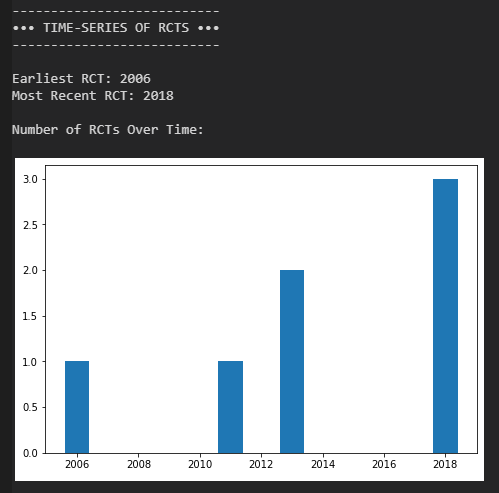
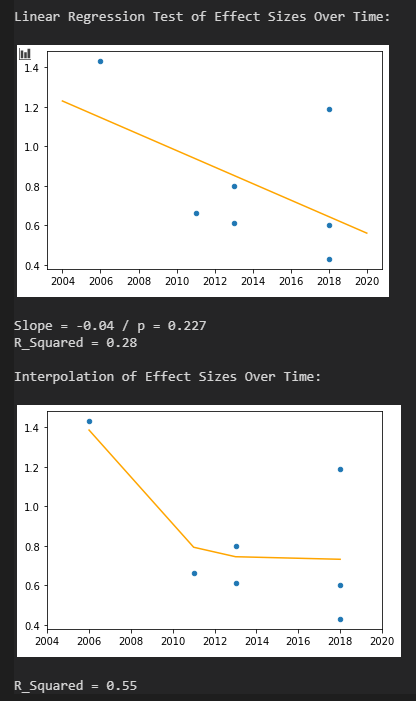

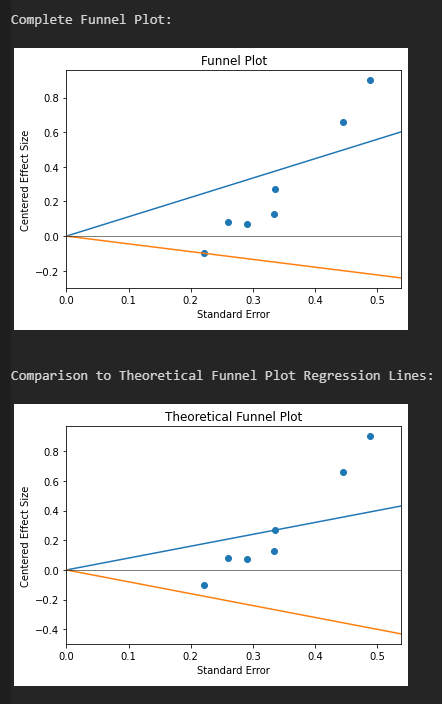

{kind=link}
{kind=link}
{kind=link}