Ketamin erlebt gerade ein großes Comeback, diesmal nicht auf Parties, sondern vor allem in Laboren und Kliniken. Die nächste Generation antidepressiver Medikamente wird es zwar nicht werden, dafür ist das Sicherheitsprofil nicht gut genug, aber es etabliert sich als eine “Last Line of Defence”. Also angewandt bei Leuten, bei denen a) traditionelle Behandlungsmethoden für Depression versagt haben (CBT, SSRI) und b) es keine Geschichte von Suchtverhalten gibt. Letzteres da Ketamin in klinischer Umgebung zusammen mit Benzos verabreicht wird, um die Gefahr schwerer Angstzustände aufgrund der dissoziativen Wirkung von Ketamin zu dämpfen, und Benzos bekannt dafür sind, sehr schnell zu einer starken Abhängigkeit zu führen.
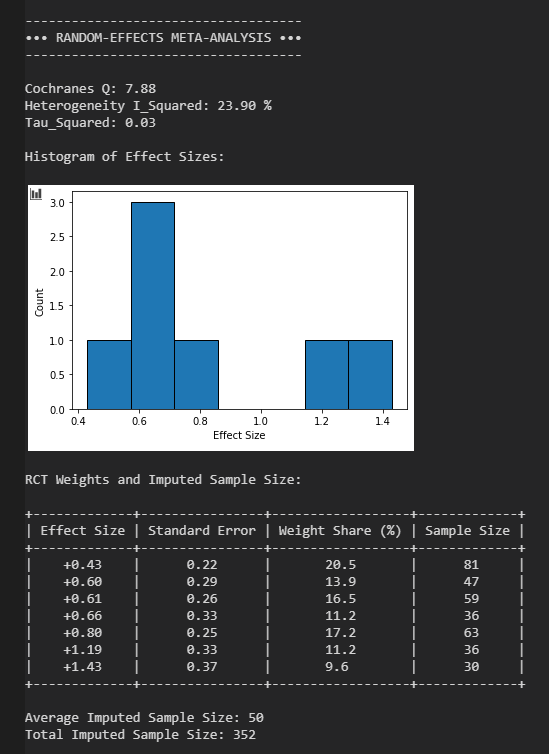
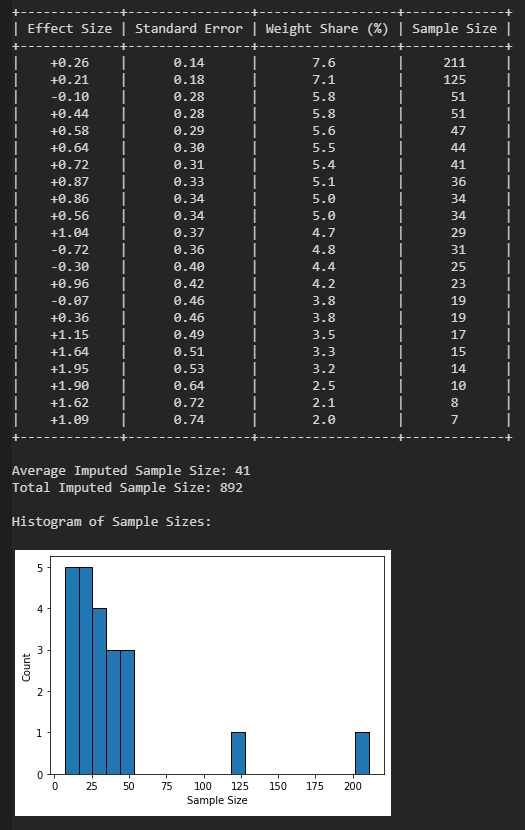
Die Datenlage für Ketamin ist noch recht überschaubar, aber sehr vielversprechend. Ich beziehe mich hier auf die Meta-Analyse “A systematic review and meta-analysis of the efficacy of intravenous ketamine infusion for treatment resistant depression: January 2009 – January 2019” von Walter S. Marcantoni. Ich habe die Daten dieser Meta-Analyse mal durch mein Programm Autobias gejagt, um zu sehen, wie es in diesem Fall um den Publikationsbias steht und ob sich auch nach Korrektur noch eine gute Effektstärke zeigt. Wie man am ersten Output sehen kann, umfassen die kontrollierten Experimente (Behandlungs- versus Placebogruppe) zu Ketamin bisher knapp 350 Probanten, im Mittel 50 Probanten pro Experiment. Die Heterogenität (Uneinigkeit) der Experimente bzgl. Effektstärke ist relativ gering.
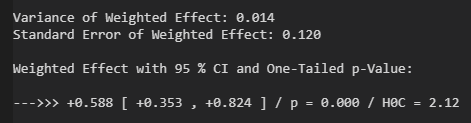
Insgesamt ergibt sich eine antidepressive Wirkung der Stärke (Cohen’s) d = 0.75 oberhalb des Placebo-Effekts, mit einem 95 % Konfidenzintervall von d = 0.51 bis d = 1.00. Die Nullhypothese kann mit sehr hoher Sicherheit abgelehnt werden (p < 0.001).
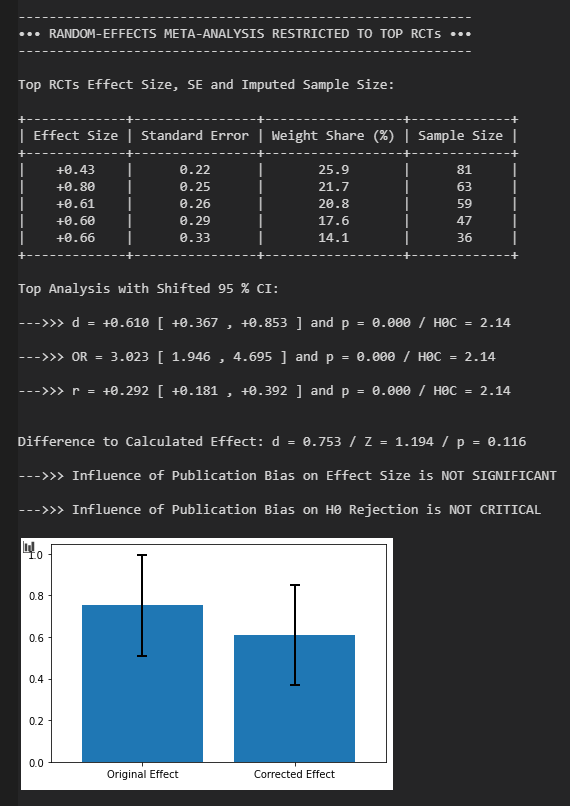
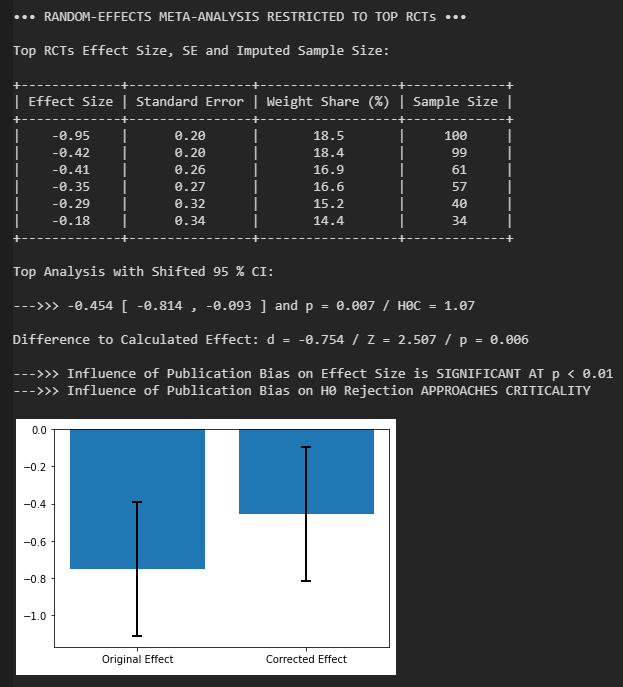
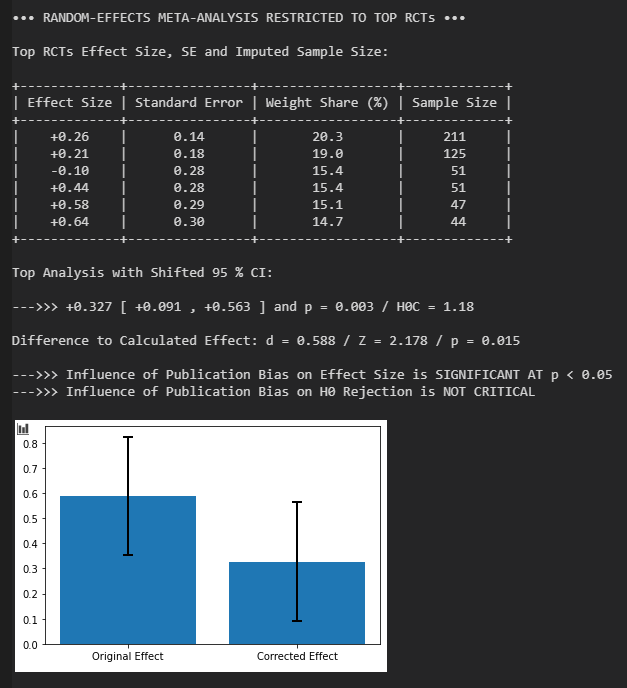
Bleibt das auch bestehen, wenn man die kleinsten Experimente verwirft? Tendenziell gilt die Regel: Je umfangreicher das Experiment, desto näher liegt die gefundene Effektstärke an der wahren Effektstärke. Es lohnt sich also, die Meta-Analyse unter Beschränkung auf die größten Experimente zu wiederholen. Hier bei Beschränkung auf die fünf größten Experimente:
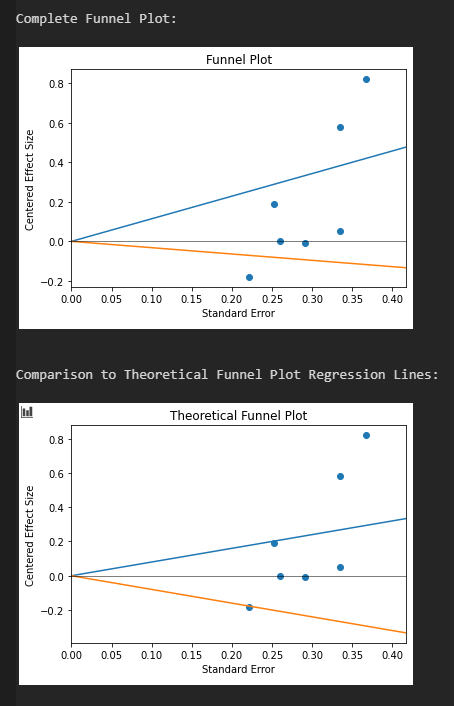
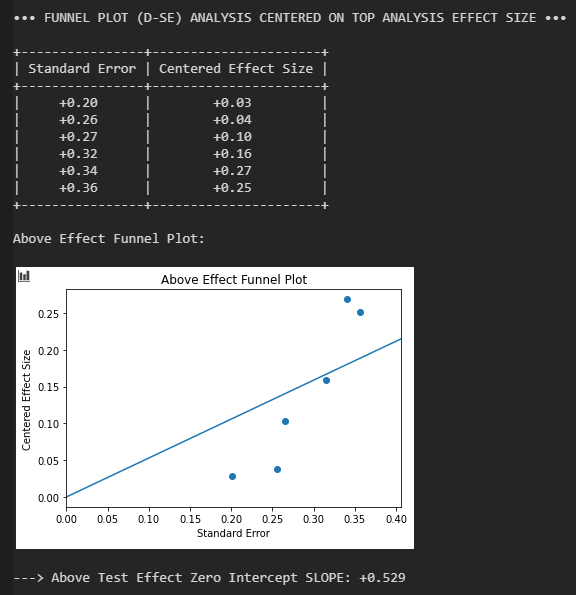
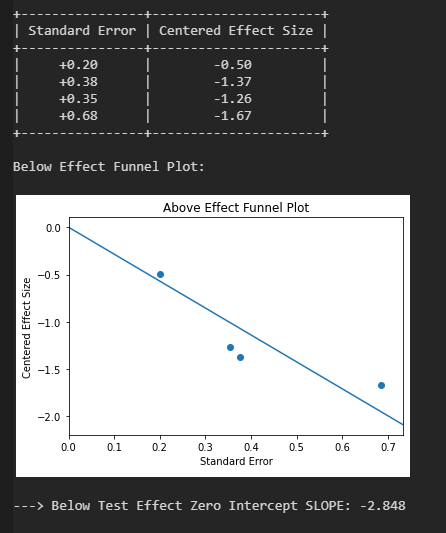
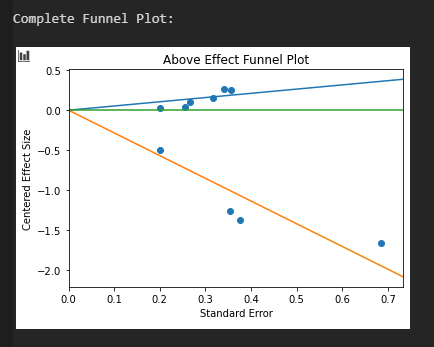
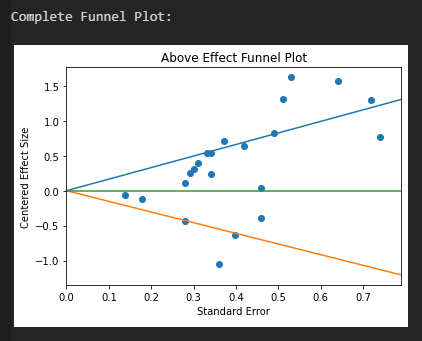
Es ergibt sich eine Reduktion auf d = 0.61 oberhalb des Placebo-Effekts, mit einem verschobenen 95 % KI von d = 0.37 bis d = 0.85. Die größten Experimente implizieren eine etwas kleinere Effektstärke, jedoch ist die Reduktion a) nicht als signifikant zu werten und b) gefährdet nicht die Ablehnung der Nullhypothese. Den schwachen Publikationsbias sieht man auch an der Asymmetrie des Funnel-Plots, mit zwei klaren Ausreißern in Richtung stärkerer Effekt.
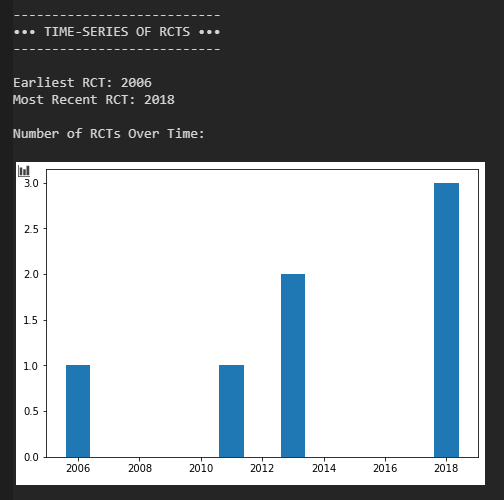
Für eine numerische Auswertung der Asymmetrien sind jedoch zu wenige Datenpunkte vorhanden. Am zeitlichen Plot kann man schön das steigende Interesse an Ketamin erkennen. Mit Ausnahme des Ausreißers von 2006 scheint das Publikationsjahr keinen nennenswerten Einfluss auf die Effektstärke zu haben.
Insgesamt hält der Effekt einer strengen Prüfung auf Publikationsbias sehr gut stand. Laut der Meta-Studie gibt es auch keine besonderen Auffälligkeiten beim Bias einzelner Studien (z.B. bezüglich Selektion oder Blinding). Man darf also guten Gewissens davon ausgehen, dass die festgestellte antidepressive Wirkung einem realen Effekt entspricht. In der Stärke sogar gut vergleichbar mit SSRI.
Hier ging es strikt um Experimente, bei denen Ketamin intravenös verabreicht wurde. Andere Experimente zeigen aber, dass die antidepressive Wirkung auch bei der Verabreichung über ein Nasenspray funktioniert. In den USA ist eine solches Nasenspray schon verfügbar, hergestellt von Johnson & Johnson, jedoch mit einem deftigen Preisschild von um die $ 400 pro Dosis versehen. Nicht nur die Nebenwirkungen, sondern auch der Preis zeigt, dass es bei Ketamin eher um klinische Interventionen in Extremfällen geht.
Letzteres ist aber sehr nützlich, da SSRI a) vier bis sechs Wochen brauchen um die volle Wirkung zu entfalten und b) in den ersten zwei Wochen suizidale Ideation sogar verstärken. Denkbar ungeeignet für Interventionen, bei denen schnell eine Wirkung erzielt werden soll. Ketamin könnte also tatsächlich eine wichtige Lücke füllen.
Von einer Selbstbehandlung mit Ketamin mit Bezug des Ketamins über einen Dealer ist definitiv abzuraten. Ohne medizinische Überwachung und gleichzeitiger Verabreichung sedierender Mittel, die gut in Kombination mit Ketamin funktionieren, ist die Gefahr von starken Angstreaktionen / Panikattacken inakzeptabel hoch. Mal abgesehen davon, dass es Methoden der Selbstbehandlung gibt, die in Meta-Analysen ähnlich vielversprechende Effektstärken zeigen, ohne die Gefahr solcher Reaktionen zu bergen: Fitness, Mindfulness, Lichttherapie.
Über die letzten Wochen habe ich an einer App zur automatischen Ermittlung, Visualisierung und Korrektur von Publikationsbias in Meta-Analysen gearbeitet und denke, dass ich es bei der jetzigen (zufriedenstellenden) Version belassen werde. Das Programm beginnt mit dem Input der Daten der kontrollierten Experimente (RCTs). Diese können direkt aus der Meta-Studie entnommen werden. Da Meta-Studien die RCT-Daten oft unterschiedlich präsentieren, habe ich vier Modi zum Input bereitgestellt. Wenn die Meta-Studie die Effektstärken und Grenzen der jeweiligen 95 % Konfidenzintervalle berichtet, bieten sich die ersten beiden Input-Modi an:
Input-Modus 1: Input als drei separate Listen. Liste der Effektstärken d = [0.30, 0.42, 0.08], Liste der unteren Grenzen dlow = [-0.20, 0.04, -0.48], Liste der oberen Grenzen dhigh = [0.50, 0.80, 0.54].
Input-Modus 2: Input als eine Liste der Abfolge d, dlow, dhigh. Zum Beispiel: l = [0.30, -0.20, 0.50, 0.42, 0.04, 0.80, 0.08, -0.48, 0.54].
Sind statt der Grenzen die Standardfehler oder Varianzen gegeben, was ziemlich oft der Fall ist, kann man die anderen beiden anderen Input-Modi nutzen. Die Grenzen des 95 % KI werden dann automatisch vor der Analyse berechnet.
Input-Modus 3: Input als eine Liste der Abfolge d, SE. Zum Beispiel: lse = [0.30, 0.18, 0.42, 0.25, 0.08, 0.24]
Input-Modus 3: Input als eine Liste der Abfolge d, Var. Zum Beispiel: lv = [0.30, 0.03, 0.42, 0.05, 0.08, 0.04]
Eine bestimmte Reihenfolge muss dabei nicht eingehalten werden. Notwendige Sortierungen werden automatisch gemacht. Da ein Teil der Ermittlung und Korrektur des Publikationsbias darauf basiert, eine Neuberechnung der Meta-Analyse mit Beschränkung auf die Top k RCTs vorzunehmen, muss dieser Wert k als Input gegeben werden. Top k RCTs meint hier die Anzahl k RCTs mit dem geringsten Standardfehler (höchste Probantenzahlen).
Mit der Variable fixed_mode = 1 lässt sich eine Meta-Analyse nach dem Fixed-Effects-Model erzwingen. Standardmäßig ist fixed_mode = 0 und es erfolgt eine Analyse nach dem Random-Effects-Model. Ein letzter möglicher Input ist die Aktivierung des Comparison Mode, darauf gehe ich aber später ein.
Zuerst rechnet das Programm die gesamte Meta-Analyse nach, beginnend mit der Berechnung von Cochrane’s Q, der Heterogenität I² und der Zwischen-Studien-Varianz Tau² sowie einem Histogramm der Effektstärken.
Danach werden Charakteristiken der einzelnen RCTs berechnet und angezeigt. Dazu gehören die Gewichte, mit denen die jeweiligen RCTs in die Meta-Analyse einfließen, sowie die jeweiligen Probantenzahlen, mittlere Probantenzahl pro RCT und gesamte Probantenzahl der RCTs. Das gefolgt von einem Histogramm der Probantenzahlen.
Zum Schluss die Meta-Analyse (nach Borenstein) und die Resultate: Varianz des Effekts, Standardfehler des Effekts, Effektstärke inklusive 95 % Konfidenzintervall, p-Wert der Differenz zum Nulleffekt und H0C als Maß für die Sicherheit der Ablehnung der Nullhypothese.
Dann beginnt der eigentliche Job: Publikationsbias ermitteln und wenn nötig korrigieren. Teil I basiert auf dem Prinzip der Konvergenz zum wahren Effekt. Man nimmt an, dass je größer die Studie, desto näher liegt der gefundene Effekt am wahren Effekt. Die Meta-Analyse wird also nochmals berechnet mit Beschränkung auf die k RCTs mit dem geringsten Standardfehler. Das Programm sortiert die Inputs, kürzt sie und berechnet die Gewichte neu. Tau² und der Standardfehler des Effekts wird explizit nicht neu berechnet. Das hat sehr gute Gründe (siehe Anmerkungen).
Das Programm zeigt dann das Resultat im gleichen Format an und wertet die Differenz zur kompletten Meta-Analyse. Es wird angenommen, dass jegliche Verschiebung der Effektstärke infolge des Publikationsbias geschieht. Es wird gewertet, ob der Einfluss des Publikationsbias auf die Effektstärke signifikant ist (und bei welchem p-Niveau) und ob die Effekt-Verschiebung die Sicherheit bei der Ablehnung der Nullhypothese maßgeblich berührt. Danch wird noch ein Plot der Unterschiede generiert. Für die Analyse des Funnel Plots in Teil II des Programms wird angenommen, dass die hier gefundene Effektstärke die wahre Effektstärke ist.
In Teil II wird versucht, Asymmetrien des Funnel Plots zu quantifizieren und somit eine ergänzende Einschätzung zum Publikationsbias zu liefern. Alle Effekstärken werden zuerst auf die in Teil I gefundene Effektstärke zentriert. Dann wird der Plot der Effekte oberhalb 0 gemacht, die Regressionsgerade berechnet, der Plot der Effekte unterhalb 0 generiert, wieder die Regressionsgerade berechnet und schlussendlich der gesamte Funnel Plot inklusive der Geraden gezeigt.
Jetzt werden die Asymmetrien berechnet:
Asymmetrie der Steigung der Geraden
Asymmetrie der Anzahl RCTs
Asymmetrie der Anzahl Ausreißer
Asymmetrie der Summe der Distanzen zur Mittellinie
Asymmetrie der maximalen Abweichungen zur Mittellinie
Zu jeder Asymmetrie wird eine Korrektur vorgenommen, die wildes Verhalten für Meta-Studien mit einer kleinen Anzahl RCTs verhindern soll (und somit eventuellen Trugschlüssen vorbeugt), die durch die Asymmetrie implizierte Wahrscheinlichkeit zur Publikation unerwünschter RCT-Ausgänge geschätzt und die Signifikanz gewertet.
Krönender Abschluss ist dann die Zusammenfassung dieser Asymmetrie-Merkmale zu einer Schätzung für die Wahrscheinlichkeit der Publikation unerwünschter RCT-Ausgänge (ohne Publikationsbias 100 %) und einer abschließenden Wertung der Signifikanz der Asymmetrien.
Man sieht, dass die gesamte Analyse auf zwei wohletablierten Prinzipien fußt:
Konvergenz der größten Studien zum wahren Effekt
Asymmetrien des Funnel-Plots
Teil I widmet sich dem ersten Punkt, Teil II dem zweiten. Weicht das Mittel der größten RCTs vom Mittel der kleinsten RCTs (bzw. dem Mittel aller RCTs) ab, dann ist das ein deutlicher Hinweis darauf, dass Publikationsbias vorliegt. Die Verschiebung der Effektstärke gibt Auskunft über das Maß des Publikationsbias. Der Blick auf den Funnel Plot wird dies bei signifikanter Verschiebung bestätigen. Die Asymmetrie auf viele verschiedene Arten zu quantifizieren schützt vor Trugschlüssen infolge bestimmter Eigenheiten oder Ausreißern. Man sieht am obigen Beispiel, dass eine reine Zählung der RCTs den Publikationsbias in diesem Fall nicht offenbart hätte, andere Indikatoren schlagen hingegen deutlich an.
Was ist H0C? Nichts anderes als der zum Unsicherheitsintervall gehörige Z-Wert, jedoch a) als Absolutwert und b) so skaliert, dass H0C >= 1 eine sichere Ablehnung der Nullhypothese bedeutet
Es gilt: H0C = abs(0.85*Effektstärke/(1.96*Standardfehler))
Was machen die Asymmetrie-Korrekturen beim Funnel-Plot? Eine sehr kleine Anzahl an RCTs kann zu enormen prozentualen Differenzen führen, welche nicht notwendigerweise enormen Publikationsbias reflektieren. Je kleiner die Anzahl RCTs, desto stärker dämpft das Programm die prozentualen Unterschiede, bevor sie in weitere Berechnungen einfließen
Ist die Wahrscheinlichkeit zur Publikation unerwünschter Resultate genau? Jein. Die Asymmetrie des Funnel Plots impliziert, dass auf der schwächeren Hälfte etwas fehlt. Es lässt sich grob ermitteln (Trim-And-Fill), wieviel man hinzufügen müsste, um den Plot bezüglich dem gegebenen Indikator symmetrisch zu machen. Daraus wiederrum lässt sich diese Wahrscheinlichkeit schätzen. Es bleibt aber ein Schätzwert. Durch die Mittellung über mehrere Asymmetrie-Indikatoren ist er immerhin genauer als die Schätzung basierend auf einem Indikator
Wieso wird bei der Beschränkung auf die Top k RCTs der Wert für Tau² und das 95 % KI nicht neuberechnet? Die Erklärung dazu ist leider etwas sperrig. Es gibt bestimmte Aspekte der Meta-Analyse, die ein typisches Verhalten mit der Änderung der Anzahl RCTs zeigen. Die Beschränkung auf wenige RCTs wird in fast allen Fällen die Zwischen-Studien-Varianz massiv reduzieren, so dass I² und Tau² Null wird. Somit ergibt sich eine Fixed-Effects Analyse mit unrealistisch engem Unsicherheitsintervall. Großes Problem! Es macht mehr Sinn, und ist auch viel konservativer, stattdessen die Unsicherheit der gesamten Meta-Analyse zu übernehmen und nur die Effektstärke anzupassen
Update 24. März 2021:
Ich habe vier zusätzliche Input-Modi hinzugefügt, welche erlauben, die Effektstärken auch mittels dem Odds-Ratio OR oder dem Korrelationskoeffizienten r einzugeben. Das ist vor allem für medizinische Meta-Studien nützlich, da dort gerne mit dem OR gearbeitet wird. Der Output der Ergebnisse erfolgt neben der Effektstärke als Cohen’s d jetzt stets auch in Form des OR und r.
Ich habe auch eine Sensitivity-Analyse hinzugefügt, ein Standard bei Meta-Analysen. Die Meta-Analyse wird wiederholt nachgerechnet, jeweils unter Entfernung eines einzigen Experiments. Dies erlaubt zu sehen, wie stark ein bestimmtes Experiment das Gesamtergebnis beeinflusst. Die Sensitivity-Analyse erfolgt einmal für die gesamte Meta-Analyse (alle RCTs) und einmal für die auf die Top k RCTs beschränkte Analyse, letztere auch wieder mit einem verschobenem statt neuberechnetem 95 % KI.
Update 25. März 2021:
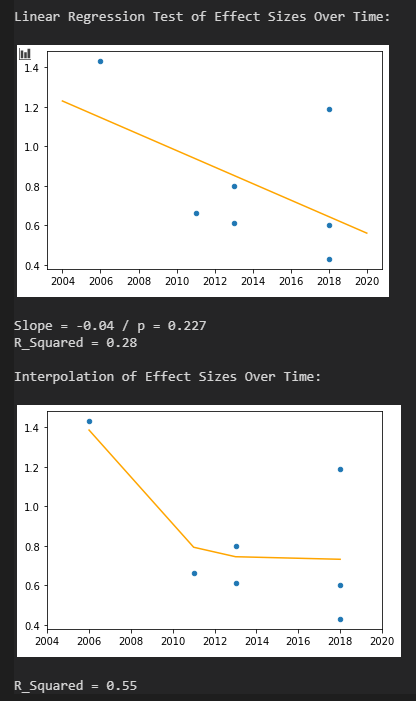
Optional kann man jetzt über die Variable year das Erscheinungsjahr der jeweiligen RCTs eingeben. Es folgt dann eine Visualisierung der Veröffentlichungen mit der Zeit und Test auf Abhängigkeit der gefundenen Effektstärken von Erscheinungsjahr. Letzterer Test ist häufig in Meta-Analysen zu finden. Für eine leere Liste year = [ ] wird dieser Abschnitt übersprungen.
Optional kann man jetzt über die Variable ind_bias den RCTs Gewichte für individuellen Bias zuordnen. Bei einem Eintrag 1 in der Liste ind_bias erfolgen keine Änderungen, bei einem Eintrag > 1 wird der Standardfehler der RCT um eben jenen Faktor erhöht. Dadurch erhält dieses RCT ein geringeres Gewicht in der Meta-Analyse. Will man z.B. bei insgesamt 5 RCTs die letzten beiden eingetragenen RCTs wegen hohem Bias-Risiko schwächer gewichten, so könnte man z.B. ind_bias = [1,1,1,1.33,1.33] setzen. Für eine leere Liste ind_bias = [ ] wird keine Anpassung vorgenommen.
Neben dem Funnel-Plot wird jetzt auch der theoretische Funnel-Plot angezeigt. Er zeigt die Regressionslinien, die man bei Abwesenheit von Publikationsbias für normalverteilte Effektstärken erhält, wenn die Anzahl RCTs gegen unendlich geht.
Einführung einer Reihe von Checks, um gängige Inputfehler zu erkennen und wenn möglich zu übergehen. Ansonsten eine saubere Beendigung des Programms.
Bekannte Fehler:
Die Interpolation beim Funnel-Plot bzw. Jahresplot erzeugt manchmal die Fehlermeldung “RuntimeWarning: invalid value encountered in power kernel_value”. Bisher bin ich noch nicht dahinter gekommen, aber die Interpolation funktioniert trotzdem und das Programm läuft ohne Probleme weiter.
Der Code:
Der aktuelle Code (25. März), geschrieben in Python 3.9. Zum Ausführen benötigt man a) einen Python-kompatiblen Compiler, b) die Installation von Python und c) die Installation aller verwendeten Module (Matplotlib, Scipy, etc …)
#%%
import matplotlib.pyplot as plt
import math
import scipy.stats
import numpy as np
import pandas as pd
import statsmodels.api as sm
from prettytable import PrettyTable
import sys
# Number to restrict
k_test = 3
# specify year and individual bias, if available, otherwise leave empty
# ind_bias = 1 -> no individual bias, ind_bias > 1 -> higher individual bias
ind_bias = [1,1,1,1,1.33,1.33,1.33]
year = [2018,2018,2013,2011,2013,2018,2006]
# input modes
# 1 = pre-formatted / 2 = d, dlow, dhigh, ... / 3 = d, se, ... / 4 = d, var, ...
# 5 = pre-formatted OR / 6 = OR, ORlow, ORhigh, ...
# 7 = pre-formatted r / 8 = r, rlow, rhigh, ...
mode = 1
if mode > 0.5 and mode < 1.5:
d = [0.43,0.60,0.61,0.66,0.80,1.19,1.43]
dlow = [-0.01,0.03,0.10,0.00,0.31,0.53,0.71]
dhigh = [0.86,1.17,1.12,1.31,1.30,1.84,2.15]
if mode > 1.5 and mode < 2.5:
l = [-0.82,-1.55,-0.09,-0.94,-1.59,-0.29,-0.65,-1.24,-0.06,-0.93,-1.45,-0.41,-0.85,-1.29,-0.41,-0.90,-1.45,-0.35,-1.13,-1.72,-0.54,-1.07,-1.51,-0.63,-0.93,-1.48,-0.38,-0.61,-1.23,0.01]
d = []
dlow = []
dhigh = []
i = 0
while i < len(l):
d.append(l[i])
i += 1
dlow.append(l[i])
i += 1
dhigh.append(l[i])
i += 1
if mode > 2.5 and mode < 3.5:
lse = [-1.39,0.34,-0.35,0.37,-1.06,0.51,-1.76,0.44,-0.86,0.28,-0.59,0.29]
d = []
dlow = []
dhigh = []
i = 0
while i < len(lse):
d.append(lse[i])
davg = lse[i]
i += 1
low = davg-1.96*lse[i]
dlow.append(low)
high = davg+1.96*lse[i]
dhigh.append(high)
i += 1
dlow_new = [round(x, 3) for x in dlow]
dhigh_new = [round(x, 3) for x in dhigh]
if mode > 3.5 and mode < 4.5:
lv = [0.1, 0.06, 0.8, 0.01, -0.2, 0.04]
lse = []
i = 0
while i < len(lv):
lse.append(lv[i])
i += 1
se = math.sqrt(lv[i])
lse.append(se)
i += 1
d =[]
dlow =[]
dhigh = []
i = 0
while i < len(lse):
d.append(lse[i])
davg = lse[i]
i += 1
low = davg-1.96*lse[i]
dlow.append(low)
high = davg+1.96*lse[i]
dhigh.append(high)
i += 1
lse_new = [round(x, 3) for x in lse]
dlow_new = [round(x, 3) for x in dlow]
dhigh_new = [round(x, 3) for x in dhigh]
if mode > 4.5 and mode < 5.5:
OR = [1.22, 1.65, 1.82]
ORlow = [0.93, 1.02, 1.33]
ORhigh = [1.92, 2.11, 2.67]
d = []
i = 0
while i < len(OR):
d_temp = math.log(OR[i])*0.5513
d.append(d_temp)
i += 1
dlow = []
i = 0
while i < len(OR):
dlow_temp = math.log(ORlow[i])*0.5513
dlow.append(dlow_temp)
i += 1
dhigh = []
i = 0
while i < len(OR):
dhigh_temp = math.log(ORhigh[i])*0.5513
dhigh.append(dhigh_temp)
i += 1
if mode > 5.5 and mode < 6.5:
ORl = [1.20,0.40,3.30,0.99,0.80,1.22,0.93,0.78,1.19,1.08,0.63,1.85,0.44,0.16,1.24,2.61,1.10,6.17,1.00,0.76,1.32,0.32,0.16,0.62,1.06,0.51,2.20,0.89,0.23,3.47,1.05,0.77,1.33,0.47,0.28,0.79,1.12,0.98,1.30,0.93,0.79,1.11]
d = []
dlow = []
dhigh = []
i = 0
while i < len(ORl):
temp = math.log(ORl[i])*0.5513
d.append(temp)
i += 1
temp = math.log(ORl[i])*0.5513
dlow.append(temp)
i += 1
temp = math.log(ORl[i])*0.5513
dhigh.append(temp)
i += 1
if mode > 6.5 and mode < 7.5:
r = [0.55,0.35,0.38]
rlow = [0.22,0.16,0.12]
rhigh = [0.72,0.58,0.67]
d = []
i = 0
while i < len(r):
d_temp = 2*r[i]/math.sqrt(1-r[i]**2)
d.append(d_temp)
i += 1
dlow = []
i = 0
while i < len(r):
dlow_temp = 2*rlow[i]/math.sqrt(1-rlow[i]**2)
dlow.append(dlow_temp)
i += 1
dhigh = []
i = 0
while i < len(r):
dhigh_temp = 2*rhigh[i]/math.sqrt(1-rhigh[i]**2)
dhigh.append(dhigh_temp)
i += 1
if mode > 7.5 and mode < 8.5:
rl = [0.55,0.22,0.72,0.35,0.16,0.58,0.38,0.12,0.67]
d = []
dlow = []
dhigh = []
i = 0
while i < len(rl):
temp = 2*rl[i]/math.sqrt(1-rl[i]**2)
d.append(temp)
i += 1
temp = 2*rl[i]/math.sqrt(1-rl[i]**2)
dlow.append(temp)
i += 1
temp = 2*rl[i]/math.sqrt(1-rl[i]**2)
dhigh.append(temp)
i += 1
print('RCT Inputs:')
print()
print('Effect Sizes d:')
print(d)
print()
print('Lower Limits of 95 % CI:')
print(dlow)
print()
print('Upper Limits of 95 % CI:')
print(dhigh)
print()
print()
# Fixed-Effects Mode: 1 = activated, 0 = deactivated
fixed_mode = 0
# k_test check to prevent error
if k_test > len(d):
k_test = len(d)
print('+++ Number of RCTs for restricted analysis greater than number of RCTs')
print('+++ Number of RCTs for restricted analysis set to number of RCTs')
print()
print()
# k_test check to prevent error
if k_test < 1:
k_test = 3
print('+++ Number of RCTs for restricted analysis smaller than one')
print('+++ Number of RCTs for restricted analysis set to three')
print()
print()
# ind_bias check to prevent error
if len(ind_bias) > len(d) or len(ind_bias) < len(d):
ind_bias = []
print('+++ Specified bias list not equal in size to effect size list')
print('+++ Specified bias list emptied')
print()
print()
# year check to prevent error
if len(year) > len(d) or len(year) < len(d):
year = []
print('+++ Year list not equal in size to effect size list')
print('+++ Year list emptied')
print()
print()
# lower limit check to prevent error
if len(dlow) > len(d) or len(dlow) < len(d):
print('+++ Lower limit list not equal in size to effect size list')
print('+++ Terminating Program')
print()
print()
sys.exit()
# upper limit check to prevent error
if len(dhigh) > len(d) or len(dhigh) < len(d):
print('+++ Upper limit list not equal in size to effect size list')
print('+++ Terminating Program')
print()
print()
sys.exit()
# adjustment for individual bias
if len(ind_bias) > 0:
i = 0
while i < len(d):
se_here = (abs(dhigh[i]-dlow[i])/3.92)
se_adj = ind_bias[i]*se_here
dlow[i] = d[i]-1.96*se_adj
dhigh[i] = d[i]+1.96*se_adj
i += 1
formatted_dlow = [ round(elem, 2) for elem in dlow ]
formatted_dhigh = [ round(elem, 2) for elem in dhigh ]
print('Individual Bias Adjusted RCT Results:')
print()
print('Effect Sizes d:')
print(d)
print()
print('Lower Limits of 95 % CI:')
print(formatted_dlow)
print()
print('Upper Limits of 95 % CI:')
print(formatted_dhigh)
print()
print()
print('------------------------------------')
print(u'\u2022'u'\u2022'u'\u2022'' RANDOM-EFFECTS META-ANALYSIS 'u'\u2022'u'\u2022'u'\u2022')
print('------------------------------------')
print()
def w(x, y):
w = 1/((abs(x-y)/3.92)**2)
return w
wsum = 0
i = 0
while i < len(d):
wsum = wsum + w(dlow[i], dhigh[i])
i += 1
q1sum = 0
i = 0
while i < len(d):
q1sum = q1sum + w(dlow[i], dhigh[i])*d[i]**2
i += 1
q2sum = 0
i = 0
while i < len(d):
q2sum = q2sum + w(dlow[i], dhigh[i])*d[i]
i += 1
Q = q1sum - (q2sum**2)/wsum
c1sum = 0
i = 0
while i < len(d):
c1sum = c1sum + w(dlow[i], dhigh[i])**2
i += 1
C = wsum - c1sum/wsum
df = len(d) - 1
tau_squared_prelim = (Q-df)/C
if tau_squared_prelim < 0:
tau_squared = 0
else:
tau_squared = tau_squared_prelim
if fixed_mode > 0:
tau_squared = 0
I_squared_prelim = 100*(Q-df)/Q
if I_squared_prelim < 0:
I_squared = 0
else:
I_squared = I_squared_prelim
if fixed_mode > 0:
I_squared = 0
Q = 0
print('(Forcing Fixed-Effects Analysis)')
print()
# General Information
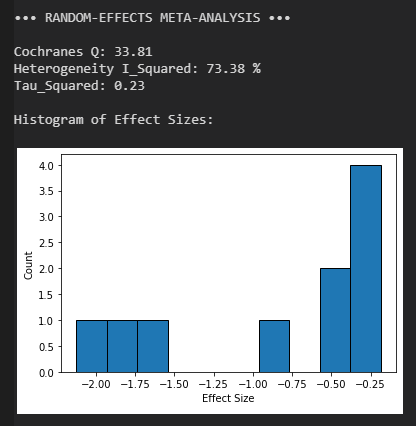
print('Cochranes Q:', "%.2f" % Q)
print('Heterogeneity I_Squared:', "%.2f" % I_squared, '%')
print('Tau_Squared:', "%.2f" % tau_squared)
print()
print('Histogram of Effect Sizes:')
print()
plt.hist(d, density=False, bins=len(d), ec='black')
plt.ylabel('Count')
plt.xlabel('Effect Size')
plt.show()
print()
v = 1/wsum
n_total = 4/v
n_avg = n_total/len(d)
# random-effects meta-analysis
def g(x, y):
g = 1/((abs(x-y)/3.92)**2+tau_squared)
return g
gsum = 0
i = 0
while i < len(d):
gsum = gsum + g(dlow[i], dhigh[i])
i += 1
v = 1/gsum
se = math.sqrt(v)
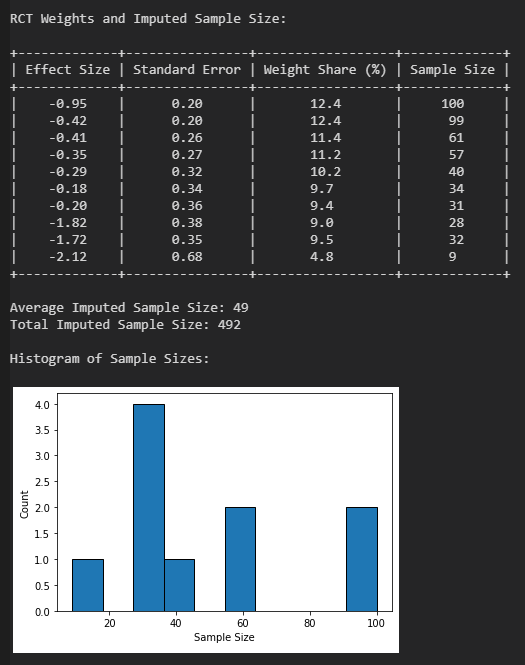
print('RCT Weights and Imputed Sample Size:')
print()
t1 = PrettyTable(['Effect Size', 'Standard Error', 'Weight Share (%)', 'Sample Size'])
nhisto = []
i = 0
while i < len(d):
gprint = g(dlow[i], dhigh[i])
gshare = 100*gprint/gsum
wprint = w(dlow[i], dhigh[i])
vprint = 1/wprint
nprint = round(4/vprint,0)
nhisto.append(nprint)
dprint = d[i]
seprint = abs(dlow[i]-dhigh[i])/3.92
t1.add_row(["%+.2f" % dprint,"%.2f" % seprint,"%.1f" % gshare,"%.0f" % nprint])
i += 1
print(t1)
print()
print('Average Imputed Sample Size:', "%.0f" % n_avg)
print('Total Imputed Sample Size:', "%.0f" % n_total)
print()
print('Histogram of Sample Sizes:')
print()
plt.hist(nhisto, density=False, bins=len(nhisto),ec='black')
plt.ylabel('Count')
plt.xlabel('Sample Size')
plt.show()
print()
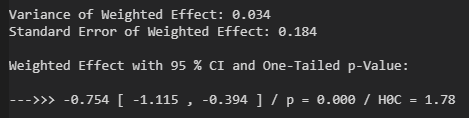
print('Variance of Weighted Effect:', "%.3f" % v)
print('Standard Error of Weighted Effect:', "%.3f" % se)
print()
# calculation of final results
dsum = 0
i = 0
while i < len(d):
dsum = dsum + g(dlow[i], dhigh[i])*d[i]
i += 1
davg = dsum/gsum
dlower = davg - 1.96*se
dupper = davg + 1.96*se
z = abs(davg/se)
p = scipy.stats.norm.sf(z)
c = abs(davg/(1.96*se)*0.85)
print('Weighted Effect with 95 % CI and One-Tailed p-Value:')
print()
print('--->>> d =', "%+.3f" % davg, '[', "%+.3f" % dlower, ',', "%+.3f" % dupper, '] / p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print()
OR = math.exp(davg*1.8138)
ORlower = math.exp(dlower*1.8138)
ORupper = math.exp(dupper*1.8138)
print('--->>> OR =', "%.3f" % OR, '[', "%.3f" % ORlower, ',', "%.3f" % ORupper, '] and p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print()
r = davg/math.sqrt(davg**2+4)
rlower = dlower/math.sqrt(dlower**2+4)
rupper = dupper/math.sqrt(dupper**2+4)
print('--->>> r =', "%+.3f" % r, '[', "%+.3f" % rlower, ',', "%+.3f" % rupper, '] and p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print()
# ------ Random-Effects Meta-Analysis Restricted to Largest RCTs ------
davg_uncorrected = davg
dlower_uncorrected = dlower
dupper_uncorrected = dupper
se_uncorrected = se
print()
print()
se_critical = 0.12
print('-----------------------------------------------------------')
print(u'\u2022'u'\u2022'u'\u2022'' RANDOM-EFFECTS META-ANALYSIS RESTRICTED TO TOP RCTs 'u'\u2022'u'\u2022'u'\u2022')
print('-----------------------------------------------------------')
print()
# ordered list creation
dtemp = list(d)
dlowtemp = list(dlow)
dhightemp = list(dhigh)
sort = []
sortlow = []
sorthigh = []
u = 1
while u < (k_test+1):
se_min = 100
i_min = 0
i = 0
while i < len(dtemp):
se_test = abs(dhightemp[i]-dlowtemp[i])/3.92
if se_test < se_min:
i_min = i
se_min = se_test
i += 1
sort.append(dtemp[i_min])
sortlow.append(dlowtemp[i_min])
sorthigh.append(dhightemp[i_min])
dtemp.pop(i_min)
dlowtemp.pop(i_min)
dhightemp.pop(i_min)
u +=1
print('Top RCTs Effect Size, SE and Imputed Sample Size:')
print()
t2 = PrettyTable(['Effect Size', 'Standard Error', 'Weight Share (%)', 'Sample Size'])
gsum = 0
i = 0
while i < k_test:
gsum = gsum + g(sortlow[i], sorthigh[i])
i += 1
i = 0
while i < k_test:
se_test = abs(sorthigh[i]-sortlow[i])/3.92
gprint = g(sortlow[i], sorthigh[i])
gshare = 100*gprint/gsum
wprint = w(sortlow[i], sorthigh[i])
vprint = 1/wprint
nprint = 4/vprint
t2.add_row(["%+.2f" % sort[i], "%.2f" % se_test, "%.1f" % gshare, "%.0f" % nprint])
i += 1
print(t2)
print()
d_original = list(d)
dlow_original = list(dlow)
dhigh_original = list(dhigh)
d = list(sort)
dlow = list(sortlow)
dhigh = list(sorthigh)
# Bias Testing
v = 1/gsum
se = math.sqrt(v)
dsum = 0
i = 0
while i < k_test:
dsum = dsum + g(dlow[i], dhigh[i])*d[i]
i += 1
davg = dsum/gsum
d_test = davg
dlower = davg - 1.96*se_uncorrected
dupper = davg + 1.96*se_uncorrected
z = abs(davg/se_uncorrected)
p = scipy.stats.norm.sf(z)
c = abs(davg/(1.96*se_uncorrected)*0.85)
print('Top Analysis with Shifted 95 % CI:')
print()
print('--->>> d =', "%+.3f" % davg, '[', "%+.3f" % dlower, ',', "%+.3f" % dupper, '] and p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print()
OR = math.exp(davg*1.8138)
ORlower = math.exp(dlower*1.8138)
ORupper = math.exp(dupper*1.8138)
print('--->>> OR =', "%.3f" % OR, '[', "%.3f" % ORlower, ',', "%.3f" % ORupper, '] and p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print()
r = davg/math.sqrt(davg**2+4)
rlower = dlower/math.sqrt(dlower**2+4)
rupper = dupper/math.sqrt(dupper**2+4)
print('--->>> r =', "%+.3f" % r, '[', "%+.3f" % rlower, ',', "%+.3f" % rupper, '] and p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print()
z_bias = abs((davg_uncorrected-davg)/se_critical)
p_bias = scipy.stats.norm.sf(z_bias)
print()
print('Difference to Calculated Effect: d =', "%.3f" % davg_uncorrected, '/ Z =', "%.3f" % z_bias, '/ p =', "%.3f" % p_bias)
davg_corrected = davg
print()
if p_bias >= 0.1:
print('--->>> Influence of Publication Bias on Effect Size is NOT SIGNIFICANT')
if p_bias < 0.1 and p_bias >= 0.05:
print('--->>> Influence of Publication Bias on Effect Size APPROACHES SIGNIFICANCE')
if p_bias < 0.05 and p_bias >= 0.01:
print('--->>> Influence of Publication Bias on Effect Size is SIGNIFICANT AT p < 0.05')
if p_bias < 0.01 and p_bias >= 0.001:
print('--->>> Influence of Publication Bias on Effect Size is SIGNIFICANT AT p < 0.01')
if p_bias < 0.001:
print('--->>> Influence of Publication Bias on Effect Size is SIGNIFICANT AT p < 0.001')
print()
if c >= 1.1:
print('--->>> Influence of Publication Bias on H0 Rejection is NOT CRITICAL')
if c < 1.1 and c >= 1.0:
print('--->>> Influence of Publication Bias on H0 Rejection APPROACHES CRITICALITY')
if c < 1.0 and c >= 0.9:
print('--->>> Influence of Publication Bias on H0 Rejection is CRITICAL')
if c < 0.9 and c >= 0.8:
print('--->>> Influence of Publication Bias on H0 Rejection is HIGHLY CRITICAL')
if c < 0.8:
print('--->>> Influence of Publication Bias on H0 Rejection is SEVERE')
print()
means = [davg_uncorrected, davg]
ci = [(dlower_uncorrected, dupper_uncorrected), (dlower, dupper)]
y_r = [means[i] - ci[i][1] for i in range(len(ci))]
plt.bar(range(len(means)), means, yerr=y_r, align='center', error_kw=dict(lw=2, capsize=5, capthick=2))
plt.xticks(range(len(means)), ['Original Effect','Corrected Effect'])
x = np.linspace(-0.5, len(means)-0.5)
y = 0*x
plt.plot(x, y, 'black', linewidth=0.5)
plt.show()
d = list(d_original)
dlow = list(dlow_original)
dhigh = list(dhigh_original)
print()
print()
print()
print('------------------------------------------------------------------------')
print(u'\u2022'u'\u2022'u'\u2022'' FUNNEL PLOT (D-SE) ANALYSIS CENTERED ON TOP ANALYSIS EFFECT SIZE 'u'\u2022'u'\u2022'u'\u2022')
print('------------------------------------------------------------------------')
print()
j = 0
epos = []
xpos = []
while j < len(d):
if d[j]-d_test >= 0:
epos.append(d[j]-d_test)
xpos.append(abs(dhigh[j]-dlow[j])/3.92)
j += 1
if len(epos) > 0:
t3 = PrettyTable(['Standard Error', 'Centered Effect Size'])
j = 0
while j < len(epos):
t3.add_row(["%+.2f" % xpos[j], "%+.2f" % epos[j]])
j += 1
print(t3)
xpos_max = 0
j = 0
while j < len(epos):
if xpos[j] > xpos_max:
xpos_max = xpos[j]
j += 1
productsum = 0
xsquaresum = 0
j = 0
while j < len(epos):
productsum = productsum + xpos[j]*epos[j]
xsquaresum = xsquaresum + xpos[j]**2
j += 1
slope_pos = productsum/xsquaresum
print()
print('Above Effect Funnel Plot:')
print()
plt.scatter(xpos, epos)
plt.title("Above Effect Funnel Plot")
plt.xlabel("Standard Error")
plt.ylabel("Centered Effect Size")
plt.xlim(0, xpos_max+0.05)
x = np.linspace(0, xpos_max+0.05)
y = slope_pos*x
plt.plot(x, y)
plt.show()
print()
print('---> Above Test Effect Zero Intercept SLOPE: ' "%+.3f" % slope_pos)
print()
print()
else:
print()
print('UNABLE TO CALCULATE Above Test Effect Regression Line')
print()
j = 0
eneg = []
xneg = []
while j < len(d):
if d[j]-d_test <= 0:
eneg.append(d[j]-d_test)
xneg.append(abs(dhigh[j]-dlow[j])/3.92)
j += 1
if len(eneg) > 0:
t4 = PrettyTable(['Standard Error', 'Centered Effect Size'])
j = 0
while j < len(eneg):
t4.add_row(["%+.2f" % xneg[j], "%+.2f" % eneg[j]])
j += 1
print(t4)
productsum = 0
xsquaresum = 0
j = 0
while j < len(eneg):
productsum = productsum + xneg[j]*eneg[j]
xsquaresum = xsquaresum + xneg[j]**2
j += 1
slope_neg = productsum/xsquaresum
xneg_max = 0
j = 0
while j < len(eneg):
if xneg[j] > xneg_max:
xneg_max = xneg[j]
j += 1
print()
print('Below Effect Funnel Plot:')
print()
plt.scatter(xneg, eneg)
plt.title("Above Effect Funnel Plot")
plt.xlabel("Standard Error")
plt.ylabel("Centered Effect Size")
plt.xlim(0, xneg_max+0.05)
x = np.linspace(0, xneg_max+0.05)
y = slope_neg*x
plt.plot(x, y)
plt.show()
print()
print('---> Below Test Effect Zero Intercept SLOPE: ' "%+.3f" % slope_neg)
print()
print()
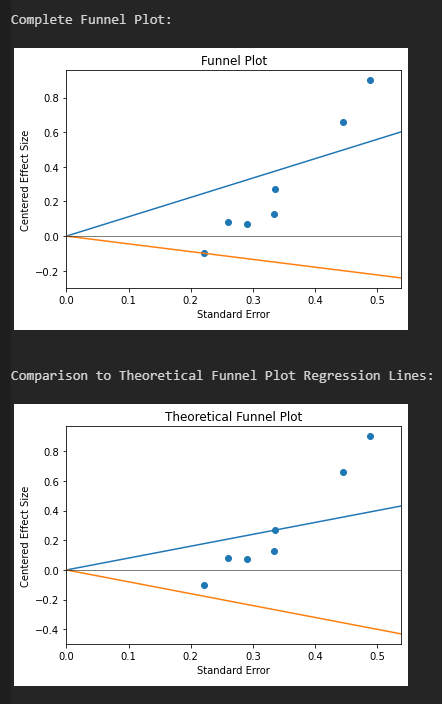
print('Complete Funnel Plot:')
print()
x = xneg+xpos
e = eneg+epos
if xneg_max > xpos_max:
xmax = xneg_max
else:
xmax = xpos_max
plt.scatter(x, e)
plt.title("Funnel Plot")
plt.xlabel("Standard Error")
plt.ylabel("Centered Effect Size")
plt.xlim(0, xmax+0.05)
x = np.linspace(0, xmax+0.05)
y = slope_pos*x
plt.plot(x, y)
x = np.linspace(0, xmax+0.05)
y = slope_neg*x
plt.plot(x, y)
x = np.linspace(0, xmax+0.05)
y = 0*x
plt.plot(x, y,'black', linewidth=0.5)
plt.show()
print()
x = xneg+xpos
e = eneg+epos
print()
print('Comparison to Theoretical Funnel Plot Regression Lines:')
print()
plt.scatter(x, e)
plt.title("Theoretical Funnel Plot")
plt.xlabel("Standard Error")
plt.ylabel("Centered Effect Size")
plt.xlim(0, xmax+0.05)
x = np.linspace(0, xmax+0.05)
y = 0.8*x
plt.plot(x, y)
x = np.linspace(0, xmax+0.05)
y = -0.8*x
plt.plot(x, y)
x = np.linspace(0, xmax+0.05)
y = 0*x
plt.plot(x, y, 'black', linewidth=0.5)
plt.show()
from statsmodels.nonparametric.kernel_regression import KernelReg
X = xneg+xpos
Y = eneg+epos
# Combine lists into list of tuples
points = zip(X, Y)
# Sort list of tuples by x-value
points = sorted(points, key=lambda point: point[0])
# Split list of tuples into two list of x values any y values
X, Y = zip(*points)
print()
print()
print('Funnel Plot Interpolation:')
print()
kr = KernelReg(Y,X,'o')
y_pred, y_std = kr.fit(X)
plt.xlim(0, xmax+0.05)
plt.scatter(X,Y, s = 20)
plt.title("Funnel Plot")
plt.xlabel("Standard Error")
plt.ylabel("Centered Effect Size")
x = np.linspace(0, xmax+0.05)
y = 0*x
plt.plot(x, y, 'black', linewidth=0.5)
plt.plot(X, y_pred, color = 'orange')
plt.show()
print()
print('R_Squared =',"%.2f" % kr.r_squared())
print()
else:
print()
print('UNABLE TO CALCULATE Below Test Effect Regression Line')
print()
if len(epos) > 0 and len(eneg) > 0:
if davg_uncorrected > 0:
if abs(slope_neg) > slope_pos:
prob = 100
else:
prob = 100*(0.3*math.exp(-abs(slope_neg))+abs(slope_neg))/(0.3*math.exp(-abs(slope_pos))+slope_pos)
else:
if slope_pos > abs(slope_neg):
prob = 100
else:
prob = 100*(0.3*math.exp(-abs(slope_pos))+slope_pos)/(0.3*math.exp(-abs(slope_neg))+abs(slope_neg))
print()
slope_diff = slope_pos-abs(slope_neg)
print(u'\u2022'' TEST FOR FUNNEL PLOT ASYMMETRIES:')
print()
print()
print('Slopes: ' "%.3f" % slope_pos, 'Above Effect versus', "%.3f" % slope_neg, 'Below Effect')
print('Slope Difference: ' "%.3f" % slope_diff)
print()
print('---> Estimated Probability of Publishing Undesired Result:', "%.0f" % prob, '%')
if prob >= 83:
print('---> Slope Asymmetry Implies INSIGNIFICANT Publication Bias')
if prob < 83 and prob >= 65:
print('---> Slope Asymmetry Implies SLIGHT Publication Bias')
if prob < 65 and prob >= 48:
print('---> Slope Asymmetry Implies MODERATE Publication Bias')
if prob < 48 and prob >= 30:
print('---> Slope Asymmetry Implies STRONG Publication Bias')
if prob < 30:
print('---> Slope Asymmetry Implies SEVERE Publication Bias')
print()
else:
print()
print('UNABLE TO CALCULATE Slope Difference')
print()
if len(epos) > 0 and len(eneg) > 0:
ipos = len(xpos)
ineg = len(xneg)
iref = max(ipos,ineg)
n_diff_raw = 100*(ipos-ineg)/iref
n_diff = 100*(ipos-ineg)/(iref+2)
print()
print('RCT Counts: ' "%.0f" % ipos, 'Above Effect versus', "%.0f" % ineg, 'Below Effect')
print('RCT Count Asymmetry Raw: ' "%+.0f" % n_diff_raw, '%')
print('RCT Count Asymmetry Corrected: ' "%+.0f" % n_diff, '%')
if davg_uncorrected > 0:
if n_diff < 0:
prob1 = 100
else:
prob1 = 100-n_diff
else:
if n_diff > 0:
prob1 = 100
else:
prob1 = 100-abs(n_diff)
print()
print('---> Estimated Probability of Publishing Undesired Result:', "%.0f" % prob1, '%')
if prob1 >= 83:
print('---> RCT Count Asymmetry Implies INSIGNIFICANT Publication Bias')
if prob1 < 83 and prob1 >= 65:
print('---> RCT Count Asymmetry Implies SLIGHT Publication Bias')
if prob1 < 65 and prob1 >= 48:
print('---> RCT Count Asymmetry Implies MODERATE Publication Bias')
if prob1 < 48 and prob1 >= 30:
print('---> RCT Count Asymmetry Implies STRONG Publication Bias')
if prob1 < 30:
print('---> RCT Count Asymmetry Implies SEVERE Publication Bias')
print()
outlierpos = 0
j = 0
while j < len(epos):
if epos[j] > 0.5:
outlierpos = outlierpos + 1
j += 1
outlierneg = 0
j = 0
while j < len(eneg):
if eneg[j] < -0.5:
outlierneg = outlierneg + 1
j += 1
iref = max(outlierpos,outlierneg)
if iref <= 0: iref = 1
outlier_diff_raw = 100*(outlierpos-outlierneg)/iref
outlier_diff = 100*(outlierpos-outlierneg)/(iref+1)
print()
print('RCT Outlier Counts: ' "%.0f" % outlierpos, 'Above Effect versus', "%.0f" % outlierneg, 'Below Effect')
print('Outlier Asymmetry Raw: ' "%+.0f" % outlier_diff_raw, '%')
print('Outlier Asymmetry Corrected: ' "%+.0f" % outlier_diff, '%')
if davg_uncorrected > 0:
if outlier_diff < 0:
prob2 = 100
else:
prob2 = 100-outlier_diff
else:
if outlier_diff > 0:
prob2 = 100
else:
prob2 = 100-abs(outlier_diff)
print()
print('---> Estimated Probability of Publishing Undesired Result:', "%.0f" % prob2, '%')
if prob2 >= 83:
print('---> Outlier Asymmetry Implies INSIGNIFICANT Publication Bias')
if prob2 < 83 and prob2 >= 65:
print('---> Outlier Asymmetry Implies SLIGHT Publication Bias')
if prob2 < 65 and prob2 >= 48:
print('---> Outlier Asymmetry Implies MODERATE Publication Bias')
if prob2 < 48 and prob2 >= 30:
print('---> Outlier Asymmetry Implies STRONG Publication Bias')
if prob2 < 30:
print('---> Outlier Asymmetry Implies SEVERE Publication Bias')
print()
distance_pos = 0
j = 0
while j < len(epos):
distance_pos = distance_pos+epos[j]
j += 1
distance_neg = 0
j = 0
while j < len(eneg):
distance_neg = distance_neg+eneg[j]
j += 1
distance_ref = max(distance_pos,abs(distance_neg))
distance_diff_raw = 100*(distance_pos+distance_neg)/distance_ref
distance_diff = 100*(distance_pos+distance_neg)/(distance_ref+0.4)
print()
print('Effect Distance Sums: ' "%.2f" % distance_pos, 'Above Effect versus', "%.2f" % distance_neg, 'Below Effect')
print('Effect Distance Sum Asymmetry Raw: ' "%+.0f" % distance_diff_raw, '%')
print('Effect Distance Sum Asymmetry Corrected: ' "%+.0f" % distance_diff, '%')
if davg_uncorrected > 0:
if distance_diff < 0:
prob3 = 100
else:
prob3 = 100-abs(distance_diff)
else:
if distance_diff > 0:
prob3 = 100
else:
prob3 = 100-abs(distance_diff)
print()
print('---> Estimated Probability of Publishing Undesired Result:', "%.0f" % prob3, '%')
if prob3 >= 83:
print('---> Effect Distance Sum Asymmetry Implies INSIGNIFICANT Publication Bias')
if prob3 < 83 and prob3 >= 65:
print('---> Effect Distance Sum Asymmetry Implies SLIGHT Publication Bias')
if prob3 < 65 and prob3 >= 48:
print('---> Effect Distance Sum Asymmetry Implies MODERATE Publication Bias')
if prob3 < 48 and prob3 >= 30:
print('---> Effect Distance Sum Asymmetry Implies STRONG Publication Bias')
if prob3 < 30:
print('---> Effect Distance Sum Asymmetry Implies SEVERE Publication Bias')
print()
epos_max = 0
j = 0
while j < len(epos):
if epos[j] > epos_max:
epos_max = epos[j]
j += 1
eneg_max = 0
j = 0
while j < len(eneg):
if eneg[j] < eneg_max:
eneg_max = eneg[j]
j += 1
maxeffect_ref = max(epos_max,abs(eneg_max))
maxeffect_diff_raw = 100*(epos_max+eneg_max)/maxeffect_ref
maxeffect_diff = 100*(epos_max+eneg_max)/(maxeffect_ref+0.1)
print()
print('Effect Ranges: ' "%.2f" % epos_max, 'Above Effect versus', "%.2f" % eneg_max, 'Below Effect')
print('Effect Range Asymmetry Raw: ' "%+.0f" % maxeffect_diff_raw, '%')
print('Effect Range Asymmetry Corrected: ' "%+.0f" % maxeffect_diff, '%')
if davg_uncorrected > 0:
if maxeffect_diff < 0:
prob4 = 100
else:
prob4 = 100-abs(maxeffect_diff)
else:
if maxeffect_diff > 0:
prob4 = 100
else:
prob4 = 100-abs(maxeffect_diff)
print()
print('---> Estimated Probability of Publishing Undesired Result:', "%.0f" % prob4, '%')
if prob4 >= 83:
print('---> Effect Range Asymmetry Implies INSIGNIFICANT Publication Bias')
if prob4 < 83 and prob4 >= 65:
print('---> Effect Range Asymmetry Implies SLIGHT Publication Bias')
if prob4 < 65 and prob4 >= 48:
print('---> Effect Range Asymmetry Implies MODERATE Publication Bias')
if prob4 < 48 and prob4 >= 30:
print('---> Effect Range Asymmetry Implies STRONG Publication Bias')
if prob4 < 30:
print('---> Effect Range Asymmetry Implies SEVERE Publication Bias')
print()
gw = (100/prob)**1.33
gw1 = (100/prob1)**1.33
gw2 = (100/prob2)**1.33
gw3 = (100/prob3)**1.33
gw4 = (100/prob4)**1.33
gwsum = gw + gw1 + gw2 + gw3 + gw4
prob_mean = (gw*prob+gw1*prob1+gw2*prob2+gw3*prob3+gw4*prob4)/gwsum
ugw = (100/prob)
ugw1 = (100/prob1)
ugw2 = (100/prob2)
ugw3 = (100/prob3)
ugw4 = (100/prob4)
ugwsum = ugw + ugw1 + ugw2 + ugw3 + ugw4
uvar = 1/ugwsum
use = 100*math.sqrt(uvar)
prob_lower = prob_mean - 0.75*use
prob_upper = prob_mean + 0.75*use
print()
print(u'\u2022'' COMBINED FUNNEL PLOT ANALYSIS:')
print()
print('--->>> Estimated Probability of Publishing Undesired Result:', "%.0f" % prob_mean, '% [', "%.0f" % prob_lower, '% ,', "%.0f" % prob_upper, '% ]')
if prob_mean >= 83:
print('--->>> Funnel Plot Analysis Implies INSIGNIFICANT Publication Bias')
if prob_mean < 83 and prob_mean >= 65:
print('--->>> Funnel Plot Analysis Implies SLIGHT Publication Bias')
if prob_mean < 65 and prob_mean >= 48:
print('--->>> Funnel Plot Analysis Implies MODERATE Publication Bias')
if prob_mean < 48 and prob_mean >= 30:
print('--->>> Funnel Plot Analysis Implies STRONG Publication Bias')
if prob_mean < 30:
print('--->>> Funnel Plot Analysis Implies SEVERE Publication Bias')
else:
print()
print('UNABLE TO CALCULATE Asymmetries')
print()
print()
print('Imputed Probabilities of Publishing Undesired Results:')
print()
means = [prob, prob1, prob2, prob3, prob4, prob_mean]
ci = [(prob,prob),(prob1,prob1),(prob2,prob2),(prob3,prob3),(prob4,prob4), (prob_lower, prob_upper)]
y_r = [means[i] - ci[i][1] for i in range(len(ci))]
plt.bar(range(len(means)), means, yerr=y_r, align='center', error_kw=dict(lw=2, capsize=5, capthick=2))
plt.xticks(range(len(means)), ['Slopes','Counts', 'Outliers', 'Distances', 'Ranges', 'Combined'])
plt.show()
print()
print()
print()
print('--------------------------------------------------')
print(u'\u2022'u'\u2022'u'\u2022'' SENSITIVITY ANALYSIS OF FULL META-ANALYSIS 'u'\u2022'u'\u2022'u'\u2022')
print('--------------------------------------------------')
print()
dremain = []
dlowerremain = []
dupperremain = []
changesum = 0
changemax = 0
minhoc = 100
n = 0
while n < len(d_original):
d = list(d_original)
dlow = list(dlow_original)
dhigh = list(dhigh_original)
del d[n]
del dlow[n]
del dhigh[n]
wsum = 0
i = 0
while i < len(d):
wsum = wsum + w(dlow[i], dhigh[i])
i += 1
q1sum = 0
i = 0
while i < len(d):
q1sum = q1sum + w(dlow[i], dhigh[i])*d[i]**2
i += 1
q2sum = 0
i = 0
while i < len(d):
q2sum = q2sum + w(dlow[i], dhigh[i])*d[i]
i += 1
Q = q1sum - (q2sum**2)/wsum
c1sum = 0
i = 0
while i < len(d):
c1sum = c1sum + w(dlow[i], dhigh[i])**2
i += 1
C = wsum - c1sum/wsum
df = len(d) - 1
tau_squared_prelim = (Q-df)/C
if tau_squared_prelim < 0:
tau_squared = 0
else:
tau_squared = tau_squared_prelim
if fixed_mode > 0:
tau_squared = 0
I_squared_prelim = 100*(Q-df)/Q
if I_squared_prelim < 0:
I_squared = 0
else:
I_squared = I_squared_prelim
if fixed_mode > 0:
I_squared = 0
Q = 0
# random-effects meta-analysis
gsum = 0
i = 0
while i < len(d):
gsum = gsum + g(dlow[i], dhigh[i])
i += 1
v = 1/gsum
se = math.sqrt(v)
# calculation of final results
dsum = 0
i = 0
while i < len(d):
dsum = dsum + g(dlow[i], dhigh[i])*d[i]
i += 1
davg = dsum/gsum
dremain.append(davg)
dlower = davg - 1.96*se
dupper = davg + 1.96*se
dlowerremain.append(dlower)
dupperremain.append(dupper)
z = abs(davg/se)
p = scipy.stats.norm.sf(z)
c = abs(davg/(1.96*se)*0.85)
if c < minhoc:
minhoc = c
change = 100*(davg-davg_uncorrected)/davg_uncorrected
changesum = changesum + abs(change)
if abs(change) > changemax:
changemax = abs(change)
print('--->>> d =', "%+.3f" % davg, '[', "%+.3f" % dlower, ',', "%+.3f" % dupper, '] / p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print('--->>> Change to Uncorrected Effect:', "%+.1f" % change, '%')
print()
n += 1
print('Plot for Remaining Effect Size after Removing the n-th RCT:')
print()
means = []
labels = []
n = 0
while n < len(dremain):
means.append(dremain[n])
labels.append(n+1)
n += 1
ci = []
n = 0
while n < len(dremain):
ci.append((dlowerremain[n],dupperremain[n]))
n += 1
y_r = [means[i] - ci[i][1] for i in range(len(ci))]
plt.bar(range(len(means)), means, yerr=y_r, align='center', error_kw=dict(lw=2, capsize=5, capthick=2))
plt.xticks(range(len(means)), labels)
plt.axhline(y=davg_uncorrected,linewidth=1, color='red')
x = np.linspace(-1, len(dremain))
y = 0*x
plt.plot(x, y, 'black', linewidth=0.5)
plt.show()
changeavg = changesum/len(dremain)
print()
print('Average Absolute Change:', "%.1f" % changeavg, '%')
print('Maximum Absolute Change:', "%.1f" % changemax, '%')
print()
print('Minimum H0C:', "%.2f" % minhoc)
if k_test > 1:
print()
print()
print()
print('--------------------------------------------------------')
print(u'\u2022'u'\u2022'u'\u2022'' SENSITIVITY ANALYSIS OF RESTRICTED META-ANALYSIS 'u'\u2022'u'\u2022'u'\u2022')
print('--------------------------------------------------------')
print()
dremain = []
dlowerremain = []
dupperremain = []
changesum = 0
changemax = 0
minhoc = 100
n = 0
while n < len(sort):
d = list(sort)
dlow = list(sortlow)
dhigh = list(sorthigh)
del d[n]
del dlow[n]
del dhigh[n]
wsum = 0
i = 0
while i < len(d):
wsum = wsum + w(dlow[i], dhigh[i])
i += 1
q1sum = 0
i = 0
while i < len(d):
q1sum = q1sum + w(dlow[i], dhigh[i])*d[i]**2
i += 1
q2sum = 0
i = 0
while i < len(d):
q2sum = q2sum + w(dlow[i], dhigh[i])*d[i]
i += 1
Q = q1sum - (q2sum**2)/wsum
c1sum = 0
i = 0
while i < len(d):
c1sum = c1sum + w(dlow[i], dhigh[i])**2
i += 1
C = wsum - c1sum/wsum
df = len(d) - 1
if k_test > 2:
tau_squared_prelim = (Q-df)/C
if tau_squared_prelim < 0:
tau_squared = 0
else:
tau_squared = tau_squared_prelim
else:
tau_squared = 0
if fixed_mode > 0:
tau_squared = 0
if k_test > 2:
I_squared_prelim = 100*(Q-df)/Q
if I_squared_prelim < 0:
I_squared = 0
else:
I_squared = I_squared_prelim
else:
I_squared = 0
if fixed_mode > 0:
I_squared = 0
Q = 0
# random-effects meta-analysis
gsum = 0
i = 0
while i < len(d):
gsum = gsum + g(dlow[i], dhigh[i])
i += 1
v = 1/gsum
se = math.sqrt(v)
# calculation of final results
dsum = 0
i = 0
while i < len(d):
dsum = dsum + g(dlow[i], dhigh[i])*d[i]
i += 1
davg = dsum/gsum
dremain.append(davg)
dlower = davg - 1.96*se_uncorrected
dupper = davg + 1.96*se_uncorrected
dlowerremain.append(dlower)
dupperremain.append(dupper)
z = abs(davg/se_uncorrected)
p = scipy.stats.norm.sf(z)
c = abs(davg/(1.96*se_uncorrected)*0.85)
if c < minhoc:
minhoc = c
change = 100*(davg-davg_corrected)/davg_corrected
changesum = changesum + abs(change)
if abs(change) > changemax:
changemax = abs(change)
print('--->>> d =', "%+.3f" % davg, '[', "%+.3f" % dlower, ',', "%+.3f" % dupper, '] / p =', "%.3f" % p, '/ H0C =',"%.2f" % c)
print('--->>> Change to Corrected Effect:', "%+.1f" % change, '%')
print()
n += 1
print('Plot for Remaining Effect Size after Removing the n-th RCT:')
print()
means = []
labels = []
n = 0
while n < len(dremain):
means.append(dremain[n])
labels.append(n+1)
n += 1
ci = []
n = 0
while n < len(dremain):
ci.append((dlowerremain[n],dupperremain[n]))
n += 1
y_r = [means[i] - ci[i][1] for i in range(len(ci))]
plt.bar(range(len(means)), means, yerr=y_r, align='center', error_kw=dict(lw=2, capsize=5, capthick=2))
plt.xticks(range(len(means)), labels)
plt.axhline(y=davg_corrected,linewidth=1, color='red')
x = np.linspace(-1, len(dremain))
y = 0*x
plt.plot(x, y, 'black', linewidth=0.5)
plt.show()
changeavg = changesum/len(dremain)
print()
print('Average Absolute Change:', "%.1f" % changeavg, '%')
print('Maximum Absolute Change:', "%.1f" % changemax, '%')
print()
print('Minimum H0C:', "%.2f" % minhoc)
if len(year) > 0:
print()
print()
print()
print('---------------------------')
print(u'\u2022'u'\u2022'u'\u2022'' TIME-SERIES OF RCTS 'u'\u2022'u'\u2022'u'\u2022')
print('---------------------------')
print()
yearmin = 10000
i = 0
while i < len(d_original):
if year[i] < yearmin:
yearmin = year[i]
i += 1
yearmax = 0
i = 0
while i < len(d_original):
if year[i] > yearmax:
yearmax = year[i]
i += 1
print('Earliest RCT:', yearmin)
print('Most Recent RCT:',yearmax)
print()
yearrange = yearmax-yearmin
yearlist = []
i = 0
while i < yearrange+1:
yearlist.append(yearmin+i)
i += 1
numberstudies = []
i = 0
while i < yearrange+1:
number = year.count(yearmin+i)
numberstudies.append(number)
i += 1
print('Number of RCTs Over Time:')
print()
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
ax.bar(yearlist,numberstudies)
plt.show()
X = year
Y = d_original
print()
print('Linear Regression Test of Effect Sizes Over Time:')
model = sm.OLS(Y,sm.add_constant(X))
results = model.fit()
plt.scatter(X,Y, s = 20)
X_plot = np.linspace(yearmin-2,yearmax+2,100)
plt.plot(X_plot, results.params[0] + X_plot*results.params[1], color = 'orange')
print()
plt.show()
print()
print('Slope =', "%+.2f" % results.params[1], '/ p =', "%.3f" % results.pvalues[1])
print('R_Squared =',"%.2f" % results.rsquared)
print()
print('Interpolation of Effect Sizes Over Time:')
print()
from statsmodels.nonparametric.kernel_regression import KernelReg
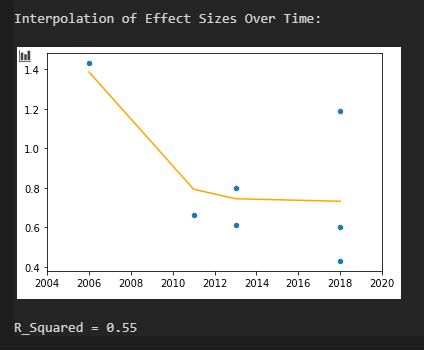
# Combine lists into list of tuples
points = zip(X, Y)
# Sort list of tuples by x-value
points = sorted(points, key=lambda point: point[0])
# Split list of tuples into two list of x values any y values
X, Y = zip(*points)
kr = KernelReg(Y,X,'o')
y_pred, y_std = kr.fit(X)
plt.xlim(yearmin-2, yearmax+2)
plt.scatter(X,Y, s = 20)
plt.plot(X, y_pred, color = 'orange')
plt.show()
print()
print('R_Squared =',"%.2f" % kr.r_squared())
Der Begriff “Mindfulness-Paradoxon”, den ich gerade eben erfunden habe, bezieht sich auf einen interessanten statistischen Scheinwiderspruch, den man ziemlich häufig beim Vergleich von kontrollierten Experimenten und Beobachtungsstudien findet. Dieser ist nicht begrenzt auf Mindfulness, aber Mindfulness bietet ein schönes Beispiel dafür. Hier zwei einfache und leicht nachweisbare Fakten über Mindfulness:
Kontrollierte Experimente (Behandlungs- versus Placebogruppe) zeigen, dass Mindfulness eine effektive Möglichkeit zur Senkung von Neurotizismus ist.
In Beobachtungsstudien (Umfragen) zeigt sich, dass Mindfulness positiv mit Neurotizismus assoziiert ist. Leute, die viel Mindfulness betreiben, sind im Mittel neurotischer (!) als jene, die es nicht tun.
Das beißt sich auf den ersten Blick: Mindfulness senkt Neurotizismus, Leute die häufig Mindfulness betreiben sind aber im Mittel neurotischer als andere. Mit einer numerischen Simulation lässt sich aber zeigen, dass diese beiden Fakten nur auf den ersten Blick widersprüchlich sind. Tatsächlich passt das ganz wundervoll zusammen.
Wer betreibt Mindfulness? Der Einfachheit halber die Beschränkung auf zwei Motivationen: Interesse, Leidensdruck. Manche machen es aus reinem Interesse, ohne es als ein Werkzeug zur Bekämpfung psychischer Probleme aufzufassen. Andere machen es, um den Leidensdruck infolge von hohem Neurotizismus zu senken. Und da steckt eigentlich schon des Rätsels Lösung: Je neurotischer eine Person, desto höher die Wahrscheinlichkeit, dass diese Person irgendwann Mindfulness probiert und ins Leben integriert. Aus letzterem ergibt sich dann eine Senkung des Neurotizismus, das Niveau wird aber danach immer noch höher sein als bei jenem, der infolge von Abwesenheit von Leidensdrucks nie nach einer solcher Linderung gesucht hat.
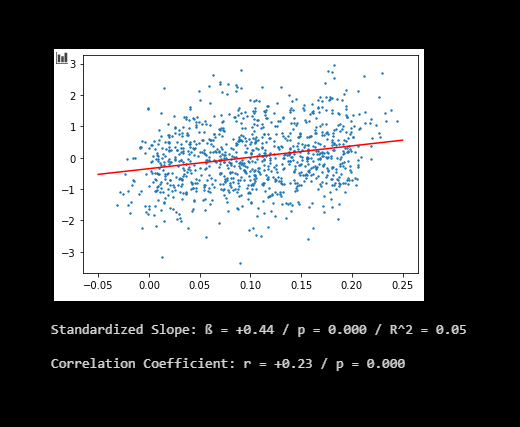
Hier der Prozess als numerische Simulation. Man sieht sehr schön, wie die positive Korrelation zwischen Mindfulness und Neurotizismus entsteht, obwohl Mindfulness effektiv Neurotizismus senkt. Betrachtet werden n = 1000 Leute. Jedem wird gemäß der Normalverteilung einen Neurotizismus-Wert zugewiesen.
import matplotlib.pyplot as plt
import math
import scipy.stats
import numpy as np
import statsmodels.api as sm
n = 1000
e = -1
neuro = np.random.normal(0,1,n)
Die Variable e soll die maximale Effektstärke einer Mindfulness-Intervention darstellen. Danach wird eine Training-Funktion definiert. Sie drückt aus, dass je neurotischer eine Person, desto höher die Wahrscheinlichkeit Mindfulness zu praktizieren. Mit p0 und p1 kann man die Funktion etwas steuern. p0 ist die Wahrscheinlichkeit bei mittlerem Neurotizismus (z = 0), p1 bei extremem Neurotizismus (z = 3). Man sieht, dass der Zusammenhang hier nicht Schwarz-Weiß ist. 10 % bei mittlerem Neurotizismus, 15 % im oberen Extrembereich.
Dann die eigentliche Simulation. Jedem wird ein neuer Neurotizismus-Wert zugewiesen, berechnet aus vorherigem Neurotizismus minus der eventuellen Wirkung aus Mindfulness-Training. Es wird berücksichtigt, dass nicht jeder strikt gemäß seinem Level an Neurotizismus Mindfulness trainiert (Zufallszahl a) und nicht jeder bei gleichem Level an Training denselben Effekt bekommt (Zufallszahl b). Dazu noch ein Term für die zufällige Wirkung anderer Dinge des Lebens auf den Neurotizimus (Zufallszahl eff_other).
neuro_new = []
training_level = []
i = 0
while i < n:
a = np.random.uniform(0.75,1.25)
k = np.random.uniform(-p0,p0)
b = np.random.uniform(0.75,1.25)
x = neuro[i]
tr_real = k+tr(x)*a
eff_real = tr_real*e*b
eff_other = np.random.uniform(-0.33,0.33)
neuro_new.append(x+eff_real+eff_other)
training_level.append(tr_real)
i += 1
Dann Regression, Plot und Angabe wichtiger Parameter:
X = training_level
Y = neuro
model = sm.OLS(Y,sm.add_constant(X))
results = model.fit()
print(results.summary())
plt.scatter(X,Y, s = 2)
X_plot = np.linspace(-0.05,p1+0.1,100)
plt.plot(X_plot, results.params[0] + X_plot*results.params[1], color = 'red')
print()
plt.show()
beta = results.params[1]*results.bse[0]/results.bse[1]
print()
print('Standardized Slope: ß =', "%+.2f" % beta, '/ p =', "%.3f" % results.pvalues[1], '/ R^2 =',"%.2f" % results.rsquared)
print()
r = scipy.stats.pearsonr(training_level, neuro)
print('Correlation Coefficient: r =', "%+.2f" % r[0], '/ p =', "%.3f" % r[1])
Es kommt dieses schöne Resultat dabei raus:
Für jede Person, die Mindfulness betrieben hat, hat sich der Neurotizismus gesenkt. Am Ende bleibt trotz dieser hilfreichen Wirkung eine positive Korrelation zwischen Mindfulness und Neurotizismus. Das Beta ist etwas höher als in der Realität, der Korrelationskoeffizient ist aber eine Punktlandung. Ein Koeffizient um die r = +0,20 bis r = +0,25 ist auch das, was man in Datensätzen realer Umfagen findet.
Welche Schlüsse hätte man wohl gezogen, hätte man zuerst diesen Graph zu Mindfulness und Neurotizismus gesehen? Wenn man die Ergebnisse der kontrollierten Experimente nicht kennen würde? Der Scheinwiderspruch zeigt, dass die Interpretation von Daten aus Beobachtungsstudien eine wahnsinnig komplizierte Sache ist. Die Versuchung ist groß, in Korrelationen Ursache und Wirkung zu sehen. Hier etwa: Mindfulness hilft nicht. Oder noch schlimmer: Mindfulness ist schädlich. Jedoch können nur kontrollierte Experimente und Meta-Analysen dieser Experimente die Wahrheit offenbaren und bei Mindfulness sprechen sie eine klare Sprache, entgegen der bloßen Korrelation.
Im Bereich der Supplemente ist Omega-3 das am besten erforschte Mittel bezüglich antidepressiver Wirkung. Schon seit zwei Jahrzehnten werden kontrollierte Experimente (RCTs) damit durchgeführt und es gibt mehr als ein Dutzend Meta-Analysen dieser RCTs. Die größte Meta-Analyse ist diese. Sie umfasst eine stolze Anzahl von 35 RCTs mit knapp 11.000 Probanten (6700 in Behandlungsgruppen, 4300 in Placebogruppen). Ich wollte vor allem mal einen Blick auf Publikationsbias werfen, was mir auch die Möglichkeit gibt, mein eigenes Programm zur automatischen Ermittlung und Korrektur von Publikationsbias zu testen.
Zwei wichtige Punkte vorab:
Eine solide antidepressive Wirkung existiert. Dies gilt jedoch nur für depressive Probanten. Bei gesunden Probanten tut Omega-3 nichts.
Omega-3 Supplemente enthalten stets einen gewissen Anteil DHA und EPA. Die Meta-Analyse zeigt deutlich, dass die antidepressive Wirkung von EPA kommt. Das DHA hat keine solche Wirkung. Für eine antidepressive Wirkung sollte also anteilig soviel EPA wie möglich beim Supplement enthalten sein.
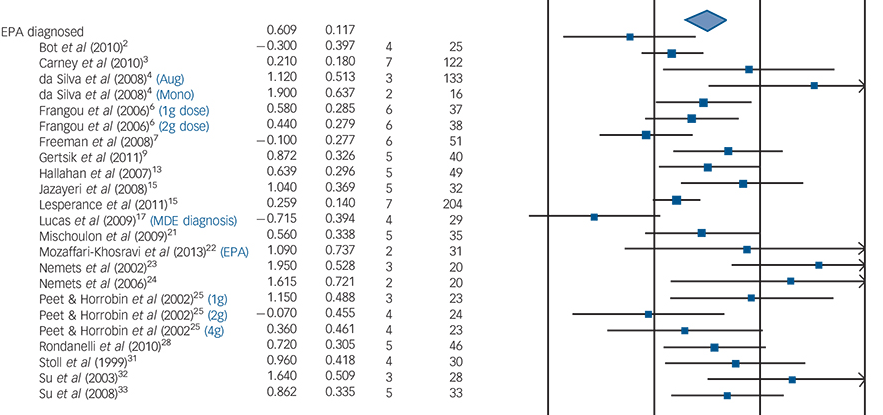
Es lohnt sich somit, die weitere Analyse auf die Subgruppe “EPA-reiches Supplement + depressive Probanten” zu beschränken. Die Meta-Analyse enthält nützlicherweise den Forest Plot für genau jene Subgruppe:
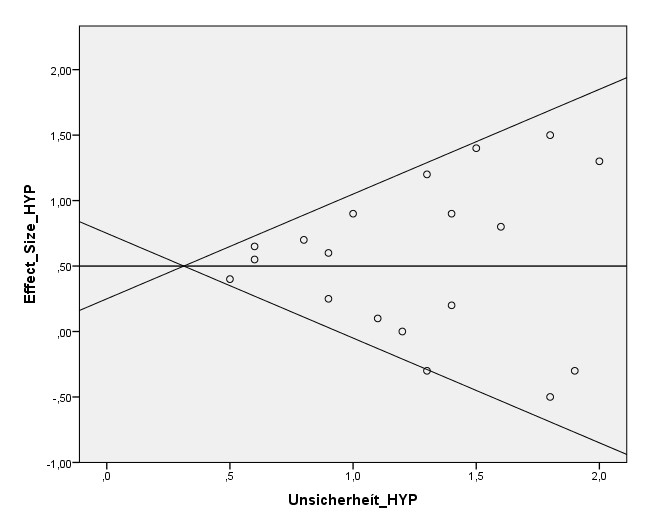
Sie stellt für diese Gruppe diese Effektstärke fest:
d = 0,61 [0,37 – 0,84]
Hier der Output aus meinem Programm, jedoch mit Ausschluss des Experiments, in dem Omega-3 als Zusatz zu einer anderen Behandlung gegeben wurde (da Silva et al 2008 Augmented). Man sieht daran, dass die Einschränkung auf diese Subgruppe eine Einschränkung auf circa 900 Probanten bringt und die durchschnittliche Anzahl Probanten pro RCT knapp 40 ist.
Der kleine Unterschied im Ergebnis liegt an der unterschiedlichen Berechnung von Tau² (siehe Hinweis unten). Interessant ist die Frage, ob Publikationsbias besteht und wenn ja, welcher Effekt nach Korrektur verbleibt. Die Autoren der Studie stellen fest, dass ein Publikationsbias bemerkbar ist und kommen mittels Trim-And-Fill auf:
d_korrigiert = 0,42 [0,18 – 0,65]
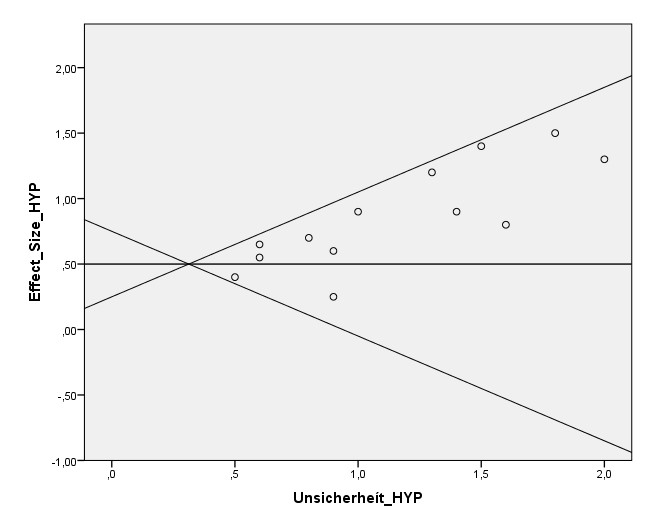
Ich halte das immer noch für überschätzt, da es a) zu hoch ist um plausibel zu sein, siehe z.B. Vergleich mit Effektstärken von CBT oder SSRI, und viel wichtiger b) nicht mit der Effektstärke übereinstimmt, zu denen die größten RCTs konvergieren. Rechnet man die Meta-Analyse unter Beschränkung auf die sechs größten RCTs nach, aus guten Gründen auch mit Verschiebung statt Neuberechnung des 95 % Konfidenzintervalls, dann bekommt man:
d_korrigiert = 0,33 [0,09 – 0,56] mit p < 0,01
Ich würde es mit Blick auf die beiden mit größten RCTs sogar noch etwas niedriger ansetzen, etwa bei d = 0,30. Wieso die Diskrepanz zu dem, was die Autoren angeben? Korrektur von Publikationsbias ist keine harte Wissenschaft. Trim-And-Fill findet den korrigierten Wert durch Eliminierung von Asymmetrie im Funnel Plot. Das ist ein guter Ansatz. Die obige Methode geht davon aus, dass je größer die RCTs, desto besser die Konvergenz zum echten Effekt. Auch das ist ein guter Ansatz. Im Idealfall kommt man damit auf das Gleiche, in der Realität wird die Übereinstimmung nie perfekt sein.
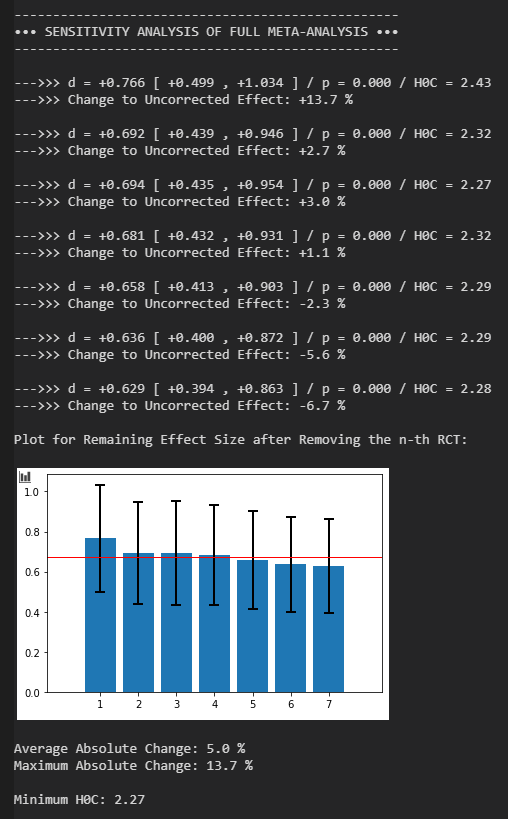
Ich traue eher dem zweiten Ansatz, da er unabhängig von sehr kleinen RCTs mit wenig statistischer Aussagekraft ist (Probantenzahlen < 30, in dieser Subgruppe 10 der 22 RCTs). Diese RCTs, welche man eher als Pilotprojekte betrachten sollte, sind nützlich in den ersten Phasen der Forschung. Ohne erfolgreiche Pilotprojekte findet sich in der Regel keine Finanzierung für größere RCTs. Sobald jedoch umfangreichere RCTs bestehen, ist die Inklusion der Pilotprojekte in Meta-Analysen eher fragwürdig. Vor allem da diese RCTs fast immer den Großteil des Publikationsbias ausmachen.
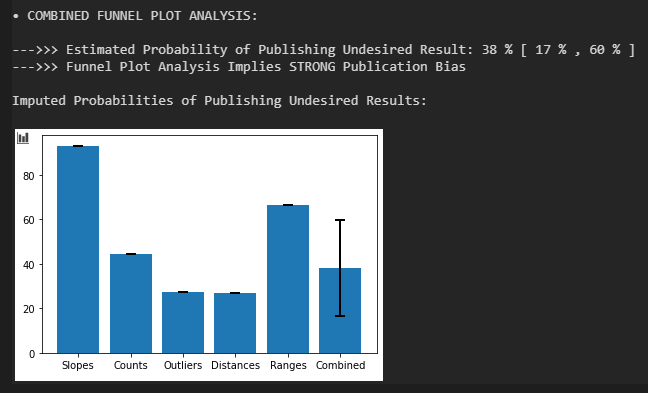
Das Programm stellt korrekterweise fest, dass der Einfluss des Publikationsbias auf die Effektstärke signifikant ist (mit p < 0,05) und auch die Sicherheit bei der Ablehnung der Nullhypothese etwas verändert, jedoch nicht auf kritische Weise. Es macht Sinn diese beiden Aspekte getrennt zu betrachten. Korrektur von Publikationsbias kann Effektstärken stark verändern, was aber nicht immer die Ablehnung der Nullhypothese berührt. Es kann auch nach Korrektur noch viel Luft zur Null bleiben. Alternativ kann bei einem schwachen Effekt schon eine kleine Veränderung der Effektstärke die Ablehnung der Nullhypothese gefährden.
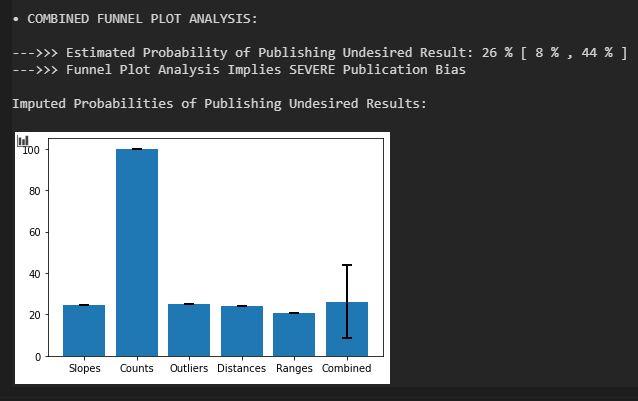
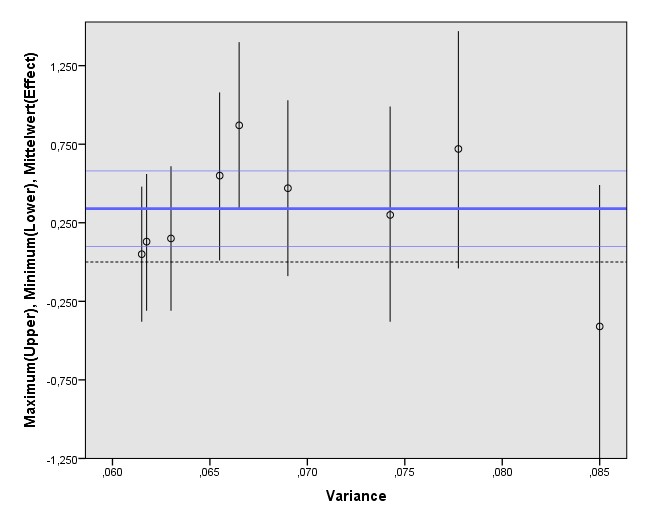
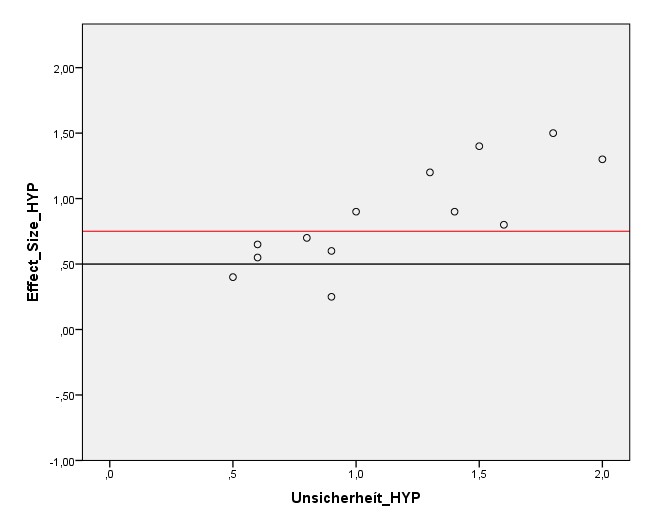
Eine Analyse der Asymmetrie des Funnel Plots bestätigt, was die Autoren erwähnen und der erste Teil der automatisierten Analyse gefunden hat. Und zeigt auch sehr schön, wieso eine Regression am Funnel Plot (z.B. Egger’s Test) nicht immer ausreichend ist, um Publikationsbias zu identifizieren. Zentriert man die Effektstärken der RCTs auf d_korrigiert = 0,33 und erzeugt dann das Standardfehler-Effektstärke-Diagramm, dann ergibt sich für die Linie durch die Effektstärken über 0 praktisch diesselbe Steigung wie für die Linie für Effektstärken unter 0. Dieser Test zeigt den Publikationsbias in diesem Fall also nicht.
Dass er trotzdem besteht, sieht man an anderen Möglichkeiten, Asymmetrien des Funnel Plots zu quantifizieren. Einmal über banales Zählen der RCTs (mehr RCTs über 0 als unter 0), Zählen der Ausreißer (mehr Ausreißer über 0 als unter Null), der Summe der Effekt-Distanzen zum korrigierten Effekt (höhere Summe über 0 als unter 0) und die Werte der maximalen Effekt-Distanzen (größer über 0 als unter 0). Insgesamt implizieren die Asymmetrien einen recht saftigen Publikationsbias und implizieren, dass nur knapp 40 % der unerwünschten RCT-Ausgänge publiziert werden.
Alles in Kurz:
Omega-3 Supplemente, sofern reich an EPA und verabreicht an depressive Probanten, zeigen eine gute antidepressive Wirkung, die auch einem strikten statistischen Härtetest standhält. Die Effektstärke sollte man, basierend auf dem Grundgedanken, dass die größten RCTs zur echten Effektstärke konvergieren, bei um die d = 0,30 Standardabweichungen oberhalb des Placebo-Effekts vermuten.
Hinweis: Es gibt verschiedene Anssätze um die Varianz zwischen Studien (Tau²) zu berechnen, siehe hier. Ich habe den “Two-Step Estimator” von Dersimonian / Laird benutzt, weil er sich recht direkt und ohne besonders viel Schmerz implementieren lässt. Je nach Wahl der Methode bekommt man jedoch ein leicht verschiedenes Tau² heraus. Tau² wird zur Varianz jedes Experiments hinzugerechnet. Man kann es sich gut vorstellen als “zusätzliches Rauschen”, welches eingeführt wird, um einer hohen Varianz (wenig Übereinstimmung) zwischen den Experimenten Rechnung zu tragen. Ist die Varianz sehr klein (hohe Übereinstimmung), dann ist Tau² = 0 und man spricht von einer Fixed-Effects Meta-Analyse. Bei Tau² > 0 von einer Random-Effects Meta-Analyse. Mit dem Tau² ändern sich die jeweiligen RCT Gewichte und die gewichtete Effektstärke verschiebt sich. So können leichte Unterschiede entstehen.
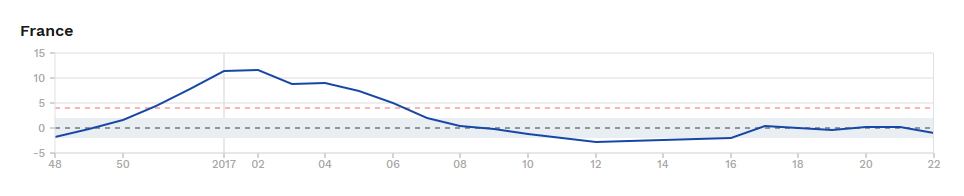
Wenn ich heute eine Million 80+ Jährige töten würde (hypothetisch natürlich), dann würde sich kurzfristig eine sehr hohe Übersterblichkeit zeigen und die Wochen / Monate danach eine verringerte Übersterblichkeit. Diese Reduktion nach einem kurzfristigen Peak nennt sich Harvesting Effekt und erklärt sich daraus, dass diese viele dieser Leute, die in diesen Wochen auf natürlichem Wege gestorben wären, nun schon vorzeitig verstorben sind und somit in den folgenden Wochen in der Mortalitätsstatistik “fehlen”. Wenn ich im Gegensatz dazu heute eine Million 30-50 Jährige töten würde, gäbe es ebenfalls eine kurzfristige Übersterblichkeit, jedoch ohne die darauffolgende Reduktion, da man erwarten darf, dass von diesen in den folgenden Wochen fast niemand auf natürlichem Wege verstorben wären. Hier würde sich also kein Harvesting Effekt zeigen. Dieser ergibt sich nur, wenn durch ein Ereignis plötzlich mehr jener Menschen sterben, die schon am Ende ihres Lebens stehen. Der Effekt zeigt sich z.B. manchmal nach besonders starken Grippe-Wellen, siehe hier in Frankreich nach der 2017 Grippe-Welle:
Gab es diesen Effekt auch nach der ersten Coronavirus-Welle? Eine Rechnung mit Sterbetafeln zeigt, dass im Mittel pro Todesfall etwa 10 Lebensjahre verloren gehen. Eventuell sind es auch weniger, im Bereich 5-7 Jahren, wenn man Vorerkrankungen berücksichtigt. Aber insgesamt scheint es wenig plausibel, dass viele jener Menschen, die am Coronavirus gestorben sind, nur Wochen oder Monate vor dem Ende ihres Lebens standen. Man würde basierend auf der Rechnung also keinen Harvesting Effekt erwarten. Die Mortalitätsstatistik bestätigt das. Für Gesamt-Europa während und nach der ersten Welle:
Sterblichkeit während der Welle: +270 Standardabweichung
Sterblichkeit danach: -6 Standardabweichungen
Harvesting Anteil: circa 2 %
Harvesting Effekt für bestimmte Länder:
Irland: 33 %
Schweiz: 31 %
Frankreich: 11 %
Belgien: 9 %
Spanien: 3 %
Italien: 0 %
Niederlande: 0 %
Schweden: 0 %
UK: 0 %
Nur in vereinzelten Ländern (Irland, Schweiz) zeigt sich ein deutlicher Harvesting Effekt. Das könnte daran liegen, dass hier Altenheime im Verhältnis zu anderen Infektionsorten überproportional hart betroffen waren. In den meisten Ländern kann man jedoch klar die Abwesenheit eines merklichen Harvesting Effekts feststellen. Die Daten zur Berechnung der obigen Anteile stammen allesamt von EUROMOMO. Es bleibt abzuwarten, ob das auch nach der zweiten Welle Gültigkeit behält.
Die Idee, depressiven Symptomen mit Licht entgegenzuwirken, ist nicht neu. Es gibt jedoch erst seit einigen Jahren genügend kontrollierte Experimente dazu, um fundiert beurteilen zu können, ob an dieser Idee wirklich etwas dran ist. Basierend auf allen Meta-Studien zu diesem Thema seit 2000 (siehe Liste am Ende des Eintrags), zeigen die Experimente in der Summe einen Effekt von d = 0,47. Das ist etwas weniger effektiv als Mindfulness oder Fitness, deren antidepressive Wirkung bei grob d = 0,55 liegt, aber der Unterschied ist nicht sonderlich groß. Weil Skepsis aber immer ein guter Leitfaden ist, wollte ich die größte Meta-Studie Tao et al. (2020) mal einem statistischen Härtetest unterziehen, vor allem in Hinblick auf Bias.
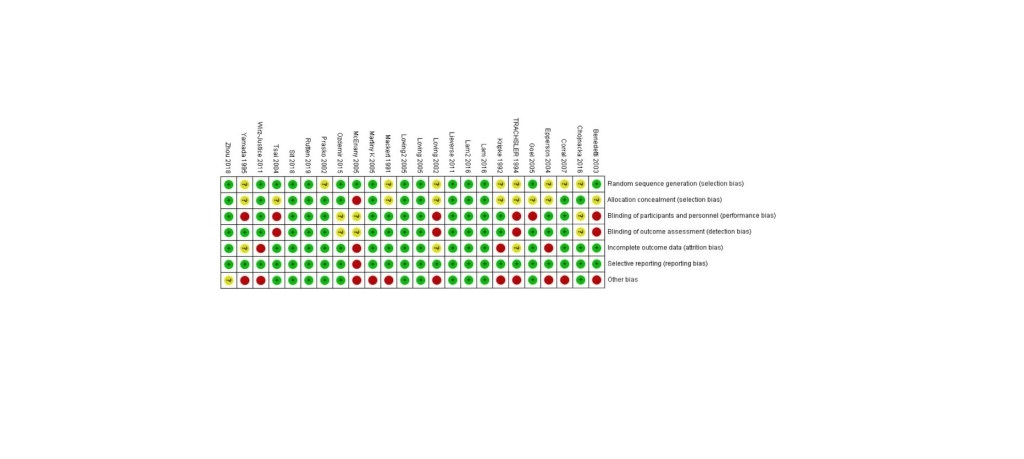
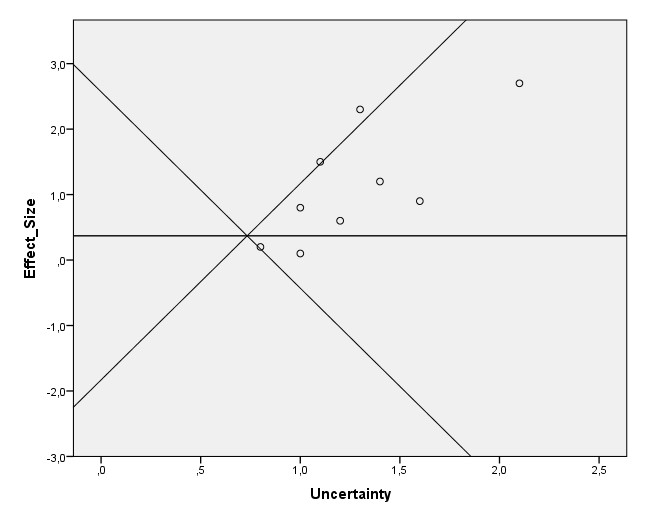
Tao et al. (2020) führt insgesamt 24 kontrollierte Experimente mit Lichtgeräten auf. Die mittlere Effektstärke beträgt d = 0,41 [0,21, 0,60]. Das stimmt gut mit anderen Meta-Studien zu dem Thema überein. Der Funnel-Plot zeigt, dass keine Verzerrung durch den Publikationsbias besteht. Sehr erfreulich, das schafft Vertrauen! Jedoch sieht man deutliche Unterschiede in der Qualität der Experimente. Nur 7 der 24 Experimente sind komplett frei von möglichem Bias, 2 weitere Experimente zeigen nur eine einzige Unsicherheit bei den verschiedenen Bias-Quellen.
Ich habe die Meta-Analyse neu berechnet unter ausschließlicher Verwendung dieser 9 Experimente. Die Effektstärken und Varianz habe ich dafür direkt der Meta-Studie entnommen und ich habe das gleiche Modell wie die Autoren verwendet (Random-Effects, hier ein guter Überblick). Wieder ergibt sich ein erfreuliches Ergebnis! Beschränkt man sich bei der Analyse auf die bias-freien Experimente, dann ändert sich die Effektstärke nur minimal und der Effekt bleibt statistisch signifikant:
d = 0,34 [0,10, 0,58] und p < 0,01
Der antidepressive Effekt von Licht ist also ziemlich robust. Eine Verzerrung durch Publikationsbias oder individuellem Bias lässt sich ausschließen. Die meisten Experimente der in Tao et al. (2020) aufgeführten Experimente nutzen eine Lichtstärke um die 10.000 Lux, was grob der Strahlungsleistung eines blauen Himmels und dem Zehnfachen der Strahlungsleistung eines grauen Himmels entspricht. Therapielampen mit solcher Strahlungsleistung sind z.B. auf Amazon gut erhältlich. Die Dauer der Anwendung betrug in den Experimenten zwischen 30-60 Minuten pro Tag. Eine Dose-Response-Beziehung, im Sinne von mehr hilft mehr, konnte nicht festgestellt werden, aber das liegt sehr wahrscheinlich an der relativ geringen Anzahl an Experimenten.
Zum Schluss wie versprochen die Liste der Meta-Analysen seit 2000:
Ein großes Projekt mit 100 sehr soliden Studien (Trennschärfe > 90 %) hat gezeigt, dass nur einer von drei Effekten in der Psychologie überhaupt reproduziert werden kann. Das ist ziemlich niederschmetternd für ein Feld, dass sich selbst als Wissenschaft versteht. Bevor man sich überlegt, woran das liegt, hilft es sich erstmal zu schauen, woran es NICHT liegen kann. Dazu gehört: Signifikanzniveau und Trennschärfe (Statistical Power).
Die Psychologie verwendet dasselbe Signifikanzniveau wie andere Felder, a = 0,05. Grob entspricht das der Wahrscheinlichkeit, dass ein nicht-existenter Effekt als signifikant festgestellt wird (Fehler 1. Art). Untersucht man 100 nicht-existente Effekte, würde man 5 fälschlicherweise als gültig einstufen. Die Trennschärfe sagt hingegen, wie wahrscheinlich es ist, einen existenten Effekt als signifikant einzustufen (Eins minus Fehler 2. Art). Also wie gut man existente Effekte als solche identifizieren kann. Empfohlen ist eine Trennschärfe von s = 0,80. Mit diesem Standard würde man bei der Untersuchung von 100 existenten Effekten 80 als gültig einstufen.
Effekt …
existiert nicht
existiert
als gültig festgestellt
a
s
nicht als gültig festgestellt
1-a
1-s
Aus diesen beiden Größen lässt sich leicht berechnen, wie wahrscheinlich es ist, dass ein als gültig eingestufter Effekt auch tatsächlich existiert. Das entspricht der prinzipiellen Replizierbarkeit. Also der Replikationsrate, die man mit Replikationsstudien sehr hoher Güte finden würde. Für a = 0,05 und s = 0,80 bekommt man:
Anmerkungen dazu siehe * / **. Bei diesem Standard ergibt sich also eine sehr hohe Replizierbarkeit. 94 % der Effekte, die man als gültig einstuft, gibt es wirklich. Als Grund für die Replikationskrise in der Psychologie wird oft die mangelnde Trennschärfe genannt. Es stimmt auch tatsächlich, dass psychologische Studien im Mittel eher bei einer Trennschärfe von s = 0,50 statt der empfohlenen s = 0,80 liegen. Aber: Das ist nicht der Grund für die miese Replizierbarkeit. Auch mit dieser geringen Trennschärfe ergibt sich eine Replizierbarkeit weit über den ziemlich mageren 33 % des Reproducibility Projects:
Signifikanzniveau und Trennschärfen passen also. Was ist es dann? Vielleicht der Publikationsbias? Wenn, dann müsste dieser sehr stark ausgeprägt sein. Nimmt man an, dass alle nicht-existenten Effekte, welche signifikant festgestellt wurden, veröffentlicht werden, und nur mit einer Wahrscheinlichkeit q veröffentlicht werden, wenn diese nicht-signifikant festgestellt wurden (also der Wahrheit entsprechend), dann gilt:
Wie sieht es bei saftigem Publikationsbias aus? Wenn etwa 75 % aller nicht-signifikanten Ergebnisse in der Schublade verschwinden? Dann wäre q = 0,25 und:
Klare Steigerung, aber die Mehrheit der Studien zu diesem nicht-existenten Effekt würde trotzdem die Nullhypothese behalten und fast alle Meta-Studien würden zum korrekten Ergebnis kommen. Richtig kritisch wird es erst, wenn 95 % aller nicht-signifikanten Ergebnisse in der Schublade verschwinden (q = 0,05):
Ab hier wird es schwer bis unmöglich einen nicht-existenten Effekt als solchen zu identifizieren. Im Prinzip ein Münzwurf und die Replizierbarkeit des gesamten Feldes würde großen Schaden nehmen. Der Publikationsbias müsste also enorm ausgeprägt sein, um einen merklichen Effekt auf die Replizierbarkeit zu haben. Ist ein solches Ausmaß überhaupt realistisch? Könnte sein. In psychologischen Journalen überwiegen signifikante Effekte bei weitem, nicht-signifikante Effekte sind notorisch schwer zu publizieren.
Es ist leicht einzusehen, dass der Publikationsbias bei der Replikationskrise eine Rolle spielt, aber mir fällt es schwer zu glauben, dass es DER Hauptgrund ist. Es ist sicherlich ein Grund. Aber: Publikationsbias ist in der Praxis leicht zu identifizieren und korrigieren. Jede Meta-Studie kann Publikationsbias mittels dem Egger’s Test finden und anschließend mittels Trim-And-Fill korrigieren. Es ist ein recht simples und intuitives statistisches Verfahren. Wäre der Publikationsbias der Hauptgrund, wäre man dem nicht nur schnell auf die Schliche gekommen, sondern hätte ihn auch leicht bereinigen können. Es muss noch andere Gründe geben.
Bei diesen anderen Gründen wird oft auf unlautere statistische Methoden verwiesen. Hier Tipps, wie man Signifikanz für Effekte bekommt, die gar nicht existieren. Leider so oft angewandt in der Psychologie.
Multiple Hypothesen gleichzeitig untersuchen oder, noch besser, ohne Hypothesen das komplette Datenset abgrasen = Fischen nach Effekten ***
Datensammlung einstellen, sobald die gewünschte Signifikanz auftaucht
Datenset einfach komplett erfinden
Woran es auch liegen mag. Wichtig ist die Replikationskrise nicht nur aus statistisch-wissenschaftlicher Perspektive zu sehen. Es ist kein Kavaliersdelikt, kein Verbrechen ohne Opfer. Opfer sind psychisch kranke Menschen, die sich auf die Arbeit der Forscher stützen müssen. Arbeit, die sich leider nur in einem von drei Fällen überhaupt replizieren lässt. Inakzeptabel aus wissenschaftlicher Perspektive, aus menschlicher Perspektive aber eine wahre Katastrophe.
Glücklicherweise haben viele Journale reagiert. Experimente werden jetzt vorregistriert und nach Durchführung veröffentlicht, unabhängig von der Signifikanz des Ergebnisses. So wird dem Publikationsbias keinen Raum gegeben. Da die Registrierung auch Sample Size enthält, entfällt der Trick mit verfrühter Einstellung der Datensammlung. Und die zu testenden Hypothesen sind dort auch schon aufgeführt, was dem Fischen nach Effekten einen Strich durch die Rechnung macht. Von der Vorregistrierung darf man also eine massive Besserung erwarten.
* Genauer müsste man hier auch als Variable anfügen, wie groß der Anteil q an existenten Effekten an der Gesamtzahl der gestesteten Effekten ist. Die Rechnung, so wie sie hier gemacht ist, nimmt 50/50 an. Wer andere Szenarien testen möchte, kann P(Effekt existiert gegeben Effekt festgestellt) = q*s/(q*s+(1-q)*a) verwenden.
** Die tatsächliche Replikationsrate ist etwas geringer als die prinzipielle Replizierbarkeit, da keine Replikationsstudie perfekt ist, jede ein von Null verschiedenes Signifikanzniveau und eine von 1,0 verschiedene Trennschärfe hat. Die Replikationsrate liegt bei etwa (Trennschärfe von Replikationsstudie)*(Replizierbarkeit). Bei Replikationsstudien mit hoher Trennschärfe darf man den Unterschied jedoch ignorieren.
** So eine Herangehensweise lässt sich auch ordentlich machen, sie ist nicht prinzipiell problematisch, jedoch benötigt sie a) Erwähnung aller gemachten Tests und b) Korrektur des Signifikanzniveaus gemäß den Anzahl Tests
Schaut man sich die Meta-Analyse zur antidepressiven Wirkung von L-Carnitin an, so sieht man einen ziemlich deutlichen Publikationsbias. Die Meta-Studie geht darauf kaum ein und ist somit nicht die Bytes wert, auf der sie gedruckt ist. Es ist klar zu erkennen, dass die Forscher hier auf ein spektakuläres Ergebnis und Prestige aus sind. Die Wahrheitsfindung musste sich hinten anstellen. Was sehr schade ist, da eine konservative Neuberechnung durchaus für L-Carnitin spricht.
Was heißt konservative Berechnung?
Nur die größten RCTs in die Analyse aufnehmen
Ausreißer nach oben entfernen
Mittels Trim-And-Fill Methode den Publikationsbias ausgleichen
Ich habe die Meta-Analyse nochmal durchgeführt mit folgenden Änderungen:
Alle Studien mit einer Varianz größer als 0,1 entfernt, so dass nur verlässliche RCTs bleiben. Es bleiben so vier RCTs übrig.
Es gab einen RCT, den man als schwacher Ausreißer nach oben einstufen könnte. Ein Grenzfall. In der ersten Berechnung haben ich ihn belassen, in einer zweiten Berechnung die dort gefundene Effektstärke dreist halbiert
Gemäß Trim-And-Fill habe ich ein RCT unter dem Mittel hinzugefügt
Das ist alles sehr konservativ, aber zumindest bekommt man so ein Ergebnis, bei dem keine Gefahr besteht, dass die gewichtete Effektstärke von kleinen Studien oder dem Publikationsbias verzerrt wird. Das Ergebnis, berechnet nach dem Random-Effects-Models (ebenso eine konservativere Wahl als das Fixed-Effects-Model), ist ernüchternder als das spektakuläre Ergebnis der Autoren, aber definitiv realistischer und verlässlicher.
Ohne Anpassung des potentiellen Ausreißers:
d = 0,35 [0,12, 0,58] und p < 0,01
Mit Anpassung des potentiellen Ausreißers:
d = 0,27 [0,04, 0,50] und p < 0,05
Die antidepressive Wirkung bleibt also auch unter Verwendung höherer Standards signifikant und wäre demnach im Bereich von Omega-3 (d = 0,34, nach Bias-Korrektur d = 0,26) und probiotischen Supplements (d = 0,28, nach Bias-Korrektur d = 0,21). Dieses Ergebnis sollte optimistisch stimmen und es ist auch jenes Ergebnis, das im Abstrakt stehen sollte.
Wieso steht das nicht dort? Die Wissenschaft bietet leider verquere Anreize. Die meisten Journale, nicht nur die kleinen Nischenjournale, sondern explizit auch die größten Journale eines Feldes, veröffentlichen praktisch nie insignifikante Ergebnisse. Und unter den signifikanten Ergebnissen werden vor allem jene bevorzugt, die eine besonders hohe Effektstärke zeigen. Wer sich einen Namen machen will, braucht laute Ergebnisse. d = 1,10 klingt bombastisch. d = 0,27 ist ehrlich, lässt aber keine Herzen höher schlagen.
Wer mir nicht glauben will, dass das Problem so dramatisch ist, wie hier dargestellt, dem sei das Reproducibility Project ans Herz gelegt. Natürlich ist es nicht nur Publikationsbias, sondern auch unehrliche statistische Methoden (P-Hacking, Fischen nach Effekten, Vorzeitige Einstellung der Datensammlung, liberaler Umgang mit unbequemen Ausreißern). Aber am Ende bleibt ein Feld, bei dem sich nur einer von drei Effekten überhaupt reproduzieren lässt. Ein niederschmetterndes Fazit für ein Feld, das sich gerne selbst als Wissenschaft bezeichnet.
Die verlinkte Meta-Studie ist absolut keine Ausnahme. Viele Meta-Studien arbeiten den Publikationsbias mechanisch ab, weisen darauf hin, geben aber keine Einschätzung der Tragweite und produzieren keinen Funnel-Plot. Viele andere Meta-Studien bieten eine ordentliche Analyse dazu und liefern auch ein korrigiertes Mittel, aber dieser wird nie im Abstrakt berichtet. Im Abstrakt bleibt das unkorrigierte Mittel, welches dann von anderen zitiert und in der Praxis oft ungeprüft übernommen wird.
Wer eine Meta-Studie liest, dem sei folgendes ans Herzen gelegt:
Nie dem Abstrakt trauen
Den ersten Blick immer auf den Abschnitt über Bias
Was dort zu sehen sein soll: ein korrigiertes Mittel und ein Funnel-Plot. Dieses korrigierte Mittel ist die tatsächliche Effektstärke, nicht das, was im Abstrakt steht
Kein korrigiertes Mittel vorhanden? Die gefundene Effektstärke gedanklich durch drei teilen. Die tatsächliche Effektstärke dürfte wohl dort irgendwo liegen
Meta-Regressionen laufen leider i.d.R. nach dem Prinzip “Fischen nach Effekten” (1) und das auf Basis weniger Datenpunkte. Nur begrenzt Glauben schenken
Aus Gründen der Transparenz, hier zum Nachrechnen meines Ergebnisses. Die vier RCTs, der Meta-Studie entnommen, und der mittels Trim-And-Fill hinzugefügte RCT*. Erwähnt ist die Effektstärke, Varianz und Random-Effects-Varianz.
(1) Das sieht man sogar oft ganz wundervoll an der Formulierung der Vorgehensweise bei den Meta-Regressionen: “We tested whether X”, “We then testet if Y”, ” We also looked at whether Z”, etc … Klassisches Fischen nach Effekten. Die korrekte Herangehensweise wäre: Vor den Meta-Regressionen Hypothesen formulieren (z.B. Dose-Response) und nur diese testen. Es ist bizarr, dass Fischen nach Effekten in der Regel verpöhnt ist, bei den Meta-Regressionen jedoch ganz offen betrieben wird.
Ich bin etwas enttäuscht. Vor ein paar Monaten hatte ich diese Meta-Studie entdeckt und habe daraufhin angefangen L-Carnitin zu nehmen. Die Studie stellt basierend auf einer vernünftigen Datenlage (neun kontrollierte Experimente mit > 400 Probanten) eine starke antidepressive Wirkung von L-Carnitin fest. Zu stark, wenn man es in bekannte Effektstärken einordnet, das macht schon stutzig. Therapien wie CBT und MBT schaffen eine Reduktion depressiver Symptome um d = 0,5 bis d = 0,7. Mittel der Nahrungsergänzung mit gesicherter antidpressiver Wirkung und exzellenter Datenlage (Omega-3, Probiotisch) schaffen um die d = 0,2 bis d = 0,3. Laut der Meta-Studie bringt L-Carnitin eine Reduktion von d = 1,1. Das wäre deutlich effektiver als jede Therapie und jede andere Nahrungsergänzung. Unrealistisch hoch. Und schaut man sich die Daten genauer an, sieht man auch schnell, woher dieses Resultat kommt. Wie so oft ist der Täter Publikationsbias. Experimente mit Nullresultat oder gar negativem Resultat zu der antidepressiven Wirkung von L-Carnitin sind systematisch in den Schubladen der Forscher verschwunden. Das ist ein schwerer Vorwurf, lässt sich aber überraschend leicht zeigen.
Wie findet man Publikationsbias? Es klingt zuerst nach einer unlösbaren Aufgabe. Woher soll man wissen, welche Studien nicht veröffentlicht wurden? Sie stehen in keinem Journal, die Ergebnisse lassen sich nirgendwo nachlesen. Mit etwas Glück findet man eine Registrierung der Studie ohne folgende Veröffentlichung und kann direkt bei den Forschern anfragen. Das ist viel Aufwand und es gibt keine Garantie, dass sich eine solche Registrierung finden lässt. Trotzdem hinterlässt die Abwesenheit diese Studien sehr klare Spuren.
Man kann (und sollte) alle gefundenen Experimente zu einem Thema in einem Unsicherheits-Effektstärke-Diagramm eintragen. Jedes Experiment endet mit einer Effektstärke und einer Unsicherheit, die sich aus der Studiengröße ergibt. Je mehr Probanten das Experiment enthält, desto kleiner die Unsicherheit der gefundenen Effektstärke. So sieht das resultierende Diagramm typischerweise aus, wenn die Forscher alle Experimente zu einem Thema veröffentlichen, unabhängig davon, ob das Resultat positiv, neutral oder negativ war. Das ist ein sogenannter Funnel-Plot, hier über eine Simulation produziert.
Was man darauf sieht, ist sehr logisch und einfach. Kleine Studien mit hoher Unsicherheit (Punkte rechts) weichen oft stark von der tatsächlichen Effektstärke ab. Statt der echten Effektstärke von d = 0,5 finden sie Werte von -0,5 bis 1,5. Das ist normal. Je größer aber die Studien (und somit je kleiner die Unsicherheit), desto mehr konvergieren die gefunden Effektstärken gegen die reale Effektstärke. Sehr große Studien mit sehr kleiner Unsicherheit (Punkte links) liegen entsprechend allesamt recht nah an dem Wert d = 0,5. Ohne Publikationsbias sieht man eine recht symmetrische Streuung um diese reale Effektstärke. Viele liegen darüber, viele darunter, aber es hebt sich grob auf. Und so kommt man bei der Bildung des Mittelwerts über alle Studien auch gut zu der realen Effektstärke. Kein Problem. Manchmal (leider recht oft) sieht es aber so aus:
Betrachtet man nur die größten Studien links, würde man wieder einen Mittelwert um die d = 0,5 vermuten. Die Streuung nach unten fehlt jetzt aber. Kleinere Studien weichen wie gewohnt stärker von diesem Mittelwert ab, aber zu den Studien mit stark positiven Ergebnissen (das bringt Prestige) gibt es keine Gegenstücke (das bringt kein Prestige). Forscher und Journale veröffentlichen lieber ein Ergebnis “Beeindruckender Effekt gefunden” als “Hier gibt es nichts zu sehen”. Das Problem daran ist, dass der Mittelwert über alle Studien nun stark von dem realen Effekt abweicht. Statt d = 0,5 berichtet die Meta-Studie d = 0,8.
Die gute Nachricht ist, wie man an den Graphen erkennen kann, dass es sehr einfach ist zu sehen, ob Studien verschwunden sind, selbst wenn man die einzelnen Studien nie finden könnte. Größere Studien konvergieren IMMER zur realen Effektstärke, kleinere Studien streuen IMMER weit davon und somit ergibt sich ohne Publikationsbias IMMER eine gefüllte Trichterform. Fehlt etwas unter jenem Mittelwert, den man durch die größten Studien vermutet, sind definitiv Studien in der Schublade gelandet. Ein schneller und schmerzfreier Ansatz zum Testen auf Publikationsbias ist also: Mittelwert aus den größten Studien berechnen, Linien anlegen, Kopf einschalten.
Ich habe aus der Meta-Studie zu L-Carnitin alle Effektstärken und Unsicherheiten rausgeschrieben und in SPSS eingetippt. Aus den größten drei Studien ergibt sich eine mittlere Effektstärke von d = 0,37. Weit unter dem Mittel über alle Studien von d = 1,1. Diesen Mittelwert habe ich einzeichnen lassen und dann auf Sicht die Trichtergrenzen angelegt (diese sind nicht super-wichtig, machen die visuelle Interpretation aber einfacher). So sieht es aus:
Ein Ergebnis wie aus einem Lehrbuch zu Publikationsbias. Man erkennt, dass die größten Studien zu einem geminsamen Mittelwert konvergieren, so wie es sein sollte. Die kleineren Studien liegen hingegen systematisch ÜBER dem Mittelwert der größten Studien. Es ist also nicht überraschend, dass wenn man naiv den Mittelwert über alle gefundenen Studien bildet (nach dem Fixed-Effects-Model), man ein spektakuläres Ergebnis wie d = 1,1 erhält. Dieser optimistische Wert lässt sich aber überhaupt nicht vereinen mit den Ergebnissen der größten Studien sowie dem Fakt, dass diese Studien recht gut zu einem kleineren Wert konvergieren. Die Effektstärke d = 1,1 ist schlicht eine Inflation, eine Folge davon, dass viele Studien mit Nullresultat oder negativem Resultat in den Schubladen verschwunden sind und somit in der Analyse fehlen. Gemäß den größten Studien liegt der reale Effekt irgendwo zwischen d = 0,0 und 0,6, also irgendwo zwischen “kein Effekt” und “moderater Effekt”.
Es könnte durchaus ein Effekt übrig bleiben, sogar einer, der sich im Vergleich zu der Wirkung von Therapien und anderer Ergänzungsmittel gut sehen lassen kann. Es lohnt sich, L-Carnitin weiter auf dem Radar zu haben, vor allem da die vermutete antidepressive Wirkung nur ein Teil der gesamten positiven Wirkung des Stoffes ist. Aber nach Berücksichtigung des Publikationsbias lautet das Ergebnis der Experimente: Antidepressive Wirkung unklar, mehr Daten benötigt. Das ist ein gutes Stück entfernt von “besser als alles bekannte”, daher die Enttäuschung.
Es hat sich hier definitiv gelohnt, den Kopf einzuschalten. Die naive Berechnung nach dem Fixed-Effects-Model, eine Methode zur Zusammenfassung von vielen Effektstärken und Unsicherheiten zu einem gemeinsamen gewichteten Mittelwert und einem gemeinsamen Unsicherheitsintervall, funktioniert ganz wundervoll, wenn man eine Trichterform vorliegen hat. Ist das nicht gegeben, müssen immer die größten Experimente als Orientierung dienen und das berechnete gewichtete Mittel mittels der Trim-And-Fill-Methode korrigiert werden.
Jede Meta-Studie produziert den Funnel-Plot und stellt, wenn nötig, Publikationsbias fest. Das gehört zum guten Ton. Aber nicht immer wird ein korrigiertes Mittel angegeben und noch seltener (eigentlich nie), wird statt dem naiven Mittel das korrigierte Mittel im Abstract angegeben. Das ist ein großes Problem, denn sofern man nicht besonderes Interesse an einem Thema hat, belässt man es i.d.R. beim Lesen des Abstracts und traut den berichteten Werten. Wie man oben sieht, kann man stark daneben liegen, wenn man den Wert aus dem Abstract ungeprüft übernimmt. In Meta-Studien sollte der erste Blick immer zum Funnel-Plot und korrigierten Mittel wandern. Dort sieht man das, was dem realen Mittel am nächsten kommt.
Ich hatte schon mal über das Thema geschrieben, aber wollte es doch noch genauer wissen und habe deshalb die Suche systematischer und nachprüfbarer gestaltet. Es folgt eine Übersicht über alle Meta-Studien zu Nahrungsergänzungsmittel, denen eine antidepressive Wirkung nachgesagt wird.
Erstmal sehr knapp und auf einen Blick:
Nahrungsergänzungsmittel
Effektstärke
Studienumfang
Datenqualität
Omega-3
d = 0,34
235 RCTs / 7900 Probanten
Sehr gut
Probiotisch
d = 0,28
82 RCTs / 2300 Probanten
Sehr gut
Kurkuma
d = 0,49
26 RCTs / 800 Probanten
Mäßig
Safran
d = 1,03
43 RCTs / 1600 Probanten
Schlecht
L-Carnitin
d = 1,10
12 RCTs / 800 Probanten
Schlecht
Zur Einordnung der Effektstärken: CBT bringt eine Reduktion depressiver Symptome von d = 0,70 (basierend auf 9000 Probanten), Mindfulness-Interventionen bringen d = 0,52 (basierend auf 5300 Probanten) und Fitness-Interventionen d = 0,58 (basierend auf 4200 Probanten).
Sehr gut empirisch gesichert ist demnach die antidepressive Wirkung von Omega-3 (sofern die Formulierung EPA-reich ist und die Dosis hoch) und probiotischer Mittel. Die Effektstärke liegt zwar ein gutes Stück unter dem Gold-Standard, kann sich aber trotzdem gut sehen lassen, vor allem vor dem Hintergrund der Verfügbarkeit und einfachen Implementation. Kurkuma zeigt eine etwas höhere Effektstärke, jedoch ist die Datenlage noch relativ überschaubar und es findet sich ein mäßig-starker Publikationsbias. Man darf die antidepressive Wirkung als gesichert ansehen, sollte aber die Effektstärke mit Vorsicht genießen. Vermutlich wird die tatsächliche Effektstärke auch in der Umgebung von Omega-3 und probiotischen Mitteln liegen.
Noch mehr Vorsicht sollte man bei Safran und L-Carnitin walten lassen. Die Effektstärken sind unrealistisch hoch und die Meta-Studien zeigen sehr umfassende Hinweise auf Publikationsbias. Bei Safran kommt hinzu, dass die meisten der RCTs aus einem einzelnen iranischen Institut kommen. Jedoch bleibt bei beiden Mitteln nach Bias-Korrektur mittels der Trim-And-Fill Methode ein signifikanter Effekt übrig. Ein Versuch ist es also allemal Wert.
Hier alle Meta-Studien zu Omega-3 inklusive Link. Der Mittelwert ist gewichtet nach der Wurzel der Probantenzahl (und somit proportional zum vermuteteten Standardfehler). Subgruppenanalysen zeigen desöfteren, dass für eine antidepressive Wirkung das Mittel anteilig sehr viel EPA enthalten muss und hochdosiert sein soll. Ist das gegeben, kann man von Effektstärken gut über dem gewichteten Mittel von d = 0,34 ausgehen.
Hier die Studien zu probiotischen Mitteln. Subgruppenanalysen zeigen, dass der Effekt für depressive Probanten stärker ist. Bei depressiven Probanten ergeben sich Effektstärken weit über dem Mittel von d = 0,28. Hinweise auf Publikationsbias findet keine der Meta-Studien, zumindest keine, bei der die Analyse zugänglich war.
Weiter mit Safran. Die größte Studie enthält Hinweise auf massiven Publikationsbias. Man sollte davon ausgehen, dass viele Safran-Studien mit negativem Ergebnis in den Schubladen verschwunden sind. Entsprechend bleibt unklar, wie es um die antidepressive Wirkung von Safran tatsächlich steht.
Und last but not least L-Carnitin. Hier gibt es bisher nur eine Meta-Studie zur antidepressiven Wirkung und diese enthält Hinweise auf einen mäßigen Publikationsbias. Leider auch eine unklare Lage.
Was die Dosierung angeht sollte man am besten einen Blick darauf werfen, wie das Mittel in den RCTs dosiert wurde. Das ein oder andere lässt sich (zumindest kurzfristig) mit mehr “Wumms” einsetzen als die oftmals recht konservativen Angaben der Hersteller hergeben. Als wirkliche Alternative zu einem SSRI kann wohl keines dieser Mittel dienen, jedoch ist etwas besser als nichts.
Die wichtigste und empirisch am besten gesichterte Erkenntnis der Traumforschung der letzten 50 Jahre ist die Kontinuitätshypothese: Träume sind eine Inszenierung der Ideen, Sorgen und Interessen des Wachlebens. Diese Hypothese ist im Prinzip das Newtonsche Gesetz der Traumforschung. Sie wurde vielfach experimentell getestet und hat, im Gegensatz zu den anekdotischen Thesen von Freud und Jung, der akribischen Prüfung standgehalten. Auch einem Test an einem Datensatz mit n = 524 Teilnehmern aus dem Harvard Dataverse hält sie erstaunlich gut stand.
Sorgen des Wachlebens ergeben sich zu einem großen Teil aus unerfüllten Bedürfnissen, welche man, säuberlich kategorisiert und der Wichtigkeit nach gestuft, der Maslowschen Bedürfnispyramide entnehmen kann. Eine Regression zeigt, dass der wichtigste Faktor beim Träumen soziale Bedürfnisse (gemäß Maslow) sind. Unter jenen, die sich häufig Sorgen über die Erfüllung ihrer sozialen Bedürfnisse machen, berichten etwa 80 % von fast täglichen, intensiven Träumen. Unter jenen, die solche Sorgen nicht haben, sind es nur knapp 20 %. Der Effekt ist sehr stark, mit einem standardisierten Regressionskoeffizienten ß = 0,36 und p < 0,001. Soziale Sorgen erhöhen die Wahrscheinlichkeit für intensives Träumen um den Faktor Vier.
An zweiter Stelle stehen Sorgen um Sicherheitsbedürfnisse. 70 % der Leute, die sich um ihre Sicherheitsbedürfnisse sorgen, erleben tägliche, intensive Träume. Unter jenen, bei denen diese Bedürfnisse in solcher Weise erfüllt sind, dass sich Sorgen erübrigen, sind es nur 20 %. Wieder ein starker Effekt mit ß = 0,20 und p < 0,001.
Nicht überraschend ist der Zusammenhang mit dem Persönlichkeitsmerkmal Offenheit / Intellekt, wobei dieser nicht die Kontinuitätshypothese berührt. Offene Menschen sind u.a. charakterisiert durch viel Kreativität und Vorstellungskraft. Dies übersetzt sich auch in intensivere Träume. Unter jenen, die den höchsten Score auf der Skala erzielen, berichten 55 % von täglichen, intensiven Träumen. Am unteren Ende der Skala sind es nur 15 %. Ein moderater Effekt mit ß = 0,17 und p < 0,001.
Daneben spielt auch der Konsum psychoaktiver Substanzen eine Rolle, ß = 0,20 und p < 0,001. Streng genommen wurde in der Umfrage bezüglich psychoaktiver Stoffe nur nach Alkohol, Cannabis und Antidepressiva gefragt, wobei jedes davon einen ähnlich großen traumförderlichen Effekt zeigt. Man darf aber vermuten, dass dies auch für andere deutlich psychoaktive Stoffe gilt. Für wenig psychoaktive Stoffe wie Koffein oder Nikotin zeigt sich kein Einfluss auf das Träumen.
Die Ergebnisse zeigen sehr deutlich, wie die Sorgen des Wachlebens, vor allem jene um die Erfüllung der Bedürfnisse gemäß Maslow, das Träumen antreiben. Eine gute Interpretation eines Traumes a) stellt diese Verbindung her und b) zieht Lehren daraus. Von einer Diskontinuität des Denkens beim Einschlafen sollte man nicht ausgehen. Man beschäftigt sich weiter mit jenen Themen, mit denen man sich auch im Laufe der Tage beschäftigt, jedoch in einer anderen Sprache. Der ungewohnte (symbolische) Ansatz des Weiterdenkens ist womöglich nur ein Folge davon, dass bestimmte Areale des Gehirns, vor allem jene, die Logik und Grammatik berühren, im Schlaf ausgeschaltet sind. So bleibt nur die Sprache symbolischer Bilder und Töne.
Es gibt noch einen wichtigen Punkt anzufügen: Es gibt keine positiven oder negativen Träumer. Die Korrelation zwischen Träumen und Alpträumen ist sehr eng. Man kann nicht viel träumen ohne Alpträume. Und wer fast nie Alpträume hat, der träumt auch nicht viel. Diese Erkenntnis aus dem Datensatz deckt sich mit dem Ergebnis der Traumforschung, dass sich positive und negative Emotionen in Träumen im Großen und Ganzen aufwiegen. Und Träume somit auch eine emotionsregulierende Funktion erfüllen.
P.S. Menschen, die angeben den Tag über sehr beschäftigt zu sein, scheinen auch etwas intensiver zu träumen. Der Effekt ist gut signifikant, jedoch relativ schwach (ß = 0,10 und p < 0,01). Fraglich, ob sich das replizieren ließe.