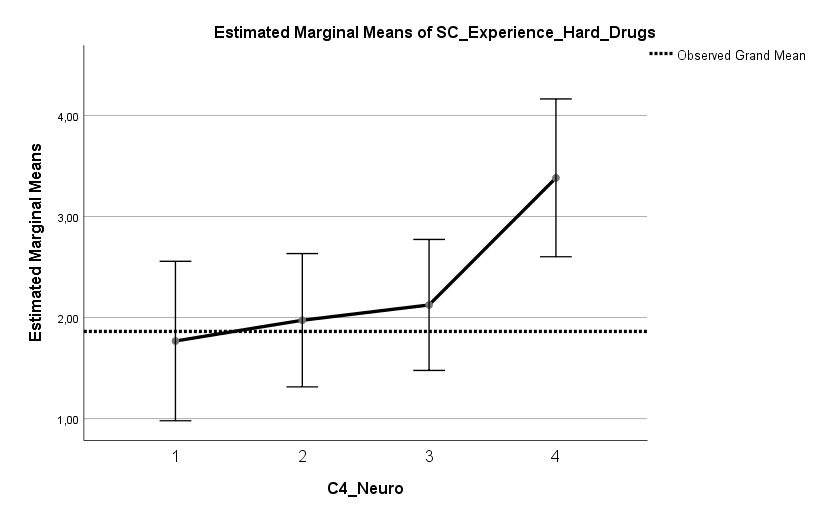
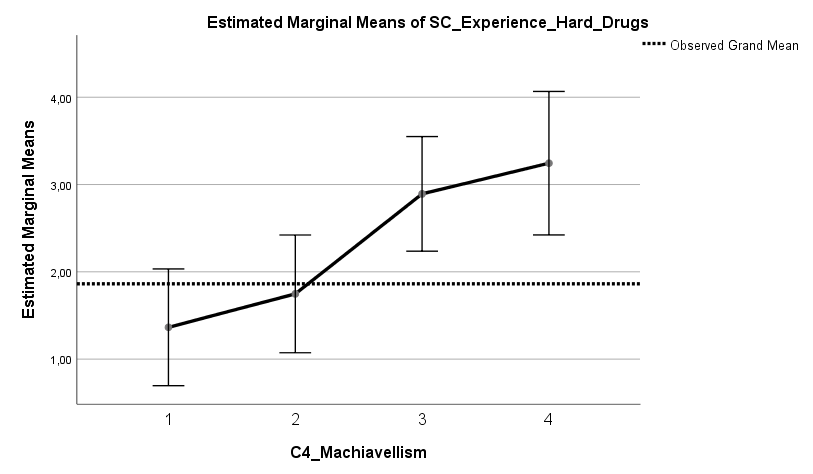
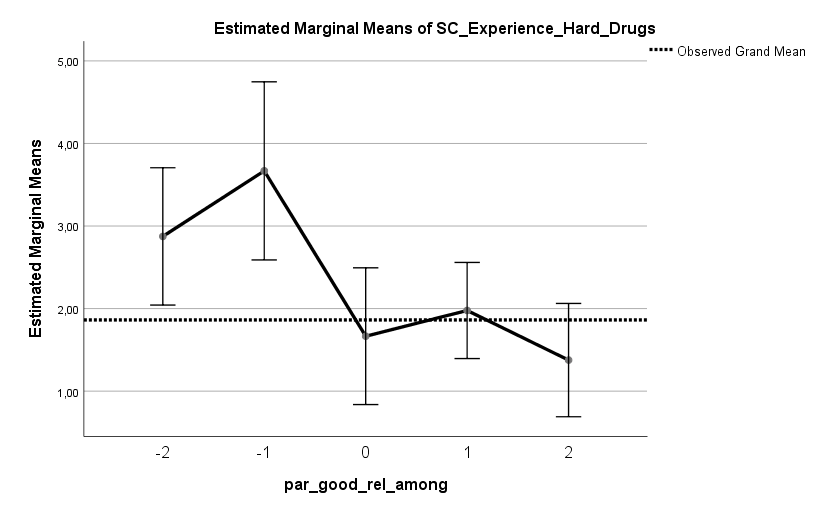
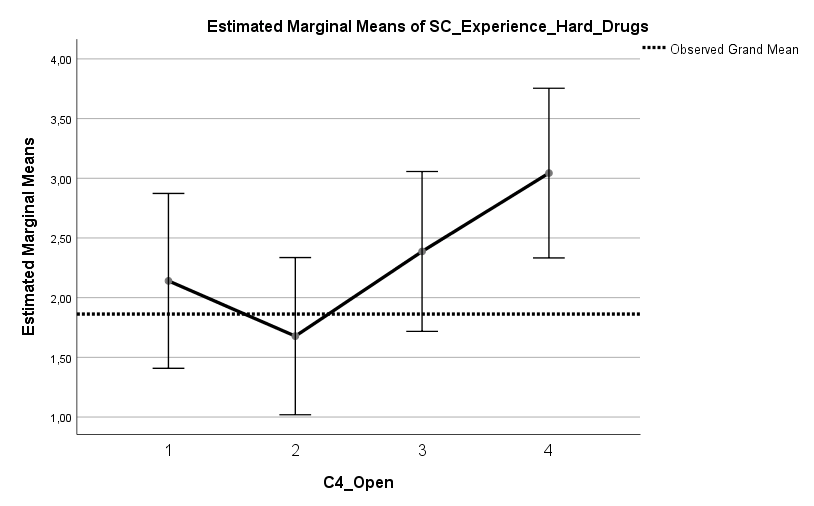
Die Auswertung einer Umfrage aus dem Harvard Dataverse mit n = 401 Teilnehmern (US-Amerikaner, mittleres Alter 43 Jahre, Standardabweichung 14 Jahre) zeigt vier signifikante Prädiktoren für den Impfstatus, welche insgesamt etwa 30 % der Varianz* im Impfstatus erklären können. Zu wenig, um von einem vollständigen Bild sprechen zu können, aber durchaus ein guter Teil des Bildes. In Reihenfolge der Effektstärke, größte Effektstärke voran, sind die Prädiktoren:
- Einschätzung des Risikos eines tödlichen Ausgangs
- Wohnumgebung: Urban vs. Ländlich
- Politische Positionierung: Links vs. Rechts
- Formale Bildung
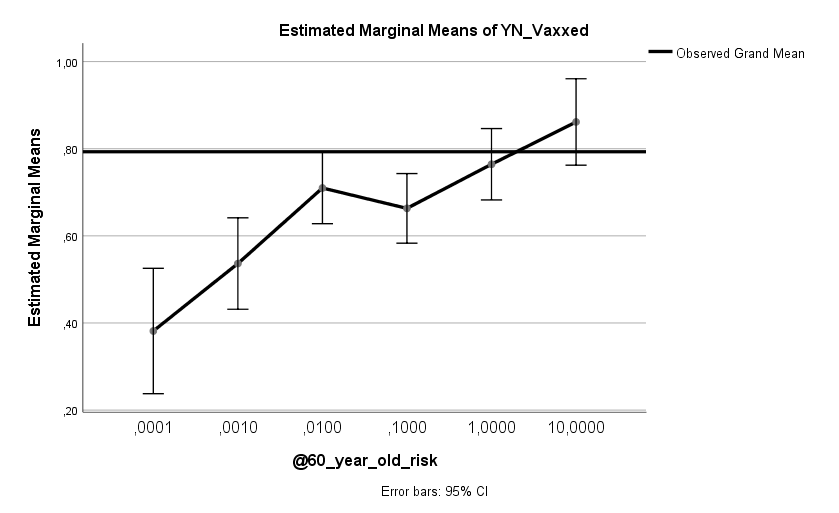
Unter anderem wurden die Teilnehmer gefragt, wie hoch sie das Risiko eines tödlichen Ausgangs einschätzen, wenn sich ein ungeimpfter und nie-infizierter 60-Jähriger mit dem Virus ansteckt. Die korrekte Antwort lautet circa 0,75 %. Nur 23 % der Teilnehmer lagen nah am korrekten Wert. 14 % haben das Risiko überschätzt, 63 % haben es unterschätzt. Es zeigt sich ein klarer Zusammenhang zwischen Risikoeinschätzung und Impfstatus. Unter jenen, die das Risiko sehr hoch einschätzen, ist die Wahrscheinlichkeit geimpft zu sein 2,3-Mal [1,6, 3,3] höher wie unter jenen, die das Risiko als sehr gering sehen. Dies gilt, wie bei allem folgenden auch, bereinigt nach allen anderen Variablen im Modell.
Ein großer Einfluss zeigt auch die Wohnumgebung. Leute, die mäßig bis sehr urban wohnen, haben eine 1,6-Mal [1,2, 2,3] höhere Wahrscheinlichkeit geimpft zu sein als jene, die sehr ländlich wohnen. Ich denke nicht, dass Zugang hier der ausschlaggebende Faktor ist. In den USA impfen auch ländliche Ärzte schon seit Frühling. Mentalität scheint eine plausiblere Erklärung.
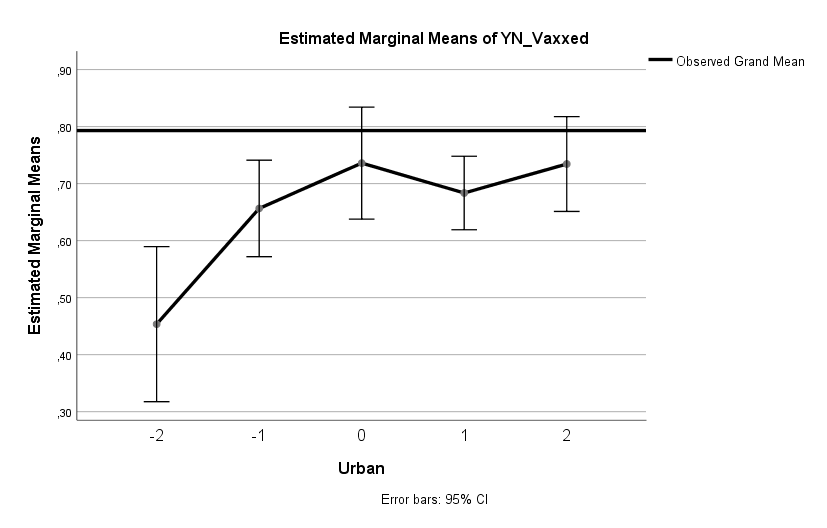
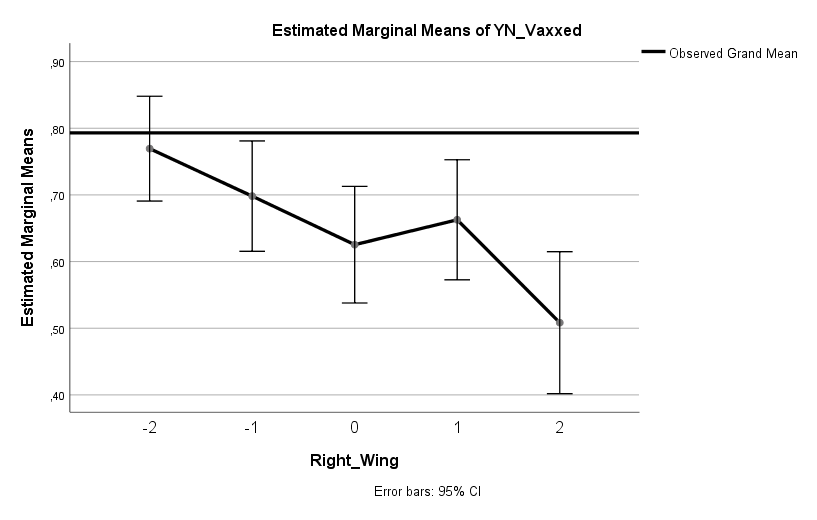
Ähnlich stark ist der Einfluss der politischen Positionierung. Leute, die angeben stark in Richtung Links / Progressiv / Democrat zu tendieren, haben eine 1,5-Mal [1,2, 1,9] höhere Wahrscheinlichkeit geimpft zu sein als jene, die angeben stark in Richtung Rechts / Konservativ / Republican zu tendieren.
Es lohnt sich anzumerken, dass es sich hier um einen seperaten Effekt handelt. Es ist zwar durchaus so, dass eine recht enge Korrelation zwischen Wohnumgebung und politischer Einstellung besteht (in ländlichen Regionen ist der Anteil jener mit konservativen Einstellungen i.d.R. höher), jedoch gilt der Effekt der Wohnumgebung bereinigt nach politischer Positionierung und der Effekt politischer Positionierung bereinigt nach Wohnumgebung. Anders gesagt: In jeder Gruppe mit fixer politischer Positionierung ist der Anteil Geimpfter in der urbanen Gruppe höher als in der ländlichen Gruppe. Und in jeder Gruppe fixer Wohnumgebung ist der Anteil Geimpfter bei Democrats höher als bei Republicans.
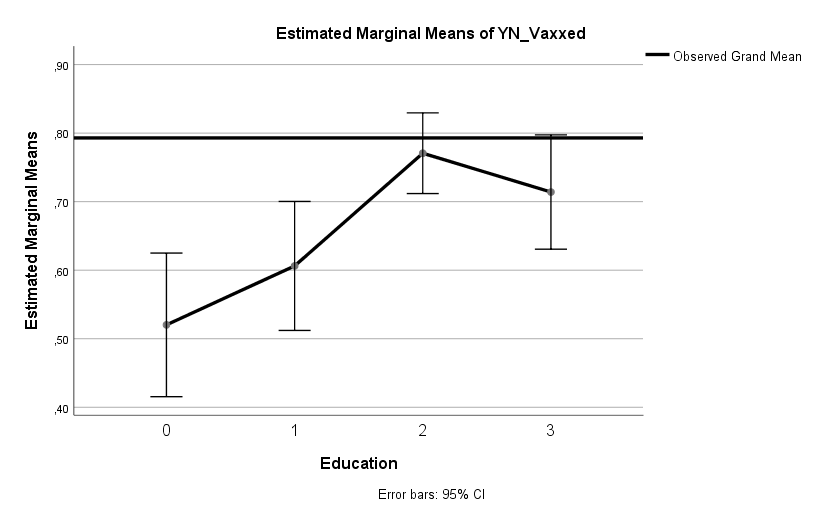
Ein weiterer signifikanter Faktor ist formale Bildung. Unter Teilnehmern, die angeben einen akademischen Abschluss (Bachelor’s oder höher) zu haben, ist die Wahrscheinlichkeit geimpft zu sein 1,4-Mal [1,0, 1,7] höher als unter jenen mit High School Abschluss oder niedriger. Wie man am 95 % Konfidenzintervall erkennen kann, erreicht der Effekt aber nur knapp die Marke der statistischen Signifikanz p < 0,05. Alle anderen genannten Effekte sind hingegen sehr solide signifikant mit p < 0,001.
Wie erwähnt erklären diese vier Faktor etwa 30 % der Varianz* beim Impfstatus. Das deutet darauf hin, dass einige relevante Faktoren im Modell fehlen. Einmal wäre hier das Alter zu nennen. Das Alter wurde zwar erfasst, war aber im Modell kein signifikanter Prädiktor obwohl Impfquoten in der Praxis eine sehr deutliche Abhängigkeit mit dem Alter zeigen. Diese Diskrepanz erklärt sich wohl daraus, dass die meisten Teilnehmer im mittleren Alter lagen und somit nur ein kleiner Teil der Skala abgedeckt wurde. Es gab kaum Teilnehmer Anfang Zwanzig oder im Seniorenalter. Und keine Teenager oder Kinder. Eine weitere Variable, die zusätzliche Varianz erklären könnte, wäre die Einstellung zu alternativ-medizinischen Methoden. Ein ausgeprägter Glaube daran können zu mehr Skepsis gegenüber Impfstoffen, die klar in der Schulmedizin zu verorten sind, führen. Auch fehlt im Modell der Druck durch das soziale Umfeld, in Richtung Impfung oder in umgekehrter Richtung, sowie die Härte staatlicher Maßnahmen.
* Bei Modellen wird im ersten Schritt für jede Gruppe der Mittelwert als Schätzwert für die Zielvariable (hier Impfquote) verwendet. Dabei ergibt sich eine Differenz zwischen Schätzwert und realem Wert, die Varianz. Die Hinzunahme einer Variable bringt den Schätzwert näher an den realen Wert. Es wird somit ein Teil der Varianz erklärt. Würde die Hinzunahme einer Variable immer die Hälfte der Strecke zwischen Mittelwert und realem Wert schließen, so wäre die erklärte Varianz 50 %. Man darf sich erklärte Varianz also durchaus geometrisch denken, als die Abdeckung der Strecke zwischen Mittelwert und realem Wert.